TL;DR
STARFlow-V is the first normalizing flow-based causal video generator demonstrating that normalizing flows can match video diffusion models in visual quality while offering end-to-end training, exact likelihood estimation, and native multi-task support across T2V/I2V/V2V generation.
Abstract
Normalizing flows (NFs) are end-to-end likelihood-based generative models for continuous data, and have recently regained attention with encouraging progress on image generation. Yet in the video generation domain, where spatiotemporal complexity and computational cost are substantially higher, state-of-the-art systems almost exclusively rely on diffusion-based models. In this work, we revisit this design space by presenting STARFlow-V, a normalizing flow-based video generator with substantial benefits such as end-to-end learning, robust causal prediction, and native likelihood estimation. Building upon the recently proposed STARFlow, STARFlow-V operates in the spatiotemporal latent space with a global-local architecture which restricts causal dependencies to a global latent space while preserving rich local within-frame interactions. This eases error accumulation over time, a common pitfall of standard autoregressive diffusion model generation. Additionally, we propose flow-score matching, which equips the model with a light-weight causal denoiser to improve the video generation consistency in an autoregressive fashion. To improve the sampling efficiency, STARFlow-V employs a video-aware Jacobi iteration scheme that recasts inner updates as parallelizable iterations without breaking causality. Thanks to the invertible structure, the same model can natively support text-to-video, image-to-video as well as video-to-video generation tasks. Empirically, STARFlow-V achieves strong visual fidelity and temporal consistency with practical sampling throughput relative to diffusion-based baselines. These results present the first evidence, to our knowledge, that NFs are capable of high-quality autoregressive video generation, establishing them as a promising research direction for building world models.
Method Pipeline
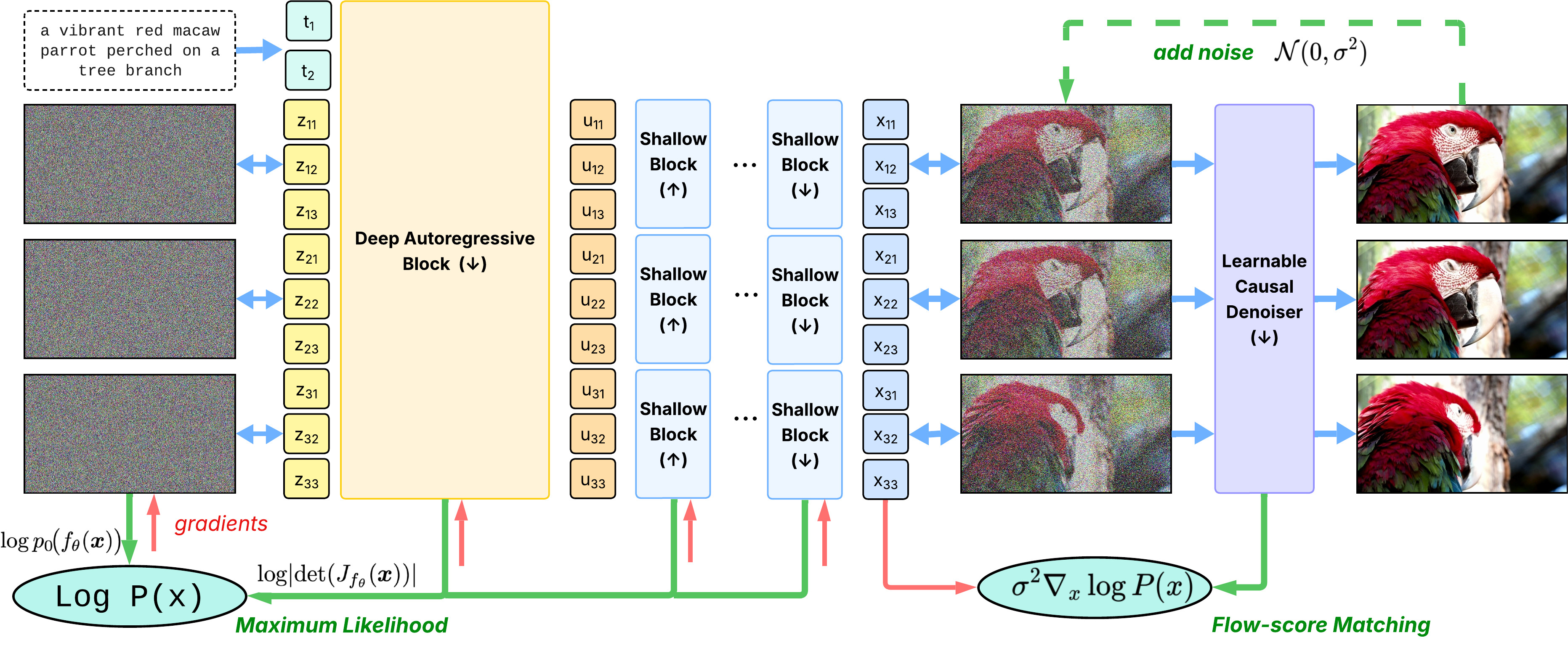
Figure: STARFlow-V pipeline. The model processes text prompts and noise through a Deep Autoregressive Block (global temporal reasoning) to produce intermediate latents, which are then refined by Shallow Flow Blocks (local within-frame details). A Learnable Causal Denoiser (trained via Flow-Score Matching) cleans the output. The model is trained end-to-end with two objectives: Maximum Likelihood for the flow and Flow-Score Matching for the denoiser.
