Introduction
Over the past few years, image generation has seen remarkable progress. Diffusion and flow-matching models can generate high-resolution images, produce sharp photorealism and stable structure, render dense text, encode broad world knowledge, and follow user prompts in precise detail. These improvements have been driven by several interacting factors including scalable transformers architectures, improved captioning and text encoders, better latent representations, and pipelined post-training techniques. Yet as the field has optimized for reliability on these capabilities, many systems have converged toward a narrow set of default aesthetics. While effective production tools, this makes them less effective as engines for creative exploration, where users often need to search across styles, moods, compositions and visual directions rather than receive a single polished default.
To address these limitations, we present Krea 2, a series of foundation models focused on creative exploration. Krea 2’s models are built on the belief that image generation should be an exploratory medium: expressive enough to span many aesthetics, and controllable enough for creators to navigate them.
We built a large-scale data infrastructure and distributed training framework from scratch to curate a comprehensive pretraining dataset with broad world knowledge and style coverage.
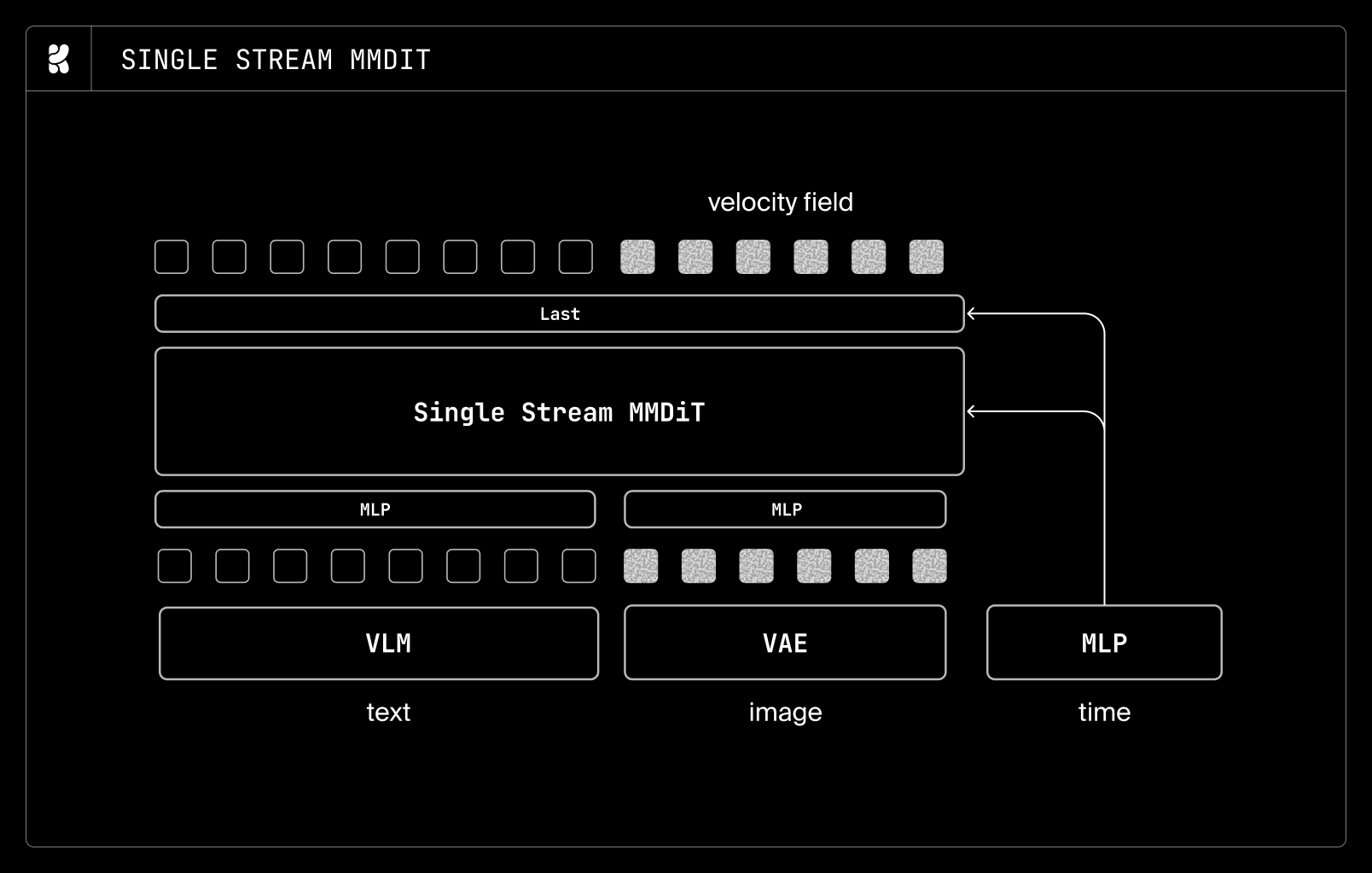
Using this infrastructure, we train expressive models through a multi-stage pipeline spanning pretraining, midtraining, supervised finetuning (SFT), preference optimization, and reinforcement learning (RL), with each stage designed to progressively refine the model’s output distribution. We develop a simple yet performant diffusion transformer (DiT) architecture through thorough ablations. Our model incorporates several components that accelerate convergence , including iREPA, improved VAEs, and Qwen3-VL. We also integrate several architectural improvements, including grouped-query attention (GQA), sigmoid-gated attention, lightweight timestep modulation, and multilayer feature aggregation for text-encoder features, which together improve training stability and efficiency.
