
So there I was, fresh on sabbatical, feeling pretty GPU poor. Going from having access to whatever compute I needed to my lonely MacBook was… humbling. But then I walked into the Recurse Center hub in NYC for the first time, and someone casually mentioned they had “a couple of GPUs.”
My brain immediately went: interesting.
But here’s the thing. These weren’t just any GPUs. RC had some NVIDIA GeForce GTX TITAN X cards, but I’m rocking Apple Silicon in my M4 Max MacBook. Different architectures, different vendors, different everything. The classic “how do I get these to work together?” problem.
That’s when I remembered Ray exists.
The Heterogeneous Hardware Challenge
Training models across different hardware is becoming more common. Whether you’re at a company that acquired another team with different infrastructure, or you’re at RC trying to use whatever’s available, you’ll eventually run into this.
Here’s what I was dealing with:
- MacBook M4 Max: Apple Silicon with MPS (Metal Performance Shaders)
- RC machines: NVIDIA GeForce GTX TITAN X with CUDA
- Different machines: Mercer and Crosby (yes, RC names their machines)
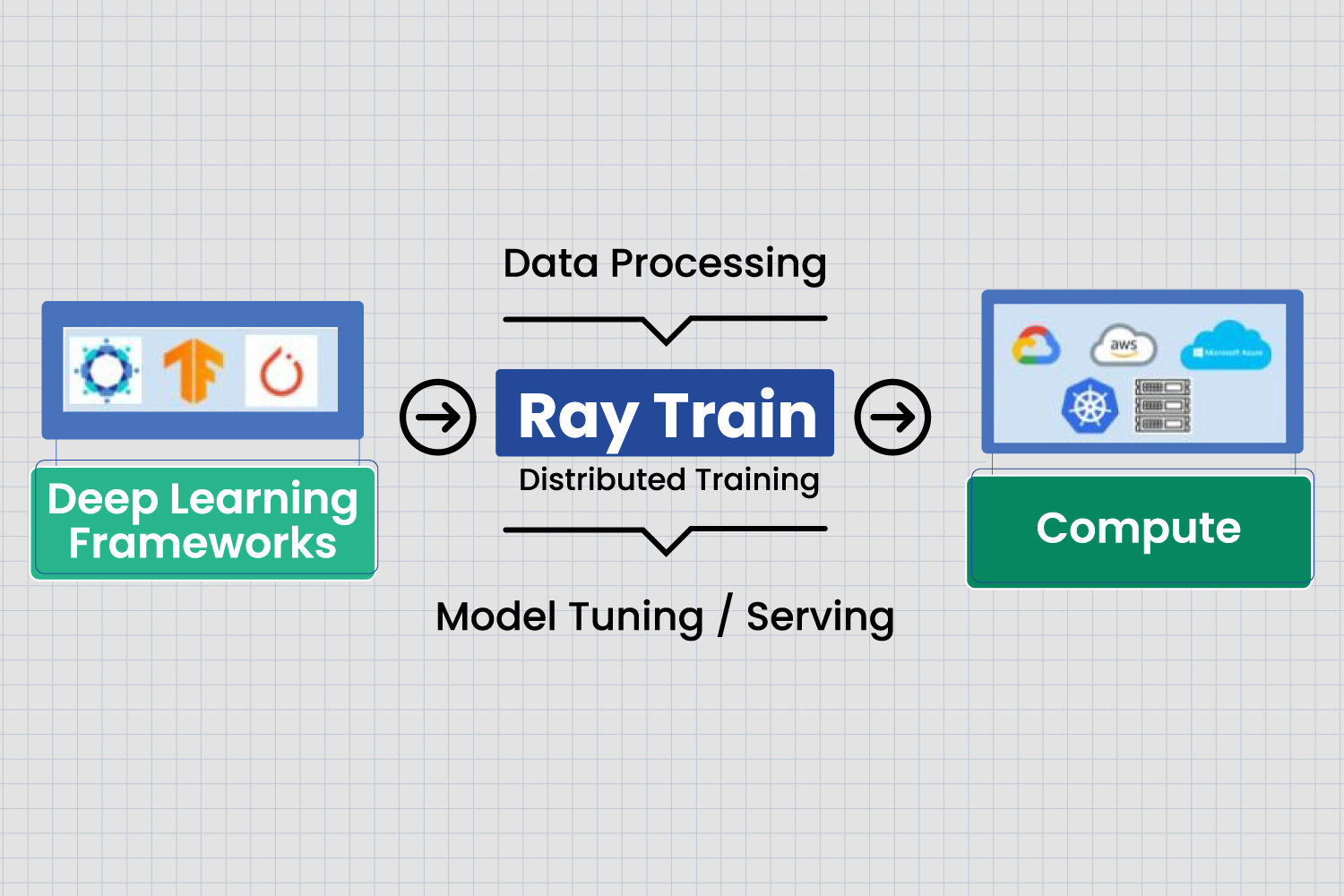
Traditional distributed training frameworks have trouble with this. NCCL (NVIDIA’s communication library) and Apple’s MPS don’t exactly play nice together. Ray handles this by creating an abstraction layer that coordinates between different hardware types.