Key Contributions
1
Global-Local Architecture for Causal Video Modeling
A novel two-level architecture that separates global temporal reasoning from local within-frame details. A deep causal Transformer block processes the video autoregressively in compressed latent space to capture long-range spatiotemporal dependencies, while shallow flow blocks operate independently on each frame to model rich local structures. This design mitigates compounding errors common in pixel-space autoregressive models.
2
Flow-Score Matching Denoising
A unified training framework that combines normalizing flow maximum likelihood with flow-score matching for denoising. Instead of using imperfect or non-causal denoisers, we train a lightweight causal neural denoiser alongside the main flow model. This denoiser learns to predict the score (gradient of log-probability) of the model's own distribution, enabling high-quality single-step refinement while preserving causality.
3
Video-Aware Jacobi Iteration
Generation (flow inversion) is recast as solving a nonlinear system, enabling block-wise parallel updates of multiple latents simultaneously instead of one-by-one generation. Combined with video-aware initialization that uses temporal information from adjacent frames and pipelined execution between deep and shallow blocks, this achieves significant speedup while maintaining generation quality.
Model Details
STARFlow-V is trained on 70M text-video pairs and 400M text-image pairs, with a final 7B parameter model that can generate 480p video at 16fps. The model operates in a compressed latent space and leverages the invertible nature of normalizing flows to natively support multiple generation tasks without any architectural changes or retraining.
Explore the Results
Navigate through the tabs above to see our model's capabilities across different generation tasks. Each category demonstrates specific aspects of STARFlow-V, from standard text-to-video generation to long-form video creation and comparisons with diffusion-based baselines.
BibTeX
If you find STARFlow-V useful in your research, please consider citing our work:
@article{gu2025starflowv,
title={STARFlow-V: End-to-End Video Generative Modeling with Scalable Normalizing Flows},
author={Gu, Jiatao and Shen, Ying and Chen, Tianrong and Dinh, Laurent and Wang, Yuyang and Bautista, Miguel \'Angel and Berthelot, David and Susskind, Josh and Zhai, Shuangfei},
journal={arXiv preprint arXiv:XXXX.XXXXX},
year={2025}
}
Text-to-Video Generation
Our model generates high-quality videos directly from text descriptions.
"a border collie balancing on a fallen log over a shallow stream; locked-off shot with gentle world motion; natural lighting"
480p • 16fps • 5s
"a campfire crackling with embers lifting; static shot; night warmth, ultra-realistic, 4K 2"
480p • 16fps • 5s
"a cassowary stepping through rainforest shade; locked-off telephoto with soft bokeh; golden-hour warmth, ultra-realistic, 4K."
480p • 16fps • 5s
"a chameleon rolling its eyes in different directions; handheld with minimal sway; overcast soft light, ultra-realistic, 4K; soft"
480p • 16fps • 5s
"a chef tossing vegetables in a pan; medium shot; stovetop glow, ultra-realistic, 4K."
480p • 16fps • 5s
"a chipmunk stuffing seeds into full cheeks; locked-off shot with gentle world motion; blue-hour ambience, ultra-realistic, 4K; l"
480p • 16fps • 5s
"a colorful nebula drifting with subtle motion; locked-off shot with gentle world motion; natural lighting, ultra-realistic, 4K;"
480p • 16fps • 5s
"a corgi wearing neon-pink sunglasses on a sunlit pier; drone orbit with steady altitude hold; light film grain for realism; gold"
480p • 16fps • 5s
"a giant panda nibbling a bamboo shoot; cinematic handheld at eye level; natural lighting, ultra-realistic, 4K."
