Today, we are introducing Kimi K2.5, the most powerful open-source model to date.
Kimi K2.5 builds on Kimi K2 with continued pretraining over approximately 15T mixed visual and text tokens. Built as a native multimodal model, K2.5 delivers state-of-the-art coding and vision capabilities and a self-directed agent swarm paradigm.
For complex tasks, Kimi K2.5 can self-direct an agent swarm with up to 100 sub-agents, executing parallel workflows across up to 1,500 tool calls. Compared with a single-agent setup, this reduces execution time by up to 4.5x. The agent swarm is automatically created and orchestrated by Kimi K2.5 without any predefined subagents or workflow.
Kimi K2.5 is available via Kimi.com, the Kimi App, the API, and Kimi Code. Kimi.com & Kimi App now supports 4 modes: K2.5 Instant, K2.5 Thinking, K2.5 Agent, and K2.5 Agent Swarm (Beta). Agent Swarm is currently in beta on Kimi.com, with free credits available for high-tier paid users.
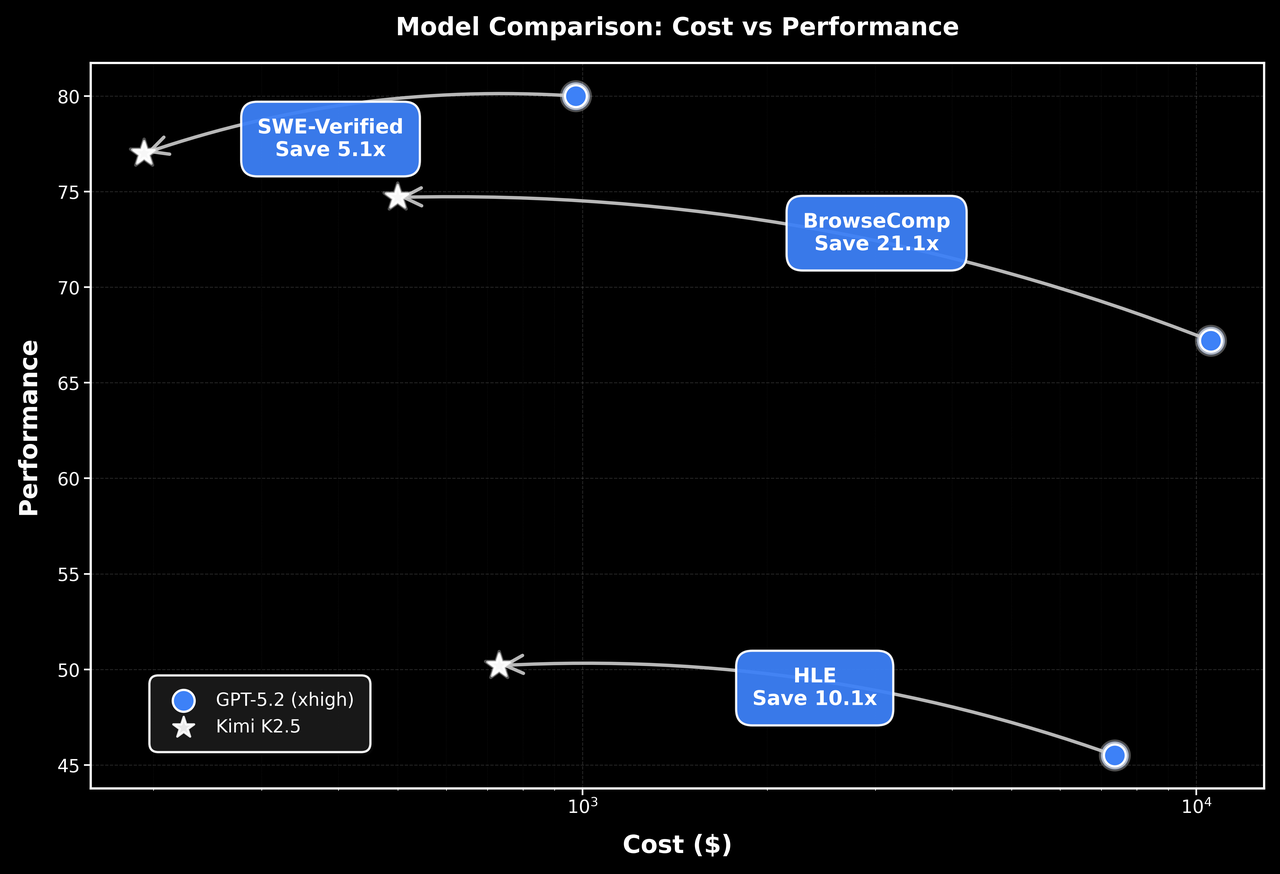
Across three agentic benchmarks—HLE, BrowseComp, and SWE-Verified—Kimi K2.5 delivers strong performance at a fraction of the cost.
