Publish date: Jan 20, 2026 9:18:43 PM
✍🏼 About The Author: Seaven He, StarRocks Committer, Engineer at Celerdata Joins are the hardest part of OLAP. Many systems can’t run them efficiently at scale, so teams denormalize into wide tables instead, 10× their storage, dealing with complex stream processing pipelines, and painfully slow and expensive schema evolution that triggers large backfills. StarRocks takes the opposite approach: keep data normalized and make joins fast enough to run on the fly. The challenge is the plan. In a distributed system, the join search space is huge, and a good plan can be orders of magnitude faster. This deep dive explains how StarRocks’ cost-based optimizer makes that possible, in four parts: join fundamentals and optimization challenges, logical join optimizations, join reordering, and distributed join planning. Finally, we examine real-world case studies from NAVER, Demandbase, and Shopee to illustrate how efficient join execution delivers tangible business value. The diagram above illustrates several common join types: Join performance optimization generally falls into two areas: This article focuses on the second aspect. To set the stage, we begin by examining the key challenges in join optimization. Challenge 1: Multiple Join Implementation Strategies As shown above, different join algorithms perform very differently depending on the scenario. For example, Sort-Merge Join can be significantly more efficient than Hash Join when operating on already sorted data. However, in distributed databases where data is typically hash-partitioned, Hash Join often outperforms Sort-Merge Join by a wide margin. As a result, the database must choose the most appropriate join strategy based on the specific workload and data characteristics. Challenge 2: Join Order Selection in Multi-Table Joins In multi-table join scenarios, executing highly selective joins first can significantly improve overall query performance. However, determining the optimal join order is far from trivial. As illustrated above, under a left-deep join tree model, the number of possible join orders for N tables is on the order of Challenge 3: Difficulty in Estimating Join Effectiveness Before query execution, it is extremely difficult for the database to accurately predict the real execution behavior of a join. A common assumption is that joining a small table with a large table is more selective than joining two large tables, but this is not always true. In practice, one-to-many relationships are common, and in more complex queries, joins are often combined with filters, aggregations, and other operators. After data flows through multiple transformations, the optimizer’s ability to accurately estimate join input sizes and selectivity degrades significantly. Challenge 4: A Single-Node Optimal Plan Is Not Necessarily Optimal in Distributed Systems Press enter or click to view image in full size In distributed systems, data often needs to be reshuffled or broadcast across nodes so that the required records can participate in join computation. Distributed joins are no exception. This introduces a key complication: an execution plan that is optimal in a single-node database may perform poorly in a distributed environment because it ignores data distribution and network transfer costs. Therefore, when planning join execution strategies in distributed databases, the optimizer must explicitly account for data placement and communication overhead in addition to local execution efficiency. In StarRocks, SQL optimization is primarily handled by the query optimizer and is mainly concentrated in the Rewrite and Optimize phases. At present, StarRocks primarily uses Hash Join as its join algorithm. By default, the right-hand table is used to build the hash table. Based on this design choice, we summarize five key optimization principles: This section introduces a set of heuristic rules used by StarRocks to optimize joins at the logical level. The first group of optimizations directly follows the first join optimization principle discussed earlier: transform low-efficiency join types into more efficient ones whenever the semantics allow it. StarRocks currently applies three major transformation rules. Rule 1: Converting a Cross Join into an Inner Join A Cross Join can be rewritten as an Inner Join when it satisfies the following condition: For example: Rule 2: Converting an Outer Join into an Inner Join A Left / Right Outer Join can be rewritten as an Inner Join when the following conditions are met: Example: ⚠️ Important note: In an outer join, This query is not semantically equivalent to: This introduces the concept of strict (null-rejecting) predicates. In StarRocks, a predicate that filters out To determine whether a predicate is strict, StarRocks uses a simple yet effective approach: all referenced columns are replaced with Rule 3: Converting a Full Outer Join into a Left / Right Outer Join A Full Outer Join can be rewritten as a Left Outer Join or Right Outer Join when the following condition is satisfied: Example: Predicate pushdown is one of the most important and commonly used join optimization techniques. Its primary purpose is to filter join inputs as early as possible, thereby reducing the amount of data involved in the join and improving overall performance. For predicates in the For example: The predicate pushdown process proceeds as follows. Step 1 : Push down Step 2: Continue pushing down It is important to