Over the last couple of months, I’ve been building a few projects on Cloudflare Workers, and it’s been a fun technology shift for me. Developing TypeScript applications on serverless infrastructure after several years of Go and Kubernetes has brought me lots of interesting challenges and opportunities. In many ways, it feels like the opposite of what I’ve done with k8s. Infrastructure and component connections (bindings) are managed in a single configuration file instead of sprawling YAML files. Instead of working with containerized microservices and operators, I have to build light processes invoked through in-code APIs. The constraints are different, but working within them has given me a greater appreciation for the power of Kubernetes while also making me grow attached to the seamless developer experience of the Cloudflare platform.
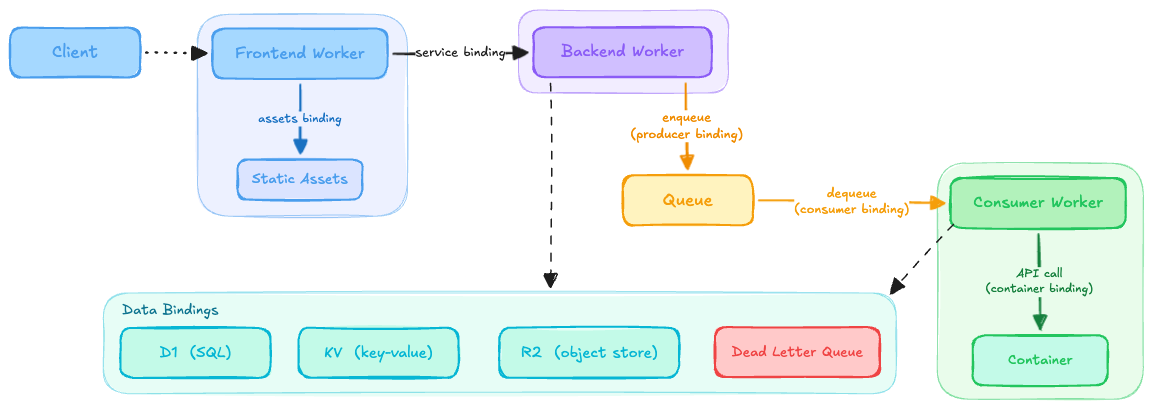
The diagram above is roughly how a typical architecture with my most-used patterns comes together. It took a few annoying and painful lessons to land here, but the platform’s binding model nudged me in the right direction. Workers are small by design, and the bindings gave me just what I needed to compose them into bigger patterns.
At the core of any architecture is communication, and service bindings and queues work insanely well. I use service bindings when I need fast, direct calls from one worker to another. In my Wrangler config, I just add:
[[services]]
binding = "BOUND_SERVICE"
service = "my-worker"
Then in code I can easily send a request like this, with no HTTP overhead:
const request = new Request('api/v1/data', { method: 'GET' });
const response = await env.BOUND_SERVICE.fetch(request);
This might seem simple, but coming from a k8s background it’s a meaningful shift. At a previous role we spent real time and infrastructure trying to solve service discovery; trying to figuring out which services talk to each other, which host to use per environment, keeping that visible and manageable across teams. We end up reaching for tools just to answer the question “who calls who.” With service bindings, the answer lives right in the config. It’s a couple of lines, and those lines double as documentation of your service communication graph without any extra infrastructure to maintain.
I use queues when failure actually matters. Anything I need to retry, delay, or handle gracefully goes through a queue. In k8s I would have reached for another tool like Kafka or SQS for this, which means more infrastructure to provision, configure, monitor, and reason about. Here it’s all in the Wrangler config:
# In the producer's wrangler.toml
[[queues.producers]]
queue = "message-queue"
binding = "MESSAGE_QUEUE"
# In the consumer's wrangler.toml
[[queues.consumers]]
queue = "message-queue"
max_concurrency = 5
max_batch_size = 3
max_batch_timeout = 5
max_retries = 3
dead_letter_queue = "message-dlq"
Then in code I just end up with code blocks like this:
// Sending messages
const msg = { key: 'value' };
await env.MESSAGE_QUEUE.send(msg);
// Processing message
export default {
async queue(batch, env, ctx): Promise<void> {
for (const message of batch.messages) {
console.log(message.key);
}
}
};
No additional tooling. The queuing system is just there and the resilience story is config rather than code. That trade-off keeps showing up with Cloudflare and it’s one of the things I’ve genuinely enjoyed about working on the serverless side of things.
One thing to note is that workers run in a V8 sandbox with strict resource limits. While the resource limits are real, they are manageable once you stop fighting them. The pattern I kept coming back to was breaking long-running processes into chunks and passing a continuation token through queue messages or service calls. This essentially means checkpointing work. In some cases, that involves persisting temporary data to R2 or KV so nothing blows its budget in a single execution.
The other binding that comes up when I want to avoid some of the limitations of the worker runtime is containers (currently in beta). Some of the limits can be configured (and increased with a Workers paid subscription) a bit, but the runtime can’t. When I needed to run workloads that didn’t neatly fit into the model, a container binding let me attach an image with its own runtime and call into it the same way I call into service bindings. For example, if you need image processing with a library like Sharp for compression or transformation, you can’t run that inside a worker but a container binding solves it cleanly. It uses a slim wrapper for passing environment variables and spinning up instances in the bound worker’s code.
// The container creates a "Durable Object"
export class MyContainer extends Container {
defaultPort = 8080;
envVars = {
ENV_KEY1: env.ENV_KEY1 || '',
ENV_KEY2: 'hello world'
};
}
// Send requests to the container
const container = env.CONTAINER.getByName('instance-1');
container.fetch('api/v1/action', {
method: 'POST',
body: JSON.stringify(request),
});
Containers (and durable objects, in general) provide a nice escape hatch. The rest of your architecture stays serverless and you only reach for a container when the runtime genuinely needs it.
The constraint that keeps biting me is D1’s query limitations, especially the 100-parameter limit on batch queries. Every time my data models grew, I ran into sneaky bugs related to this. The fix is just chunking batches so that I never pass in so many parameters, but it took a few rounds before it became second nature. There are many other platform limits worth knowing too, but I rarely hit them when following the patterns that help me get around those other challenges.
I’ve built on a lot of platforms where infrastructure problems and application problems are tangled together. On Workers, they’re largely separate. It’s been interesting working in a system where the constraints shift from operational to architectural.
There are definitely still some rough edges when working with Cloudflare, but in the short time I’ve been using it, I’ve also seen some great enhancements made to the ecosystem. Generally, I’m left to think about the design of what I’m building rather than how to keep it running. I like to pair it with tools like Drizzle, Hono, and Localflare to improve my developer experience even more. Between the Wrangler CLI, MCP integration, GraphQL API, and solid documentation, Cloudflare provides a great suite of tools for extending architectures quickly with the help of coding assistants.
Coming from k8s, the biggest adjustment isn’t the TypeScript or the serverless model; it’s recalibrating how much infrastructure you actually need to think about. My home server still runs Kubernetes and I still genuinely enjoy that flexibility; being able to drop in open source software and wire it together however I want is something Cloudflare can’t match. But for pipelines where I just need things to run, Workers is hard to beat. The mental shift is realizing those aren’t competing opinions, they’re just different problems. I came in expecting to feel constrained. I left thinking more carefully about what I actually need to own.