1. Coding with Vision
Kimi K2.5 is the strongest open-source model to date for coding, with particularly strong capabilities in front-end development.
K2.5 can turn simple conversations into complete front-end interfaces, implementing interactive layouts and rich animations such as scroll-triggered effects. Below are examples generated by K2.5 from a single prompt with image-gen tool:
Beyond text prompts, K2.5 excels at coding with vision. By reasoning over images and video, K2.5 improves image/video-to-code generation and visual debugging, lowering the barrier for users to express intent visually.
Here is an example of K2.5 reconstructing a website from video:
This capability stems from massive-scale vision-text joint pre-training. At scale, the trade-off between vision and text capabilities disappears — they improve in unison.
Below is an example of K2.5 reasoning over a puzzle and marking the shortest path using code:
K2.5 excels in real-world software engineering tasks. We evaluate it using Kimi Code Bench, our internal coding benchmark covering diverse end-to-end tasks — from building to debugging, refactoring, testing, and scripting — across multiple programming languages. On this benchmark, K2.5 shows consistent and meaningful improvements over K2 across task types.

To try out K2.5's agentic coding capabilities, K2.5 Agent offers a set of preconfigured tools for immediate, hands-on experiences. For software engineering use cases, we recommend pairing Kimi K2.5 with our new coding product, Kimi Code.
Kimi Code works in your terminal and can be integrated with various IDEs including VSCode, Cursor, Zed, etc. Kimi Code is open-sourced and supports images and videos as inputs. It also automatically discovers and migrates existing skills and MCPs into your working environment in Kimi Code.
Here's an example using Kimi Code to translate the aesthetic of Matisse's La Danse into the Kimi App. This demo highlights a breakthrough in autonomous visual debugging. Using visual inputs and documentation lookup, K2.5 visually inspects its own output and iterates on it autonomously. It creates an art-inspired webpage created end to end:
2. Agent Swarm
Scaling Out, Not Just Up. We release K2.5 Agent Swarm as a research preview, marking a shift from single-agent scaling to self-directed, coordinated swarm-like execution.
Trained with Parallel-Agent Reinforcement Learning (PARL), K2.5 learns to self-direct an agent swarm of up to 100 sub-agents, executing parallel workflows across up to 1,500 coordinated steps, without predefined roles or hand-crafted workflows.
PARL uses a trainable orchestrator agent to decompose tasks into parallelizable subtasks, each executed by dynamically instantiated, frozen subagents. Running these subtasks concurrently significantly reduces end-to-end latency compared to sequential agent execution.
Training a reliable parallel orchestrator is challenging due to delayed, sparse, and non-stationary feedback from independently running subagents. A common failure mode is serial collapse, where the orchestrator defaults to single-agent execution despite having parallel capacity. To address this, PARL employs staged reward shaping that encourages parallelism early in training and gradually shifts focus toward task success.
