Abstract
Diffusion language models (DLMs) offer a compelling promise: parallel token generation could break the sequential bottleneck of autoregressive (AR) decoding. Yet in practice, DLMs consistently lag behind AR models in quality.
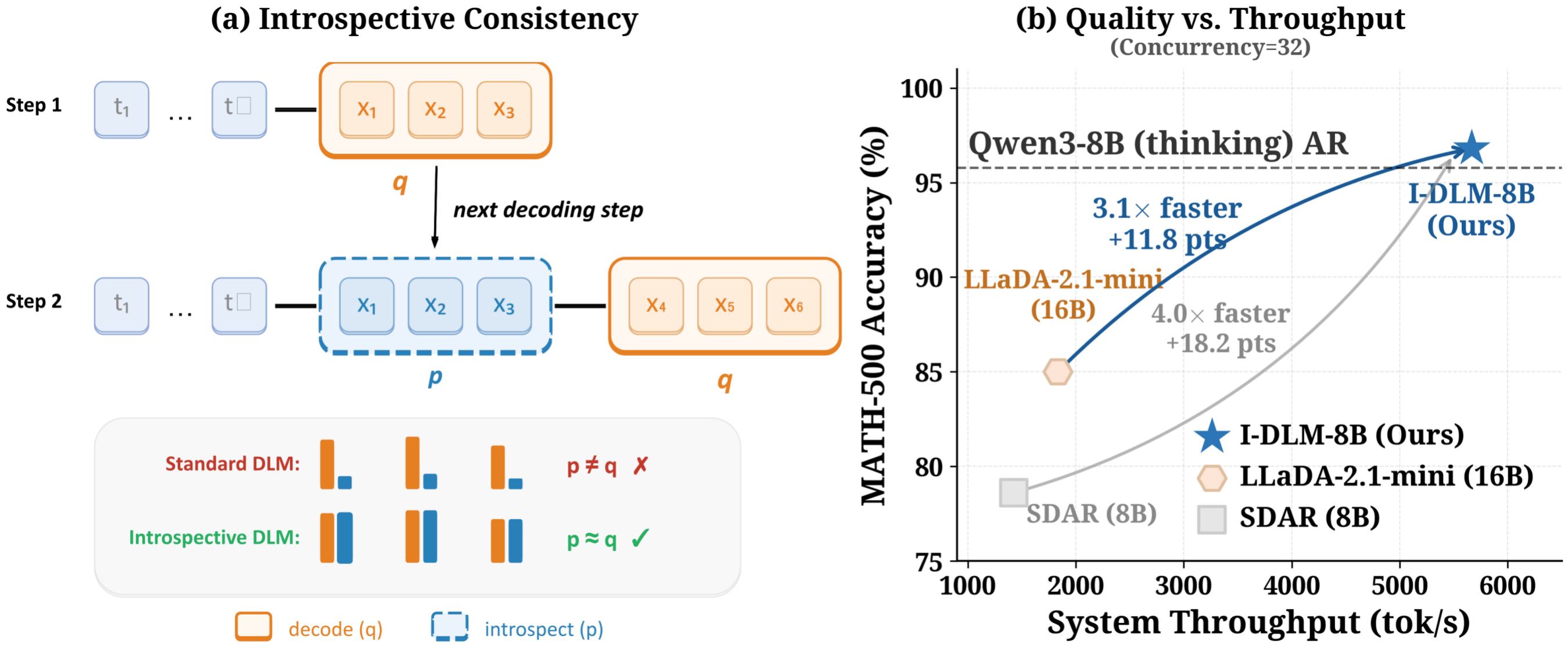
We argue that this gap stems from a fundamental failure of introspective consistency: AR models agree with what they generate, whereas DLMs often do not. We introduce the Introspective Diffusion Language Model (I-DLM), which uses introspective strided decoding (ISD) to verify previously generated tokens while advancing new ones in the same forward pass.
Empirically, I-DLM-8B is the first DLM to match the quality of its same-scale AR counterpart, outperforming LLaDA-2.1-mini (16B) by +26 on AIME-24 and +15 on LiveCodeBench-v6 with half the parameters, while delivering 2.9-4.1x throughput at high concurrency. With gated LoRA, ISD enables bit-for-bit lossless acceleration.
Why Introspective Consistency?
Key Insight: AR training unifies generation and introspection in one forward pass. Existing DLMs miss this — they learn to denoise but not to introspect.