note that predicate pushdown rules for join predicates in the Case 1: Inner Join For Inner Joins, pushing down join predicates in the Case 2: Outer / Semi / Anti Joins For Outer, Semi, and Anti Joins, predicate pushdown on Consider the following example: The predicate pushdown proceeds as follows. Step 1: Push down the join predicate Press enter or click to view image in full size Step 2: Push down the join predicate However, the predicate Press enter or click to view image in full size In the predicate pushdown rules discussed earlier, only predicates with conjunctive semantics can be pushed down. For example, in In real-world queries, disjunctive predicates are quite common. To address this, StarRocks introduces an optimization called predicate extraction (column value derivation). This technique derives conjunctive predicates from disjunctive ones by performing a series of union and intersection operations on column value ranges. The derived conjunctive predicates can then be pushed down to reduce join input size. For example: Using column value derivation on The query can then be rewritten as: It is important to note that the extracted predicates may form a superset of the original predicate ranges. As a result, they cannot safely replace the original predicates and must instead be applied in addition to them. In addition to predicate extraction, another important predicate-level optimization is equivalence derivation. This technique leverages join equality conditions to infer value constraints on one side of the join from predicates applied to the other side. Specifically, based on the join condition, value ranges on columns from the left table can be used to derive corresponding value ranges on columns from the right table, and vice versa. For example: Using predicate extraction on Resulting in: Next, using the join predicate The query can therefore be further rewritten as: Applicability and Constraints The scope of equivalence derivation is more limited than predicate extraction. Predicate extraction can be applied to arbitrary predicates, whereas equivalence derivation, like predicate pushdown, has different constraints depending on the join type. As before, we distinguish between For For Why Is Equivalence Derivation One-Directional for Outer / Semi Joins? The reason is straightforward. Consider a Left Outer Join. As discussed in predicate pushdown rules, only predicates on the right table can be pushed down; predicates on the left table cannot, as doing so would violate the semantics of a left outer join. For the same reason, predicates derived from the right table and applied to the left table must also respect this constraint. In practice, such derived predicates on the preserved side do not help filter data early and instead introduce additional evaluation overhead. Therefore, equivalence derivation for Outer and Semi Joins is intentionally restricted to a single direction. Implementation Details StarRocks implements equivalence derivation by maintaining two internal maps: By performing lookups and inference across these two maps, the optimizer derives additional equivalent predicates. The overall mechanism is illustrated below: In addition to predicates, For example, in a Left Outer Join, the output row count is at least the same as that of the left input. Therefore, the A Cross Join produces a Cartesian product, with output cardinality equal to For these join types, a Join reordering is used to determine the execution order of multi-table joins. The optimizer aims to execute high-selectivity joins as early as possible, thereby reducing the size of intermediate results and improving overall query performance. In StarRocks, join reordering primarily operates on continuous sequences of Inner Joins or Cross Joins. As illustrated below, StarRocks groups a sequence of consecutive Inner / Cross Joins into a Multi Join Node. A Multi Join Node is the basic unit for join reordering: if a query plan contains multiple such nodes, StarRocks performs join reordering independently for each one. There are many join reordering algorithms in the industry, often based on different optimization models, including: StarRocks currently implements several join reordering strategies, including Left-Deep, Exhaustive, Greedy, and DPsub. In the following sections, we focus on the implementation details of Exhaustive and Greedy join reordering in StarRocks. The exhaustive join reordering algorithm is based on systematically enumerating all possible join orders. In practice, this is achieved through two fundamental rules, which together cover nearly the entire space of join permutations. Rule 1: Join Commutativity A join between two relations can be reordered by swapping its inputs: During this transformation, the join type must be adjusted accordingly. For example, a Rule 2: Join Associativity Join associativity allows the join order among three relations to be rearranged: In StarRocks, associativity is handled differently depending on the join type. Specifically, StarRocks distinguishes between: For its greedy join reordering strategy, StarRocks primarily draws inspiration from multi-sequence greedy algorithms, with a small but important enhancement: at each iteration level, instead of keeping only a single best result, StarRocks retains the top 10 candidate plans (which may not be globally optimal). These candidates are then carried forward into the next iteration, ultimately producing 10 greedy-optimized