We define the reward as
where
To further force parallel strategies to emerge, we introduce a computational bottleneck that makes sequential execution impractical. Instead of counting total steps, we evaluate performance using Critical Steps, a latency-oriented metric inspired by the critical path in parallel computation:
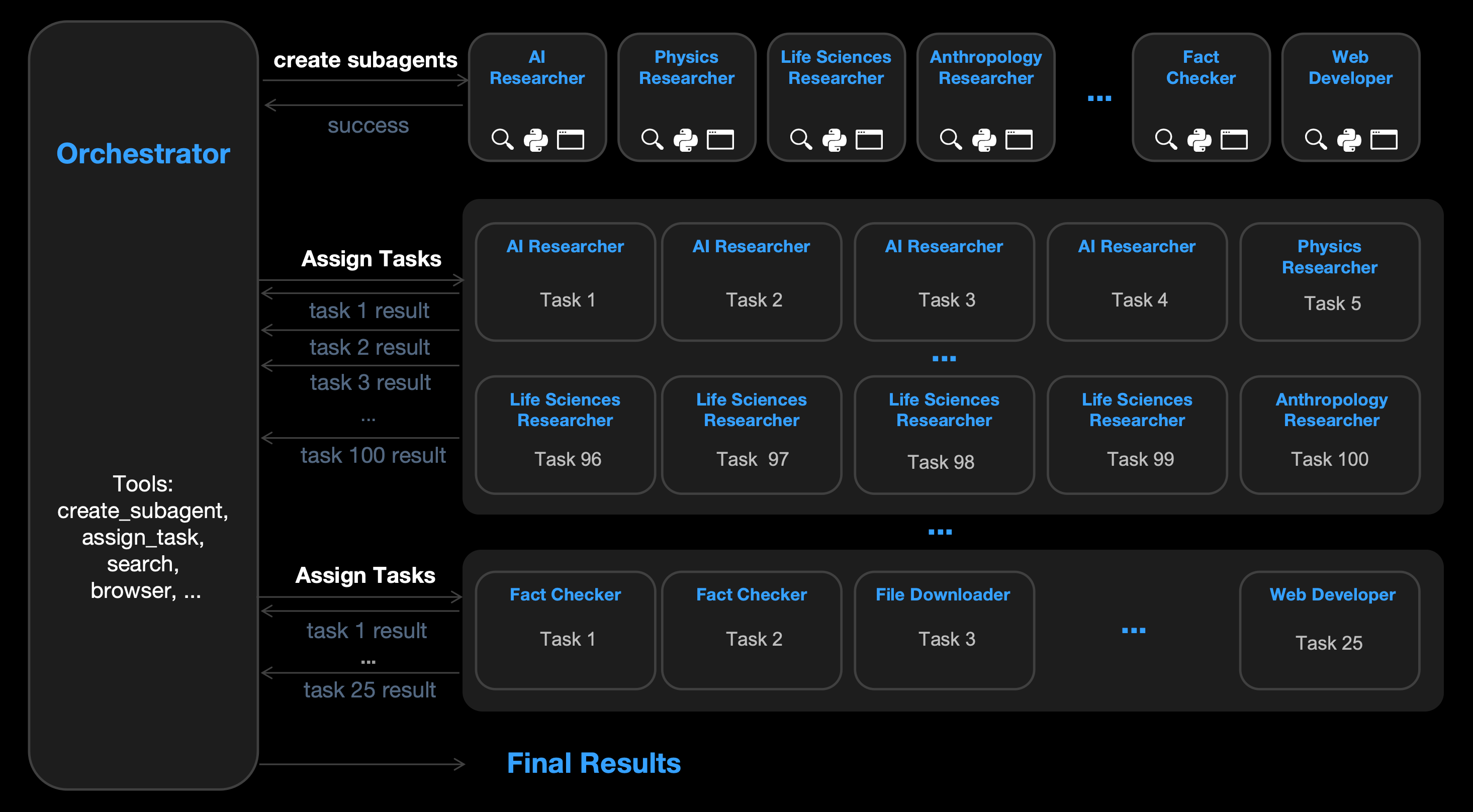
An agent swarm has an orchestrator that dynamically creates specialized subagents (e.g., AI Researcher, Physics Researcher, Fact Checker) and decomposes complex tasks into parallelizable subtasks for efficient distributed execution.