480p • 16fps • 5s
"a heron stepping carefully in marsh shallows; handheld with minimal sway; overcast soft light, ultra-realistic, 4K; soft depth o"
480p • 16fps • 5s
"a humanoid robot practicing slow tai chi in a plaza; handheld with minimal sway; blue-hour ambience, ultra-realistic, 4K; occasi"
480p • 16fps • 5s
"a kettle venting steam on a stove; static composition with foreground elements drifting; light film grain for realism; window li"
480p • 16fps • 5s
"a penguin waddling across wet rocks; gentle push-in from a stable tripod; overcast soft light, ultra-realistic, 4K; soft depth o"
480p • 16fps • 5s
"a potter shaping clay on a spinning wheel; low-angle tilt up revealing the scene; occasional lens flare at frame edge; clean stu"
480p • 16fps • 5s
"a puffin turning its head with a beak full of fish; gentle push-in from a stable tripod; natural lighting, ultra-realistic, 4K;"
480p • 16fps • 5s
"a rooftop garden swaying in wind; smooth dolly-in along ground-level sliders; soft depth of field and creamy bokeh; candlelit gl"
480p • 16fps • 5s
"a sailboat drifting on calm water; wide shot; hazy sunlight, ultra-realistic, 4K."
480p • 16fps • 5s
"a sheep flock drifting across a grassy hillside; locked-off shot with gentle world motion; golden-hour warmth, ultra-realistic,"
480p • 16fps • 5s
"a skier floating through fresh powder; slow gimbal push-in with subtle handheld micro-shake; light film grain for realism; misty"
480p • 16fps • 5s
"a small service robot trundling down a neon alley; handheld with minimal sway; blue-hour ambience, ultra-realistic, 4K; natural"
480p • 16fps • 5s
"a snail extending its eyestalks after a light mist; gentle push-in from a stable tripod; blue-hour ambience, ultra-realistic, 4K"
480p • 16fps • 5s
"a starfish gripping a tidepool rock as water swirls; gentle push-in from a stable tripod; natural lighting, ultra-realistic, 4K;"
480p • 16fps • 5s
"a tram sliding past in light rain; handheld follow with natural breathing sway; a faint fingerprint smudge catching light; harsh"
480p • 16fps • 5s
"a zebra flicking its tail in warm savanna light; slow pan across the scene; golden-hour warmth, ultra-realistic, 4K; light film"
480p • 16fps • 5s
"aerial shot flying low over rolling sand dunes patterned by the wind."
480p • 16fps • 5s
"an ostrich scanning an open plain; slow gimbal push-in; overcast soft light; ultra-realistic, 4K."
480p • 16fps • 5s
"carbonation rising in a glass of seltzer; shallow parallax orbit at chest height; tiny focus breathing during rack focus; golden"
480p • 16fps • 5s
"cherry blossoms falling along a riverside path; locked-off shot with gentle world motion; natural lighting, ultra-realistic, 4K;"
480p • 16fps • 5s
"close-up shot of a wind chime gently moving and ringing in a light breeze."
480p • 16fps • 5s
"drone shot flying low over a lavender field with rows converging to the horizon."
480p • 16fps • 5s
" forward dolly shot through a narrow alley full of hanging lanterns and street food stalls."
480p • 16fps • 5s
"lavender swaying with bees passing through; gentle push-in from a stable tripod; overcast soft light, ultra-realistic, 4K; soft"
480p • 16fps • 5s
" macro shot of a ladybug crawling along the edge of a green leaf."
480p • 16fps • 5s
" macro shot of ink swirling and mixing in a glass of water against a white background."
480p • 16fps • 5s
" macro shot of raindrops rippling on a calm pond with concentric circles overlapping."
480p • 16fps • 5s
"paper lanterns bobbing in a night festival; over-the-shoulder follow maintaining subject center; soft depth of field and creamy"
480p • 16fps • 5s
" shot of a drone circling a small island surrounded by clear blue water."
480p • 16fps • 5s
" shot of a drone flying over a patch of colorful autumn forest."