How Ray Makes This Work
Ray’s approach is abstraction. Instead of trying to make your Apple Silicon GPU talk directly to an NVIDIA GPU, Ray creates a unified layer that handles all the communication.
Here’s the basic approach:
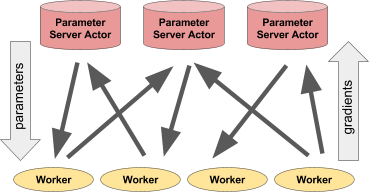
- Parameter Server Pattern: One central coordinator manages the model weights
- Heterogeneous Workers: Each machine uses whatever hardware it has
- Gradient Aggregation: Ray handles collecting and averaging gradients across all devices
- Automatic Scheduling: Ray figures out what work goes where
You write your training code once, and Ray distributes it across whatever hardware you have available.
The Code: Making It Actually Work
Let me walk you through the key pieces of my setup. First, the magic @ray.remote decorator:
1 | @ray.remote(num_gpus=1) |
This worker will automatically land on machines with GPUs. But here’s the clever bit:
1 | @ray.remote(num_cpus=2) |
By requesting different resources (num_gpus=1 vs num_cpus=2), Ray automatically distributes workers across different types of hardware. The NVIDIA workers land on the CUDA machines, while the CPU/MPS worker ends up on my MacBook.
The Parameter Server: Keeping Everyone in Sync
The parameter server is where the magic happens:
1 | @ray.remote(num_cpus=1) |
Each worker computes gradients on its own hardware (CUDA, MPS, or CPU), then sends them back to the parameter server. The parameter server averages everything and updates the global model.
The Training Loop: Where It All Comes Together
Here’s what a training iteration looks like:
1 | for iteration in range(training_iterations): |
The beauty here is the ray.get(futures) call. Ray handles all the complexity of coordinating between different devices and architectures. You just get your results back.
What I Learned: The Real Benefits
After running this for a while, here’s what became clear:
1. It Actually Works
I had one model training simultaneously on:
- My MacBook M4 Max (using MPS)
- Mercer’s NVIDIA GeForce GTX TITAN X (using CUDA)
- Crosby’s NVIDIA GeForce GTX TITAN X (using CUDA)
All three machines contributing to training the same model. In real time. No hacky workarounds.
2. Resource Utilization is Better
Instead of leaving hardware idle because it doesn’t match your “preferred” setup, you can use everything.
3. The Parameter Server Pattern Scales
This isn’t just a toy example. The parameter server pattern scales to much larger models and clusters. Companies like Netflix are using Ray for heterogeneous training clusters with mixed hardware across their infrastructure.
4. Fault Tolerance Comes Free
Ray handles worker failures gracefully. If one machine crashes, the training continues with the remaining workers. No manual intervention needed.
The Bigger Picture: Why This Matters
This isn’t just about using random hardware lying around. As AI models get larger, the economics of training matter more. Being locked into a single hardware vendor gets expensive.