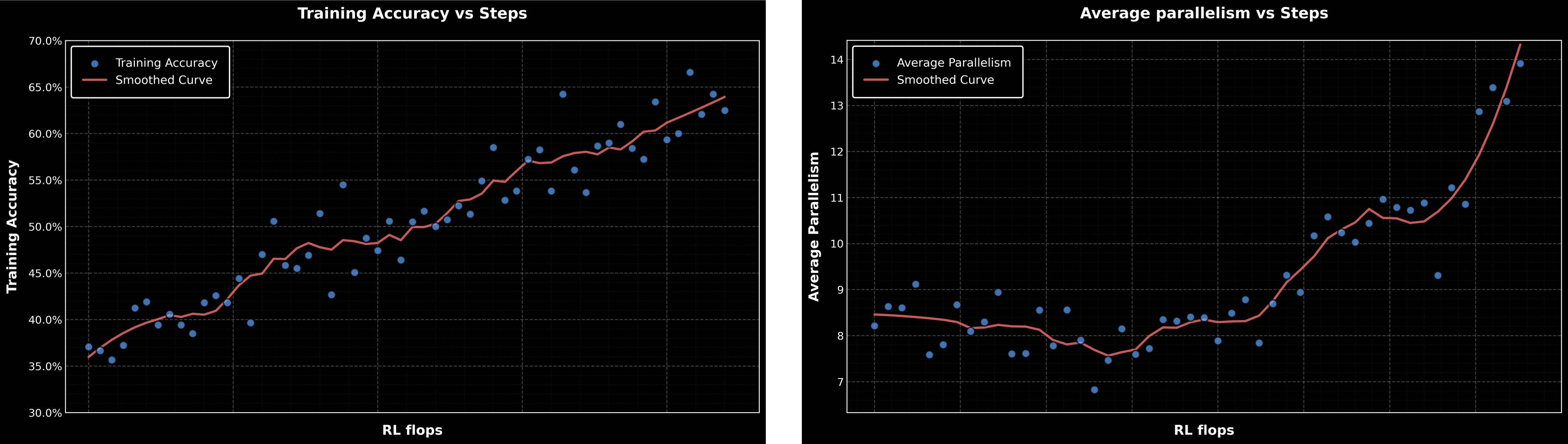
In our parallel-agent reinforcement learning environment, the reward increases smoothly as training progresses. At the same time, the level of parallelism during training also gradually increases.
K2.5 Agent Swarm improves performance on complex tasks through parallel, specialized execution. In our internal evaluations, it leads to an 80% reduction in end-to-end runtime while enabling more complex, long-horizon workloads, as shown below.
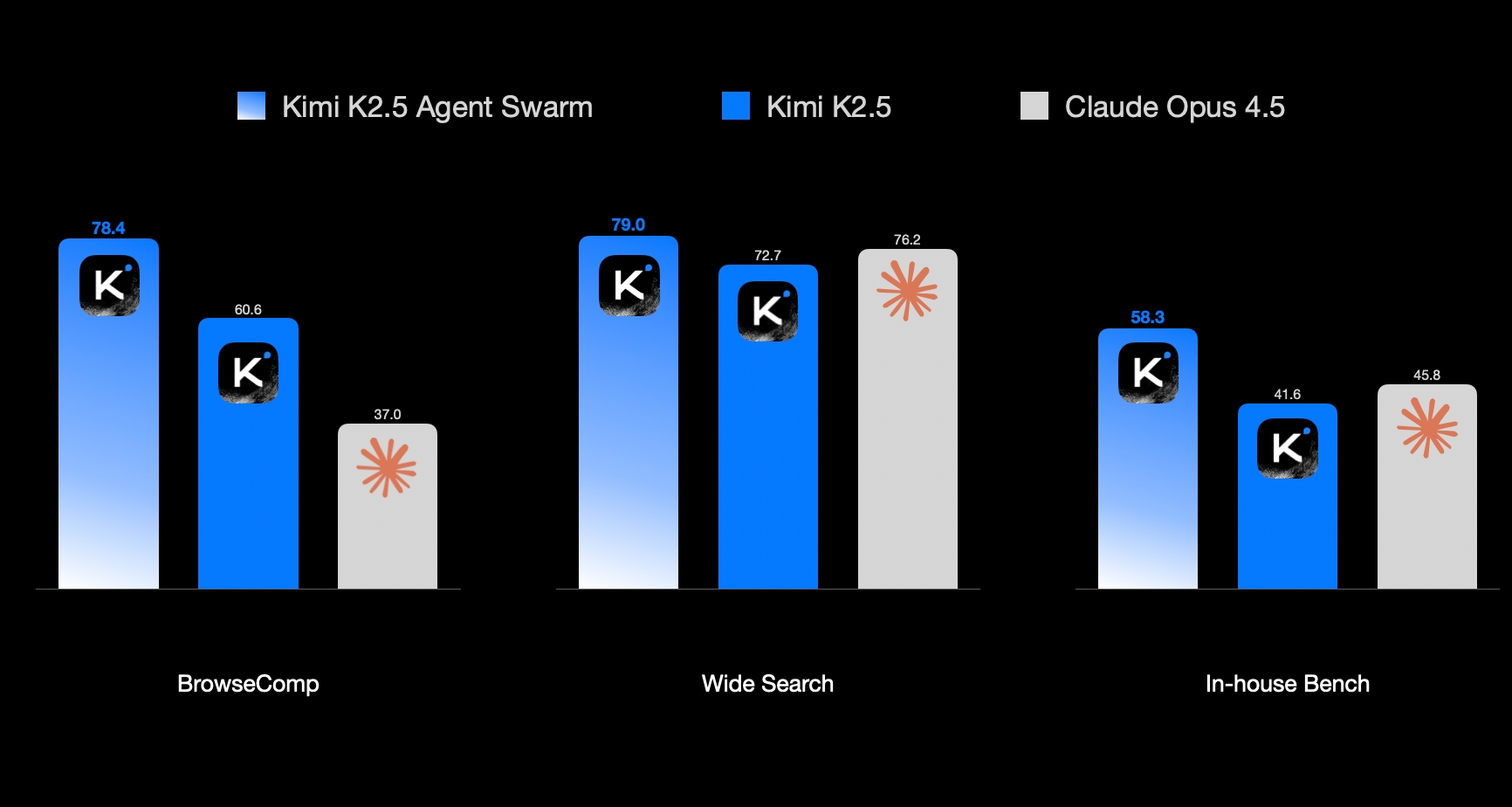
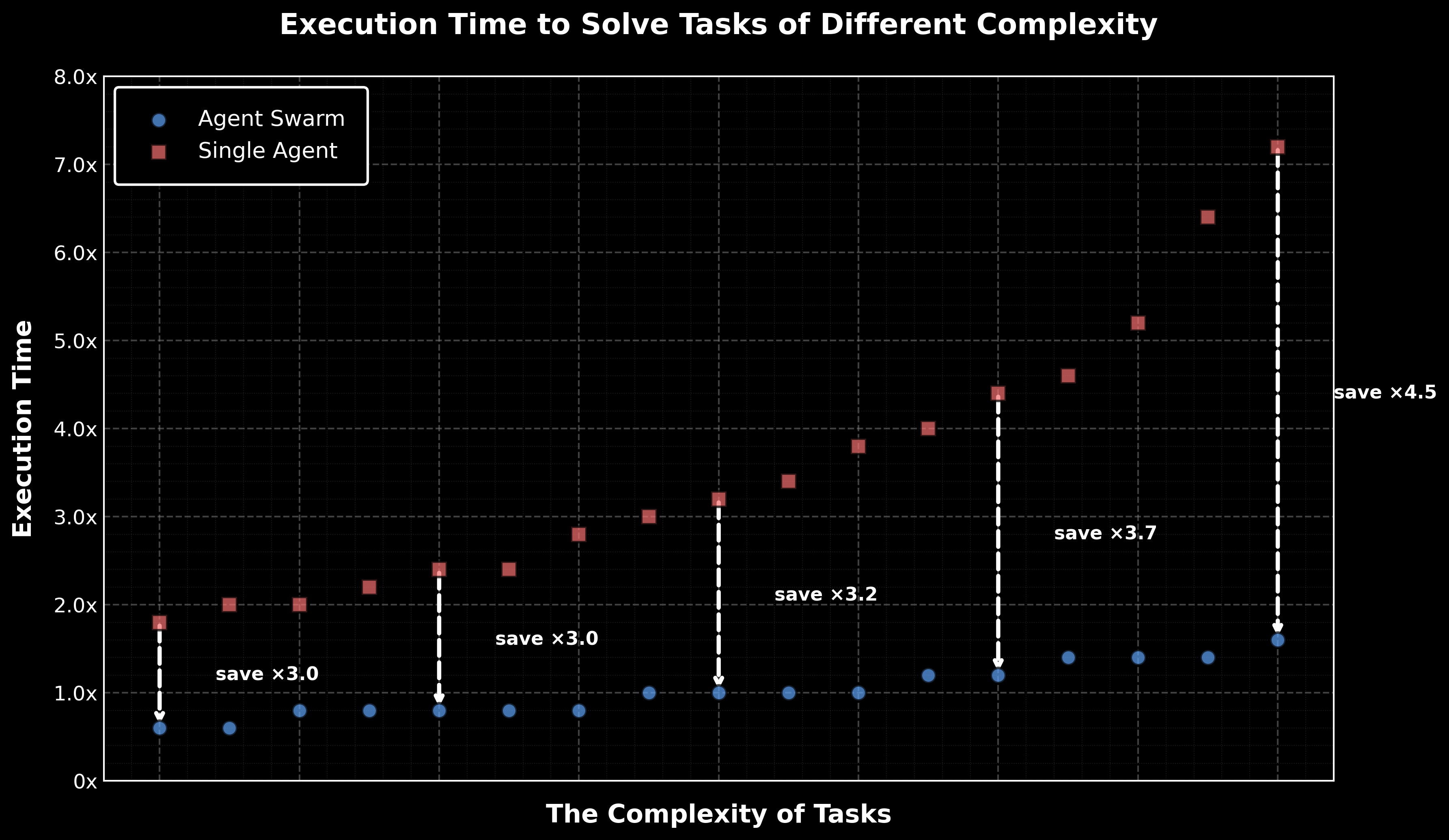