We identify three fundamental bottlenecks in current DLMs:
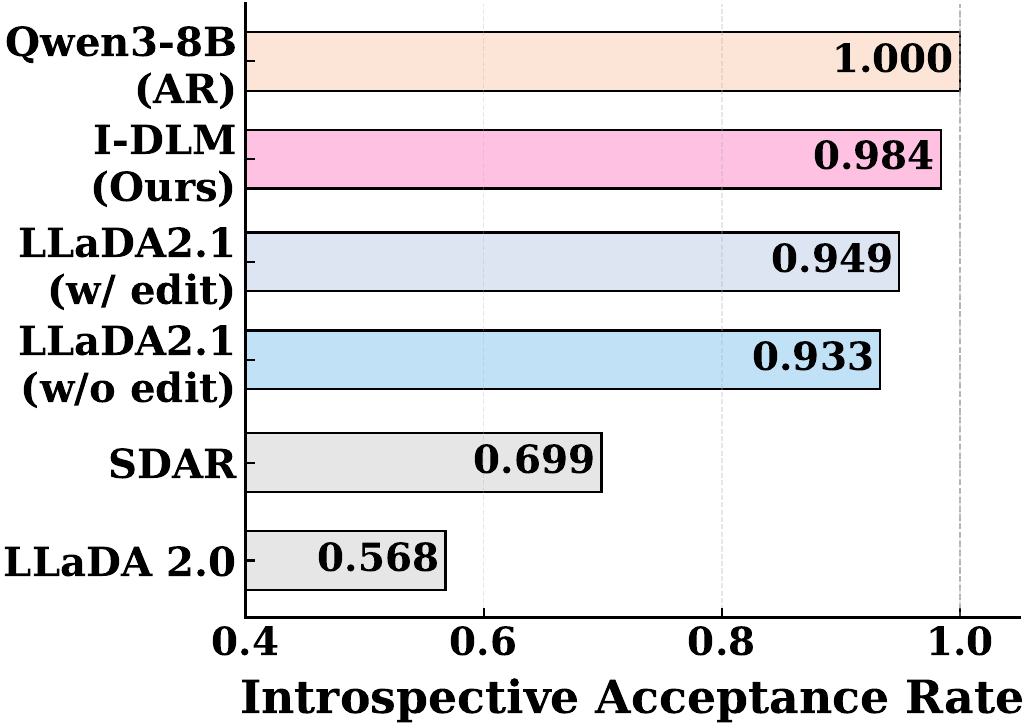
(1) Low introspective consistency. SDAR: 0.699 vs. I-DLM: 0.984.
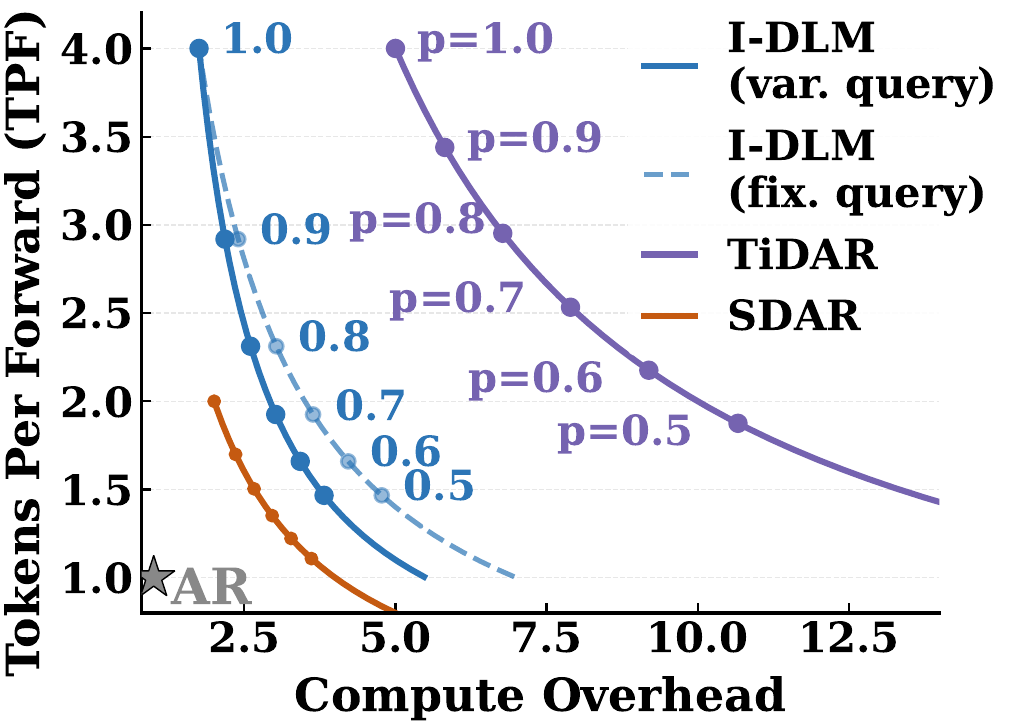
(2) Compute inefficiency. TiDAR: ~7.8x overhead vs. I-DLM: ~2.5x.