plans. Due to the inherent limitations of greedy algorithms, this approach does not guarantee a globally optimal plan. However, by preserving multiple high-quality candidates at each step, it significantly increases the likelihood of finding a near-optimal or optimal solution. Press enter or click to view image in full size StarRocks uses these join reordering algorithms to generate N candidate plans. It then evaluates them with a cost model that estimates the cost of each join. The overall cost is computed as: Join Cost = CPU × (Row(L) + Row(R)) + Memory × Row(R) Here, Because different join reordering algorithms explore search spaces of varying sizes and have different time complexities, StarRocks benchmarks their execution time and complexity characteristics, as shown below. Based on the observed execution costs, StarRocks applies practical limits to how different join reordering algorithms are used: On top of these, StarRocks further explores additional plans using join commutativity. After covering the logical optimizations involved in join queries, we now turn to join execution in a distributed environment, focusing on how StarRocks optimizes distributed join planning as a distributed database. StarRocks is built on an MPP (Massively Parallel Processing) execution framework. The overall architecture is illustrated below. Using a simple join query as an example, the execution of As shown, query execution usually involves multiple sets of machines: the nodes reading table A, the nodes reading table B, and the nodes performing the join are not necessarily the same. As a result, execution inevitably involves network transfers and data exchanges. These network operations introduce significant overhead. Therefore, a key goal in optimizing distributed join execution in StarRocks is to minimize network cost, while more intelligently partitioning and distributing the query plan to fully leverage the benefits of parallel execution. We begin by introducing the distributed execution plans that StarRocks can generate. Using a simple join query as an example: In practice, StarRocks can generate five basic types of distributed join plans: StarRocks derives distributed join plans through distribution property inference. Using a shuffle join as an example: Other distributed join strategies are derived in the same way: the join operator requests different distribution properties from its input operators, and the optimizer generates the corresponding distributed execution plans accordingly. In real-world workloads, user queries are far more complex than a simple For example: Using combinations of Shuffle Join and Broadcast Join, StarRocks can derive multiple distributed plans, as illustrated below. If Colocate Join and Bucket Shuffle Join are also considered, even more execution plans become possible: Despite their increased complexity, the underlying derivation logic remains the same. Distribution properties are propagated downward through the plan tree, allowing the optimizer to infer different combinations of distributed join strategies. Beyond exploring distributed execution plans, StarRocks further optimizes join performance by leveraging the execution characteristics of join operators to build Global Runtime Filters. The execution flow of a Hash Join in StarRocks is as follows: Global Runtime Filters are applied between Step 2 and Step 3. After constructing the hash table on the right side, StarRocks derives runtime filter predicates from the observed data and pushes these filters down to the scan nodes of the left table before left-side data is read. This allows the left table to filter out irrelevant rows early, significantly reducing join input size. At present, Global Runtime Filters in StarRocks support the following filtering techniques: Min/Max filters, IN predicates, and Bloom filters. The diagram below illustrates how these filters work in practice. This article has explored StarRocks’ practical experience and ongoing work in join query optimization. All of the techniques discussed are closely aligned with the core optimization principles outlined throughout the article. When optimizing SQL queries in practice, users can also apply the following guidelines together with the features provided by StarRocks to achieve better performance: By leveraging StarRocks’ On-the-Fly JOIN capabilities, Demandbase successfully replaced its existing ClickHouse clusters, optimizing performance while significantly reducing costs across multiple areas. Read the case study: Demandbase Ditches Denormalization By Switching off ClickHouse NAVER modernized its data infrastructure with StarRocks by enabling scalable, real-time analytics over multi-table joins without denormalization. The case study highlights the critical role of efficient, on-the-fly join execution in supporting production-scale analytical workloads. Read the case study: How JOIN Changed How We Approach Data Infra At NAVER Data Go is a no-code query platform where Shopee business users build queries from multiple tables. Presto struggled with complex join performance and high resource usage. When Shopee switched to StarRocks for multi-table joins, they observed 3×–10× performance improvements and a ~60% reduction in CPU usage compared with Presto on external Hive data. Read the case study: How Shopee 3xed Their Query Performance With StarRocks Want to dive deeper into technical details or ask questions? Join StarRocks Slack to continue the conversation!