Recent research shows that heterogeneous training can achieve up to 16% better performance compared to traditional homogeneous setups, especially for models with over 1 billion parameters. Companies are realizing that vendor diversity isn’t just about avoiding lock-in—it’s about optimizing cost and performance.
Scaling to Real Models
Now, my demo used a simple neural network, but the same principles apply to large language models. The key differences for scaling up:
- Memory Management: Use gradient checkpointing and model sharding
- Communication Optimization: Ray supports various communication backends
- Data Pipeline: Ray Data can handle distributed data loading efficiently
For 1B+ parameter models, you’d want to add:
- DeepSpeed integration for memory efficiency
- Mixed precision training for speed
- Dynamic batching based on hardware capabilities
The Setup Scripts: Making It Reproducible
I wrote some simple scripts to make this whole thing reproducible:
setup_cluster.sh:
1 | #!/bin/bash |
teardown_cluster.sh:
1 | #!/bin/bash |
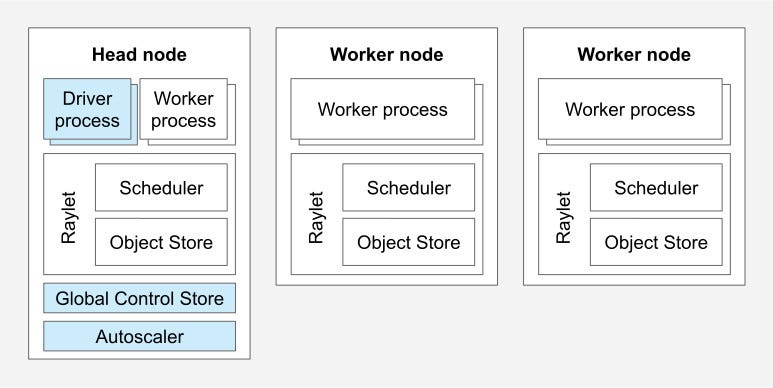
Then your MacBook just connects as another worker in the cluster. No complex Kubernetes setup, no Docker orchestration, no SLURM. Just Ray being Ray.
What I Built: A Framework for Everyone
After getting this working, I realized other people probably run into the same problem. So I built a simple framework that wraps all this complexity: distributed-hetero-ml.
The idea was to make heterogeneous distributed training as simple as possible. Instead of writing all the parameter server and worker coordination code yourself, you just define your model and data, and the framework handles the rest:
1 | from distributed_hetero_ml import DistributedTrainer, TrainingConfig |
The framework automatically detects your hardware and configures itself. Got NVIDIA GPUs? It uses CUDA. Apple Silicon? MPS backend. Mixed setup? No problem.
It also handles checkpointing, cluster connections, and resource management. The goal was to abstract away all the Ray boilerplate while keeping the flexibility for when you need to dig deeper.
Looking Forward: The 1B Parameter Goal
My next step is scaling this to actual language models. Ray Train has built-in support for Hugging Face Transformers, so I can take a 1B parameter model and train it across all the available hardware at RC, plus whatever cloud resources I want to add.
The workflow would be:
- Use Ray Data for distributed data loading
- Ray Train for orchestrating the training
- Ray Tune for hyperparameter optimization
- Ray Serve for deployment
All while using whatever hardware is available, from Apple Silicon to NVIDIA to potentially even AMD GPUs if I can get my hands on some.
The Bottom Line
Ray made it possible to use all the available hardware, regardless of vendor. No more “sorry, this only works on NVIDIA” or “you need identical hardware across all nodes.” Point Ray at your mismatched collection of machines and it figures out how to use them.
For anyone working on distributed training - whether you’re at a startup with mixed hardware, a company dealing with merger integration, or just someone at RC trying to train bigger models - Ray makes heterogeneous computing practical.
It’s pretty cool watching your MacBook contribute gradients alongside a couple of NVIDIA rigs, all working together on the same model. Turns out you don’t need to pick a side in the hardware wars.
What started as a “hey, can I use these random GPUs?” problem at RC turned into a framework that hopefully makes this easier for other people. Sometimes being GPU poor forces you to get creative.