480p • 16fps • 5s
" shot of a snow globe being shaken, flakes swirling around a tiny village."
480p • 16fps • 5s
"steam rising from a cup of tea by a window; locked-off shot; soft morning light, ultra-realistic, 4K. 2"
480p • 16fps • 5s
" timelapse of stars streaking across the night sky above a desert landscape."
480p • 16fps • 5s
" underwater shot of koi fish gliding past colorful pebbles in a clear pond."
480p • 16fps • 5s
" wide shot of waves crashing dramatically against black volcanic rocks at the coast."
480p • 16fps • 5s
"wisteria clusters swinging under a pergola; locked-off shot with gentle world motion; natural lighting, ultra-realistic, 4K; lig"
480p • 16fps • 5s
Image-to-Video Generation
Generate videos from input images while maintaining temporal consistency. Due to the autoregressive nature of our model, we don't need to change the architecture at all—one model handles all tasks seamlessly.

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s

Input Image
480p • 16fps • 5s
Video-to-Video Generation
Our model can extend and transform existing videos while maintaining temporal consistency. Due to the autoregressive nature of our model, we don't need to change the architecture at all—one model handles all tasks seamlessly.
Add_hand
384p • 16fps • 2s
Add_horse
384p • 16fps • 2s
Convert_orange_into_lemon
384p • 16fps • 2s
Turn_blackberries_into_red_currant
384p • 16fps • 2s
Detect_sheep
384p • 16fps • 2s
Detect_book
384p • 16fps • 2s
Detect_depth
384p • 16fps • 2s
Detect_hand
384p • 16fps • 2s
Detect_magnolia_tree
384p • 16fps • 2s
Inpaint
384p • 16fps • 2s
Inpaint
384p • 16fps • 2s
Inpaint
384p • 16fps • 2s
Make_flowers_Electric_Blue
384p • 16fps • 2s
Make_it_abstract_Bauhaus_style
384p • 16fps • 2s
Make_it_concept_art_style
384p • 16fps • 2s
Make_it_doodle_style
384p • 16fps • 2s
Make_it_gothic_gloomy
384p • 16fps • 2s
Make_it_traditional_Chinese_ink_painting_style
384p • 16fps • 2s
Make_the_beach_golden_sandy
384p • 16fps • 2s
Make_the_jellyfish_maroon_color
384p • 16fps • 2s
Make_the_train_metallic_silver_and_rusty
384p • 16fps • 2s
Make_the_vase_golden
384p • 16fps • 2s
Outpaint
384p • 16fps • 2s
Outpaint.
384p • 16fps • 2s
Outpaint.
384p • 16fps • 2s
Outpaint.
384p • 16fps • 2s
Outpaint.
384p • 16fps • 2s
Long Video Generation
Extended video generation (10s, 15s, 30s) using autoregressive segment-by-segment generation. The tail of each 5s segment is re-encoded as the prefix for the next segment, leveraging the invertibility of normalizing flows.
"a black ink drop blooming through clear water in a tumbler; static macro with minimal parallax; tendrils feathering out in slow"
480p • 16fps • 10s
"a corgi dog wearing a tie sat by a window"
480p • 16fps • 10s
"a corgi dozing in a sunbeam on hardwood floor; slow dolly-in at ankle height; dust motes drifting in the light shaft, shallow de"
480p • 16fps • 10s
"a corgi sticking its head out of a car window; tracking from mirror level, horizon bob from suspension; fur whipping in the wind"
480p • 16fps • 10s
"a dim street lit only by vending machines; slow dolly-forward at waist height; saturated glow halos, tiny insects swarming in li"
480p • 16fps • 10s
"a street waffle being dusted with powdered sugar; tight close-up from plate level; sugar creating tiny puffs on impact, some gra"
480p • 16fps • 10s
"fall leaves spiraling down in a courtyard; upward-looking locked-off shot; branches framing sky, occasional leaf grazing lens; l"
480p • 16fps • 10s
"school of koi swirling just below pond surface; top-down gimbal drift; occasional surface glare flare, ripples distorting bodies"
480p • 16fps • 10s
"subway doors closing on a busy platform; low-angle from floor level; rolling shutter wobble as train accelerates, reflections sl"
480p • 16fps • 10s
"zoom-in corgi face"
480p • 16fps • 13s
"a corgi dog sits in front of a blackboard teaching"
480p • 16fps • 15s
"a corgi dog wearing a tie sitting in front of a blackboard"
480p • 16fps • 15s
"a golden doodle tilting its head at a squeaky toy"
480p • 16fps • 30s
"paper lanterns bobbing in a night festival; over-the-shoulder follow maintaining subject center; soft depth of field and creamy"
480p • 16fps • 30s
"POV from the boat deck looking at a corgi wearing neon-pink sunglasses; wind noise feel, slight horizon bob, water droplets on l"
480p • 16fps • 30s
"This close-up shot of a Victoria crowned pigeon"
480p • 16fps • 30s
Method Comparisons
Side-by-side comparisons with baseline Autoregressive diffusion models. All prompts are sampled from VBench (Huang, 2023). Each video shows three methods from left to right: NOVA (https://github.com/baaivision/NOVA), WAN-Causal (finetuned from WAN provided by https://huggingface.co/gdhe17/Self-Forcing/blob/main/checkpoints/ode_init.pt), and STARFlow-V (Ours).