Join Fundamentals and Optimization Challenges
1.1 Join Types

NULL values filled in according to the join semantics—on both tables (full), the left table (left), or the right table (right).NOT IN or NOT EXISTS subqueries.1.2 Challenges in Join Optimization


2^n-1. Under a bushy join tree model, the number of possible combinations grows even more dramatically, reaching 2^(n-1) * C(n-1). For a database optimizer, the time and cost required to search for the optimal join order therefore increases exponentially, making join ordering one of the most challenging problems in query optimization.

1.3 SQL Optimization Workflow

1.4 Principles of Join Optimization
Join Logical Optimization
2.1 Type Transformations
-- Before transformation
-- Before transformation
ON clause predicates participate in null extension, not filtering. Therefore, this rule does not apply to join predicates inside the ON clause:SELECT * FROM t1 LEFT OUTER JOIN t2 ON t1.v1 = t2.v1 AND t2.v1 > 1;
SELECT * FROM t1 INNER JOIN t2 ON t1.v1 = t2.v1 AND t2.v1 > 1;
NULL values is considered a strict predicate, for example a > 0. Predicates that do not eliminate NULL values are classified as non-strict predicates, such as a IS NULL. Most predicates fall into the strict category; non-strict predicates are primarily those involving IS NULL, IF, CASE WHEN, or certain function-based expressions.NULL, and the expression is then simplified. If the result evaluates to TRUE, it means the WHERE clause does not filter out rows with NULL inputs, and the predicate is therefore non-strict. Conversely, if the result evaluates to FALSE or NULL, the predicate is considered strict.
-- Before transformation
2.2 Predicate Pushdown
WHERE clause, predicate pushdown can be applied—and may enable join type transformations—when the following conditions are satisfied:
WHERE predicate can be bound to one of the join inputs.Select *