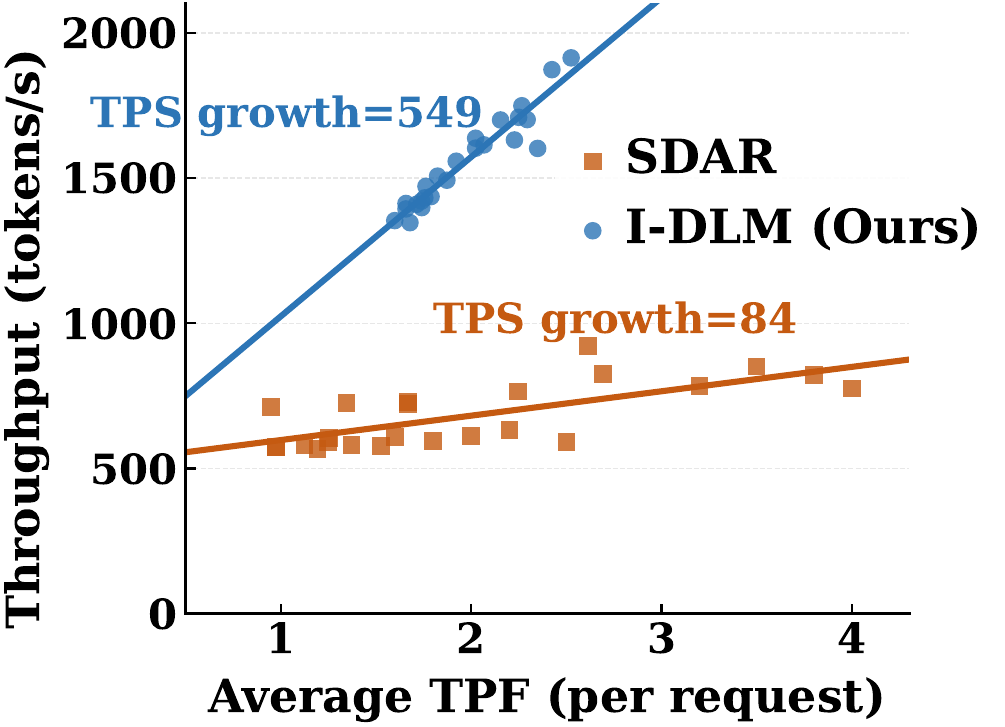
(3) Infrastructure mismatch. SDAR slope=84 vs. I-DLM: 549.
The I-DLM Method
Introspective-Consistency Training
Convert pretrained AR models via causal attention, logit shift, and an all-masked objective.
Introspective Strided Decoding
Generate N tokens per forward pass while verifying prior tokens via the p/q acceptance criterion.
AR-Compatible Serving
Strict causal attention enables direct integration into SGLang with no custom infrastructure.