NOVA WAN-Causal STARFlow-V
"A panda drinking coffee in a cafe in Paris, in cyberpunk style"
480p • 16fps • 7s
NOVA WAN-Causal STARFlow-V
"A person is playing piano"
480p • 16fps • 7s
NOVA WAN-Causal STARFlow-V
"A person is tasting beer"
480p • 16fps • 7s
NOVA WAN-Causal STARFlow-V
"a backpack and an umbrella"
480p • 16fps • 7s
NOVA WAN-Causal STARFlow-V
"A 3D model of a 1800s victorian house."
480p • 16fps • 7s
NOVA WAN-Causal STARFlow-V
"A corgi's head depicted as an explosion of a nebula"
480p • 16fps • 4s
NOVA WAN-Causal STARFlow-V
"A cute happy Corgi playing in park, sunset"
480p • 16fps • 7s
NOVA WAN-Causal STARFlow-V
"A shark swimming in clear Caribbean ocean"
480p • 16fps • 7s
NOVA WAN-Causal STARFlow-V
"a bird"
480p • 16fps • 7s
NOVA WAN-Causal STARFlow-V
"a drone flying over a snowy forest."
480p • 16fps • 6s
NOVA WAN-Causal STARFlow-V
"arch"
480p • 16fps • 7s
NOVA WAN-Causal STARFlow-V
"cliff"
480p • 16fps • 7s
NOVA WAN-Causal STARFlow-V
"a person drinking coffee in a cafe"
480p • 16fps • 5s
NOVA WAN-Causal STARFlow-V
"In a still frame, a stop sign"
480p • 16fps • 7s
NOVA WAN-Causal STARFlow-V
"A boat sailing leisurely along the Seine River with the Eiffel Tower in background, in super slow motion"
480p • 16fps • 3s
NOVA WAN-Causal STARFlow-V
"The bund Shanghai, zoom in"
480p • 16fps • 7s
Failure Cases
Examples where our model struggles or produces suboptimal results, particularly on complex motion and physical interactions. These limitations stem from: (1) insufficient training due to resource constraints, (2) low-quality training data, and (3) the absence of post-training refinement—we perform only pretraining without supervised fine-tuning (SFT) or reinforcement learning (RL).
"a dog shaking off water on a dock; handheld with minimal sway; blue-hour ambience, ultra-realistic, 4K; light film grain."
480p • 16fps • 5s
"a goat kid hopping onto a small boulder then back down; handheld with minimal sway; blue-hour ambience, ultra-realistic, 4K; nat"
480p • 16fps • 5s
""A green powder is being poured into a test tube"
480p • 16fps • 5s
"a hamster running steadily in a clear exercise wheel; handheld with minimal sway; golden-hour warmth, ultra-realistic, 4K; light"
480p • 16fps • 5s
"a skateboarder kickflipping off a curb; shallow parallax orbit at chest height; slight chromatic aberration at highlights; blue-"
480p • 16fps • 5s
"a small octopus exploring a jar with one curious arm; gentle push-in from a stable tripod; golden-hour warmth, ultra-realistic,"
480p • 16fps • 5s
"a trail runner cresting a ridge at dawn; over-the-shoulder follow maintaining subject center; tiny focus breathing during rack f"
480p • 16fps • 5s
"fresh bread being sliced on a wooden board; close-up; kitchen window light, ultra-realistic, 4K."
480p • 16fps • 5s