(t1.v1 = 1 AND t2.v1 = 2) and (t3.v2 = 3) separately. Since the join type transformation rules are satisfied,(t1 LEFT OUTER JOIN t2) LEFT OUTER JOIN t3can be rewritten as (t1 LEFT OUTER JOIN t2) INNER JOIN t3.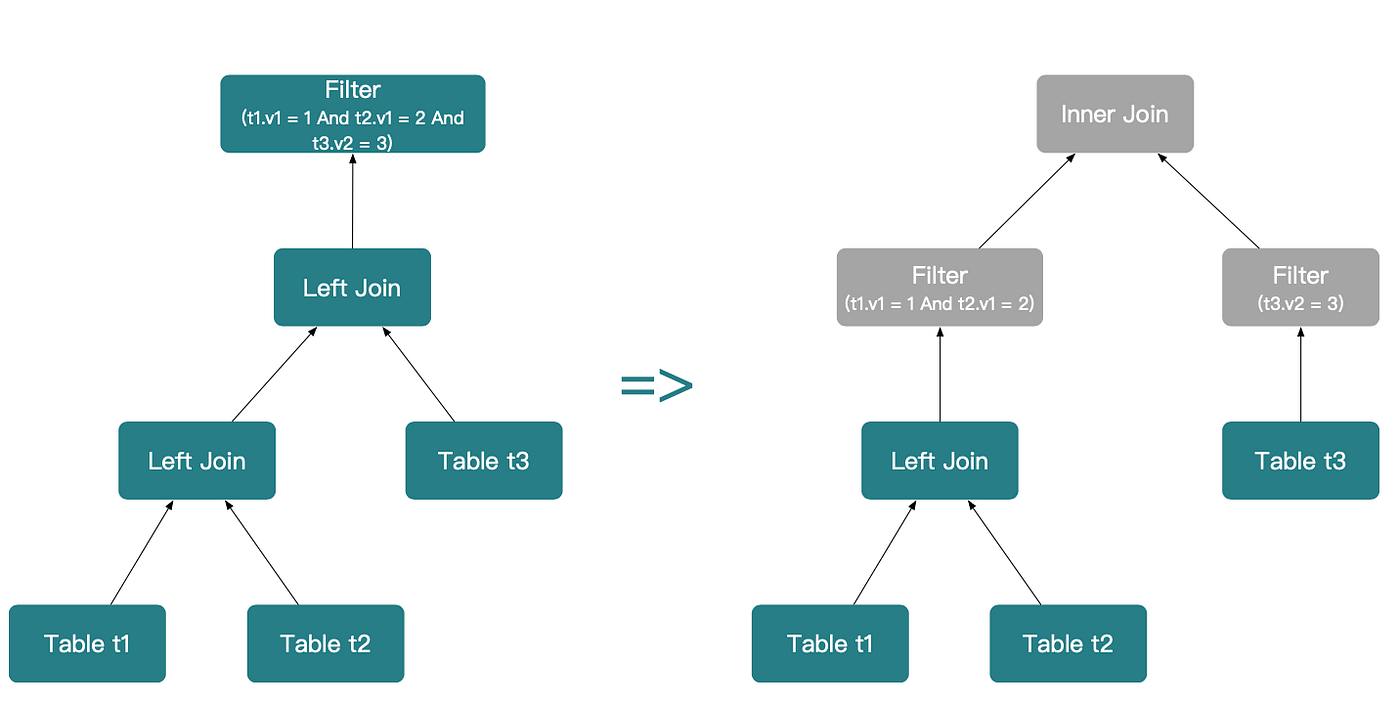
(t1.v1 = 1) and (t2.v1 = 2). At this point,t1 LEFT OUTER JOIN t2 can be further transformed intot1 INNER JOIN t2.
ON clause differ from those for the WHERE clause. We distinguish between two cases: Inner Joins and other join types.ON clause follows the same rules as WHERE clause predicate pushdown. This has already been discussed above and will not be repeated here.ON clause join predicates must satisfy the following constraints, and no join type transformation is allowed during the pushdown process:
Select *
(t3.v2 = 3), which can be bound to the right input of t1 LEFT JOIN t2 LEFT JOIN t3. At this stage, the LEFT OUTER JOIN cannot be converted into an INNER JOIN.
(t2.v1 = 2), which can be bound to the right input oft1 LEFT JOIN t2.(t1.v1 = 1) is bound to the left input. Pushing it down would filter rows from t1, violating the semantics of a LEFT OUTER JOIN. Therefore, this predicate cannot be pushed down.
2.3 Predicate Extraction
t1.v1 = 1 AND t2.v1 = 2 AND t3.v2 = 3, each sub-predicate is connected by conjunction, making pushdown straightforward. However, predicates with disjunctive semantics, such ast1.v1 = 1 OR t2.v1 = 2 OR t3.v2 = 3, cannot be pushed down directly.-- Before predicate extraction
(t2.v1 = 2 AND t1.v2 = 3) OR (t2.v1 > 5 AND t1.v2 = 4), the optimizer can extract the following predicates:
t2.v1 >= 2t1.v2 IN (3, 4)SELECT *
2.4 Equivalence Derivation
-- Original SQL
(t2.v1 = 2 AND t1.v2 = 3) OR (t2.v1 > 5 AND t1.v2 = 4), the optimizer can derive the following predicates:
t2.v1 >= 2t1.v2 IN (3, 4)SELECT *
(t1.v1 = t2.v1) together with t2.v1 >= 2, equivalence derivation can infer an additional predicate:
t1.v1 >= 2SELECT *
WHERE predicates and ON clause join predicates.WHERE predicates:
ON clause join predicates:
WHERE predicates—no additional constraints apply.