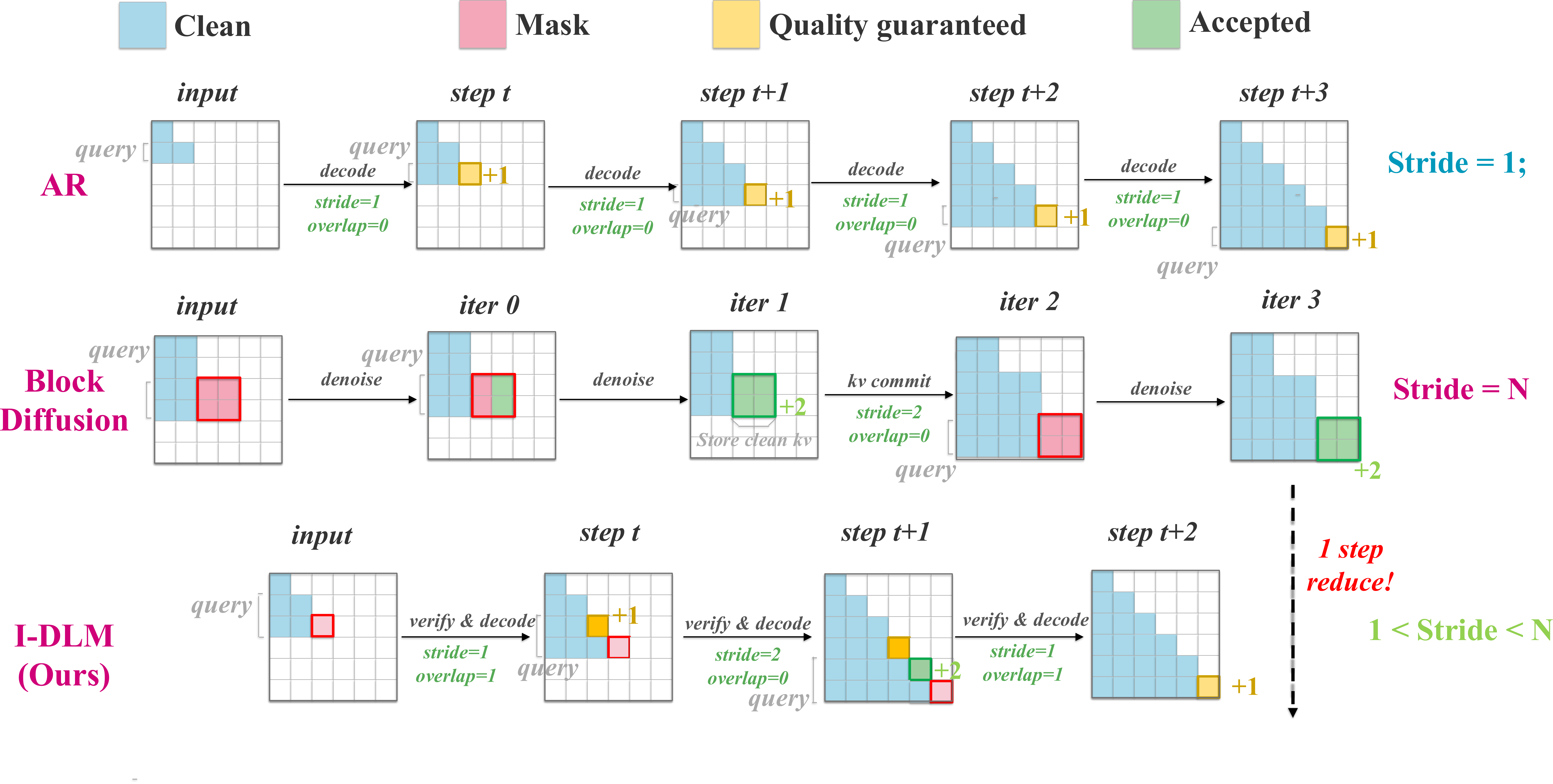
Decoding paradigm comparison. I-DLM is a drop-in replacement within AR serving infrastructure.
Results
I-DLM is the first DLM to match same-scale AR quality while surpassing all prior DLMs across 15 benchmarks.
End-to-End Quality
Blue = best non-AR <30B. Bold = best non-AR <100B.