Agent Swarm reduces the minimum critical steps required to achieve target performance by 3×–4.5× compared to single-agent execution in wide search scenario, with savings scaling as targets rise—translating to up to 4.5× wall-clock time reduction via parallelization.
Here are representative trajectories demonstrating K2.5 Agent Swarm in action:
3. Office Productivity
Kimi K2.5 brings agentic intelligence into real-world knowledge work.
K2.5 Agent can handle high-density, large-scale office work end to end. It reasons over large, high-density inputs, coordinates multi-step tool use, and delivers expert-level outputs: documents, spreadsheets, PDFs, and slide decks—directly through conversation.
With a focus on real-world professional tasks, we design two internal expert productivity benchmarks. The AI Office Benchmark evaluates end-to-end Office output quality, while the General Agent Benchmark measures multi-step, production-grade workflows against human expert performance. Across both benchmarks, K2.5 shows 59.3% and 24.3% improvements over K2 Thinking, reflecting stronger end-to-end performance on real-world tasks.
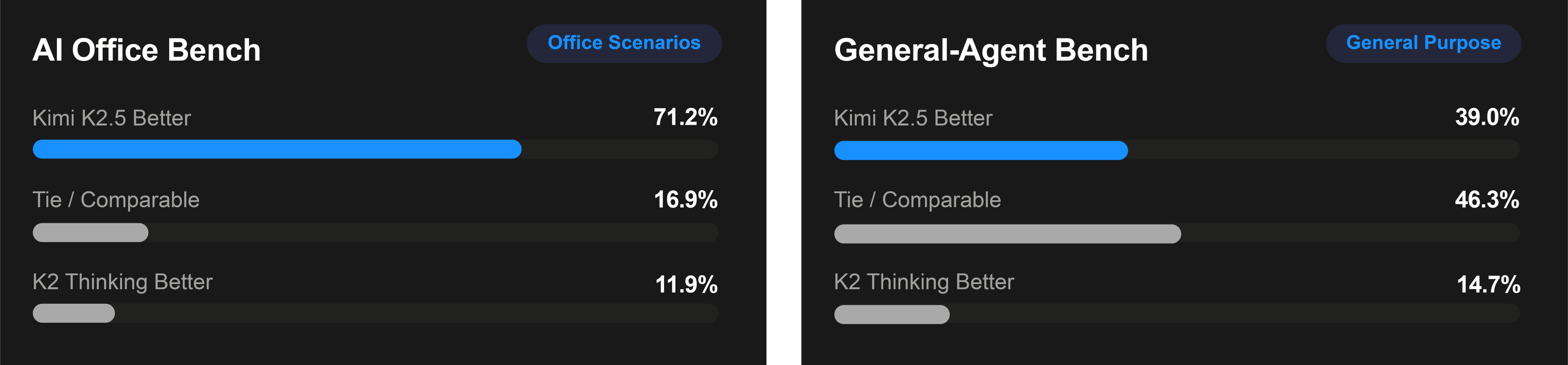
Internal Expert Productivity Bench (AI Office)