2.5 Limit Pushdown
LIMIT clauses can also be pushed down through joins. When a query involves an Outer Join or a Cross Join, the LIMIT can be pushed down to child operators whose output row count is guaranteed to be stable.LIMIT can be pushed down to the left table (and symmetrically for a Right Outer Join).-- Before pushdown
Special Cases: Cross Join and Full Outer Join
rows(left) × rows(right). A Full Outer Join produces at leastrows(left) + rows(right).LIMIT can be pushed down to both inputs independently:-- Before pushdown
Join Reordering

3.1 Exhaustive
A JOIN B → B JOIN ALEFT OUTER JOIN becomes a RIGHT OUTER JOIN after swapping the join operands.
(A JOIN B) JOIN C → A JOIN (B JOIN C)

3.2 Greedy

3.3 Cost Model
Row(L) and Row(R) are the estimated output row counts of the join’s left and right children, respectively. This formula primarily accounts for the CPU cost of processing both inputs, as well as the memory cost of building the hash table on the right side of a hash join. The figure below shows how StarRocks estimates join output row counts in more detail.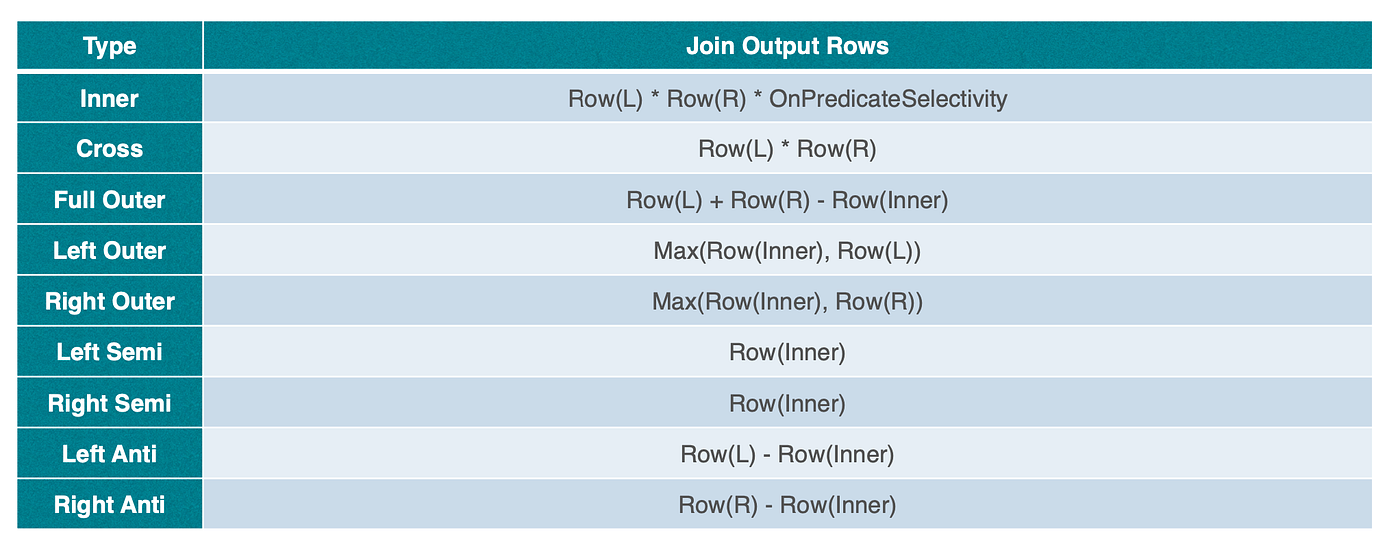