| Qwen3 | Qwen3 | LLaDA-2.1 | LLaDA-2.0 | LLaDA-2.1 | SDAR | SDAR | Mercury | Gemini | I-DLM | I-DLM | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Knowledge & Reasoning | |||||||||||
| ARC-C | 95.8 | 97.2 | 90.2 | --- | --- | 91.9 | 93.2 | --- | --- | 95.8 | 96.8 |
| MMLU | 83.5 | 87.2 | 74.5 | --- | --- | 78.6 | 82.8 | --- | --- | 82.4 | 86.8 |
| MMLU-Pro | 75.1 | 80.1 | 64.8 | 74.8 | 76.6 | 56.9 | 61.5 | --- | --- | 73.1 | 79.7 |
| GPQA-D | 58.9 | 64.1 | 46.0 | --- | --- | 40.2 | 36.7 | --- | --- | 55.6 | 62.1 |
| GPQA | 55.4 | 65.0 | 53.3 | 62.3 | 67.3 | --- | --- | --- | --- | 54.9 | 58.7 |
| Math | |||||||||||
| GSM8K | 96.0 | 94.7 | 89.0 | --- | --- | 91.7 | 91.4 | --- | --- | 95.0 | 94.9 |
| MATH-500 | 95.8 | 97.8 | 85.0 | --- | --- | 78.6 | 77.8 | --- | --- | 96.8 | 97.6 |
| MathBench | 93.1 | 95.5 | 84.2 | --- | --- | 76.9 | 79.3 | --- | --- | 89.1 | 95.6 |
| AIME-24 | 73.1 | 76.7 | 43.3 | --- | --- | 10.0 | 16.7 | --- | --- | 69.6 | 83.3 |
| AIME-25 | 65.4 | 80.0 | 43.3 | 60.0 | 63.3 | 10.0 | 10.8 | --- | --- | 60.8 | 80.0 |
| Code | |||||||||||
| HumanEval | 95.1 | 96.3 | 86.0 | --- | --- | 78.7 | 87.2 | 90.0 | 89.6 | 93.3 | 96.3 |
| MBPP | 93.4 | 95.7 | 82.1 | --- | --- | 72.0 | 71.6 | 76.6 | 76.0 | 92.2 | 94.6 |
| LCB-v6 | 50.3 | 58.3 | 30.4 | 42.5 | 45.4 | 16.6 | 21.7 | --- | --- | 45.7 | 57.1 |
| Instruction Following | |||||||||||
| IFEval | 84.7 | 84.5 | 83.2 | 82.6 | 83.6 | 61.4 | 60.6 | --- | --- | 84.7 | 84.7 |
Throughput
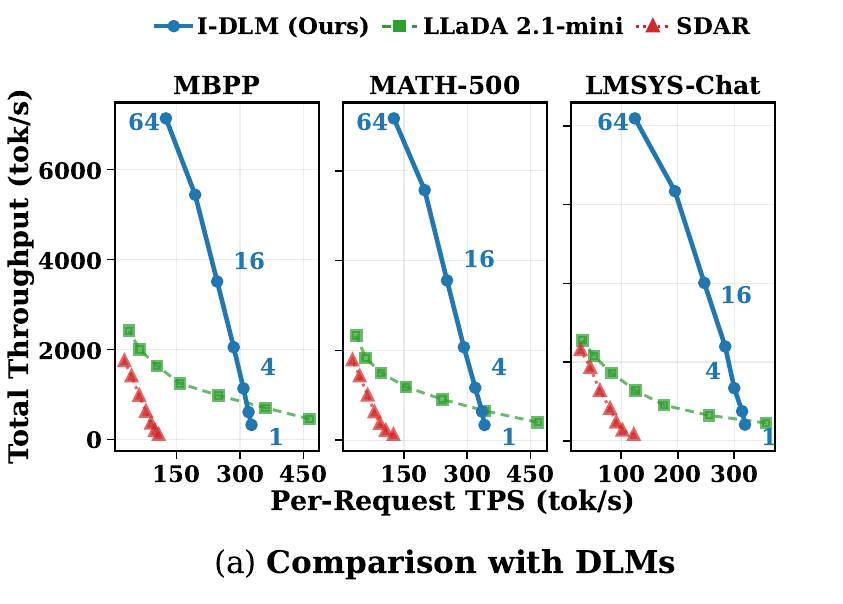
Throughput-latency tradeoff compared with DLMs across batch sizes (1, 4, 16, 64). I-DLM delivers 2.9-4.1x higher throughput than LLaDA-2.1-mini and SDAR at C=64.
Speedup Factor Explorer
In the memory-bound decode regime, TPF closely approximates wall-clock speedup: a TPF of 2.5 represents roughly 2.5x faster decoding than AR. Explore how acceptance rate and stride size affect this below.
0.90
1.12
Gated LoRA adds compute at MASK positions for bit-for-bit lossless output. α=1.12 matches empirical overhead.
Memory-bound: Speedup ≈ TPF = (2+p+...+pN-2) / (2-pN-1)
How do DLMs perform as they approach compute-bound?
At high concurrency, forward pass latency scales with query count per forward. We can measure compute efficiency as TPF²/query_size — how much useful output each FLOP produces relative to AR (efficiency = 1):
- SDAR (N=4, p=0.5): TPF ≈ 1.1, processes N=4 queries/forward → compute efficiency = 1.1²/4 ≈ 0.31. Each FLOP produces only 31% as much output as AR. This pushes SDAR into compute-bound early, and its throughput plateaus (batching efficiency slope = 84, see motivation figure).
- I-DLM (N=4, p=0.9): TPF ≈ 2.9, processes 2N−1=7 queries/forward → compute efficiency = 2.9²/7 ≈ 1.22. Each FLOP produces more useful output than AR — I-DLM stays in the memory-bound regime at concurrency levels where SDAR is already saturated (batching efficiency slope = 549).