Distributed Join Planning
4.1 MPP Parallel Execution
A JOIN B in StarRocks typically proceeds as follows:

4.2 Distributed Join Optimization
Select * From A Join B on A.a = B.b
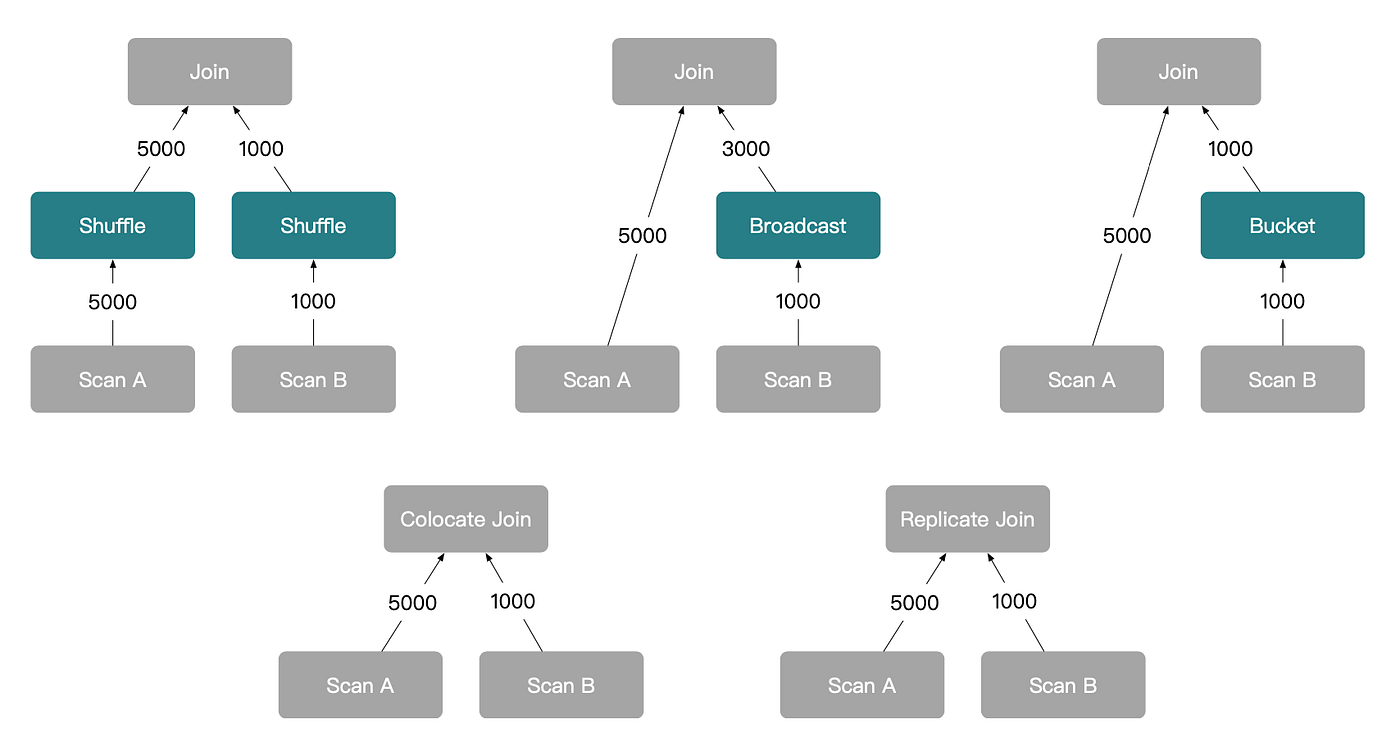
4.3 Exploring Distributed Join Plans
SELECT * FROM A JOIN B ON A.a = B.b, the join operator propagates shuffle requirements top-down to tables A and B. If a scan node cannot satisfy the required distribution, StarRocks inserts an Enforce operator to introduce a shuffle. In the final execution plan, this shuffle is translated into an Exchange node responsible for network data transfer.
4.4 Complex Distributed Joins
A JOIN B. They often involve three or more tables. For such queries, StarRocks generates a richer set of distributed execution plans, all derived from the same fundamental join strategies described earlier.Select * From A Join B on A.a = B.b Join C on A.a = C.c
4.5 Global Runtime Filters
Summary
Case Studies
Demandbase
Naver
Shopee