Efficiency > 1 means parallel decoding actually saves total compute vs. AR. This is why I-DLM's throughput scales with concurrency while SDAR and LLaDA plateau in the throughput figure above.
Per-Position Acceptance Breakdown
Acceptance compounds geometrically: position k has probability $p^{k-1}$. Position 1 is always accepted (logit shift).
Documentation & Resources
Everything you need to train, serve, and deploy I-DLM. Click any card to expand.
Installation
git clone https://github.com/Introspective-Diffusion/I-DLM.git cd I-DLM/inference bash install.sh
See inference/README.md for detailed environment setup.
Quick Start
1. Launch server:
python -m sglang.launch_server \
--model-path yifanyu/I-DLM-8B \
--trust-remote-code --tp-size 1 --dtype bfloat16 \
--mem-fraction-static 0.85 --max-running-requests 32 \
--attention-backend flashinfer --dllm-algorithm IDLMBlockN \
--dllm-algorithm-config inference/configs/idlm_blockN4_config.yaml \
--port 30000
2. Generate:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "default",
"messages": [{"role": "user", "content": "Prove that sqrt(2) is irrational."}],
"max_tokens": 4096, "temperature": 1.0
}'
Training
Convert a pretrained AR model into I-DLM via introspective-consistency training:
- Input: Concatenate fully-masked sequence with clean sequence
[x_t | x_0] - Attention: Strict causal masking across all positions
- Loss: Auto-balanced CE on both masked and clean positions
- Data: 4.5B tokens, 8 H100 GPUs, 2 epochs with stride curriculum (N=2 then N=3)
See training/README.md for scripts and configs.
Inference & ISD
Introspective Strided Decoding (ISD) generates and verifies in a single forward pass:
- MASK positions: Propose new tokens (distribution q)
- Clean positions: Verify prior tokens (anchor distribution p)
- Acceptance:
min(1, p(x)/q(x))guarantees AR-distribution output - Stride N=4: TPF=2.96, ~3x wall-clock speedup in memory-bound regime
See inference/README.md for algorithm configs.
Serving (SGLang)
I-DLM uses strict causal attention, enabling direct integration into SGLang with no custom infrastructure:
- Paged KV cache and continuous batching
- CUDA graph capture (+42-76% throughput)
- Stationary-batch decode-loop scheduling (+11-21%)
- Argmax proposals (+11-15%)
- Paged-only attention kernel (+10-14%)
Full system achieves 2.1-2.5x throughput over naive baseline.
Lossless R-ISD
Residual ISD (R-ISD) adds a gated LoRA adapter for bit-for-bit lossless acceleration:
- LoRA active only at MASK positions; verify positions use base-only weights
- Output is identical to the base AR model by construction
- LoRA rank=128, overhead factor ~1.12x
- Model: yifanyu/I-DLM-8B-lora-r128
Model Zoo
| Model | Base | Description |
|---|---|---|
| I-DLM-8B | Qwen3-8B | Main model, matches AR quality |
| I-DLM-32B | Qwen3-32B | Large scale, outperforms LLaDA-2.1-flash (100B) |
| I-DLM-8B-LoRA | Qwen3-8B | Gated LoRA (rank=128) for lossless R-ISD |
All models use trust_remote_code=True (custom SDARForCausalLM architecture).
Benchmarks
We evaluate on 15 benchmarks across 4 categories with thinking mode enabled:
- Knowledge: ARC-C, MMLU, MMLU-Pro, GPQA-D, GPQA
- Math: GSM8K, MATH-500, MathBench, AIME-24, AIME-25
- Code: HumanEval, MBPP, LiveCodeBench-v6
- Instruction: IFEval
See inference/eval/ for reproduction scripts.
Citation
@article{yu2026introspective,
title={Introspective Diffusion Language Models},
author={Yu, Yifan and Jian, Yuqing and Wang, Junxiong and Zhou, Zhongzhu
and Zhuang, Donglin and Fang, Xinyu and Yanamandra, Sri
and Wu, Xiaoxia and Wu, Qingyang and Song, Shuaiwen Leon
and Dao, Tri and Athiwaratkun, Ben and Zou, James
and Lai, Fan and Xu, Chenfeng},
journal={arXiv preprint arXiv:7471639},
year={2026}
}
© 2025 I-DLM Team. Built with care.