A strong base model is only useful if users can reliably reach the parts of its distribution they care about. In training, the model learns from rich, carefully constructed captions that describe images with dense visual detail. In practice, user inputs are often shorter, more ambiguous, and shaped by many different habits of expression. Some users describe a scene in natural language; others gesture toward a mood, a style, or a reference image. This creates a gap between the model’s learned conditioning space and the way creative intent is expressed at inference time.
To reduce this gap, we build two systems that make Krea 2 more exploratory and steerable from both text and image inputs: a prompt expander and a style-reference system. The prompt expander maps simple or underspecified user prompts into richer visual directions without overwriting the user’s intent. It is trained through a two-stage SFT and RL pipeline on top of open-source LLMs, where the objective is not only to improve image quality, but also to encourage creative variation and controllable exploration. Complementing this textual interface, the style-reference system lets users express visual intent through images when words are insufficient. It allows users to inject the style or mood of one or more reference images with minimal content leakage, while providing fine-grained control over style strength and weighted style mixing.
Together, these components define Krea 2 as a foundation model for exploratory generation. Instead of optimizing only for a single polished default, Krea 2 is designed to expose a broad visual space and give users practical ways to move through it, using both text and image-based control. Krea 2 is among the top 10 models on the the Artificial Analysis leaderboard for text-to-image, and scores 2nd place among models from independent labs. Krea 2 serves as a comprehensive baseline and enables a creative generative experience while maintaining competitive performance.
Data
Data Curation Principles
Before detailing our data pipeline, it is important to establish what constitutes a good data mix for our purpose. A good mix does not consist solely of “high quality” images. Diversity and broad domain coverage are essential given our objective of building an expressive, stylistically diverse model. We argue that conventional model-based filtering, which uses aesthetic-score and image-quality-assessment (IQA) models, introduces implicit biases. For example, such methods may classify a blurry image as low quality, even though motion blur or softness can be a deliberate artistic choice.
Furthermore, we argue that as long as a caption accurately describes its image, even an undesirable image may be helpful in downstream use cases: because the model precisely understands the undesired behavior, such samples can later be used to steer generations away from that distribution.
For these reasons, we build the pretraining dataset by filtering out only:
- Duplicated samples and over-represented concepts.
- Samples for which VLMs consistently fail to capture important aspects of the image.
- Samples that induce undesired biases and artifacts.
- Samples with high visual complexity that is too difficult to model reliably at low resolution.
- AI-generated samples
These conditions shape a pretraining dataset with broad coverage while avoiding poor text-to-image alignment and artifacts.
Importantly, we use no AI-generated images in our pretraining mix. Synthetic data and distillation can be an effective shortcut for acquiring model capabilities. However we find that even a small proportion of AI-generated images introduces biases into the model’s output distribution, as synthetic images tend to be easier to learn, which effectively imposes an upper bound on model quality. We therefore designed in-house classifiers to filter such images out.
Captioning
We employ a multi-stage approach to produce captions. First, we run an OCR model on each target image to extract any visible text. In the second stage, we provide both the OCR results and any available metadata (camera settings, known entities, and so on) to the captioning model, which produces an enriched caption that incorporates world knowledge alongside the extracted text.
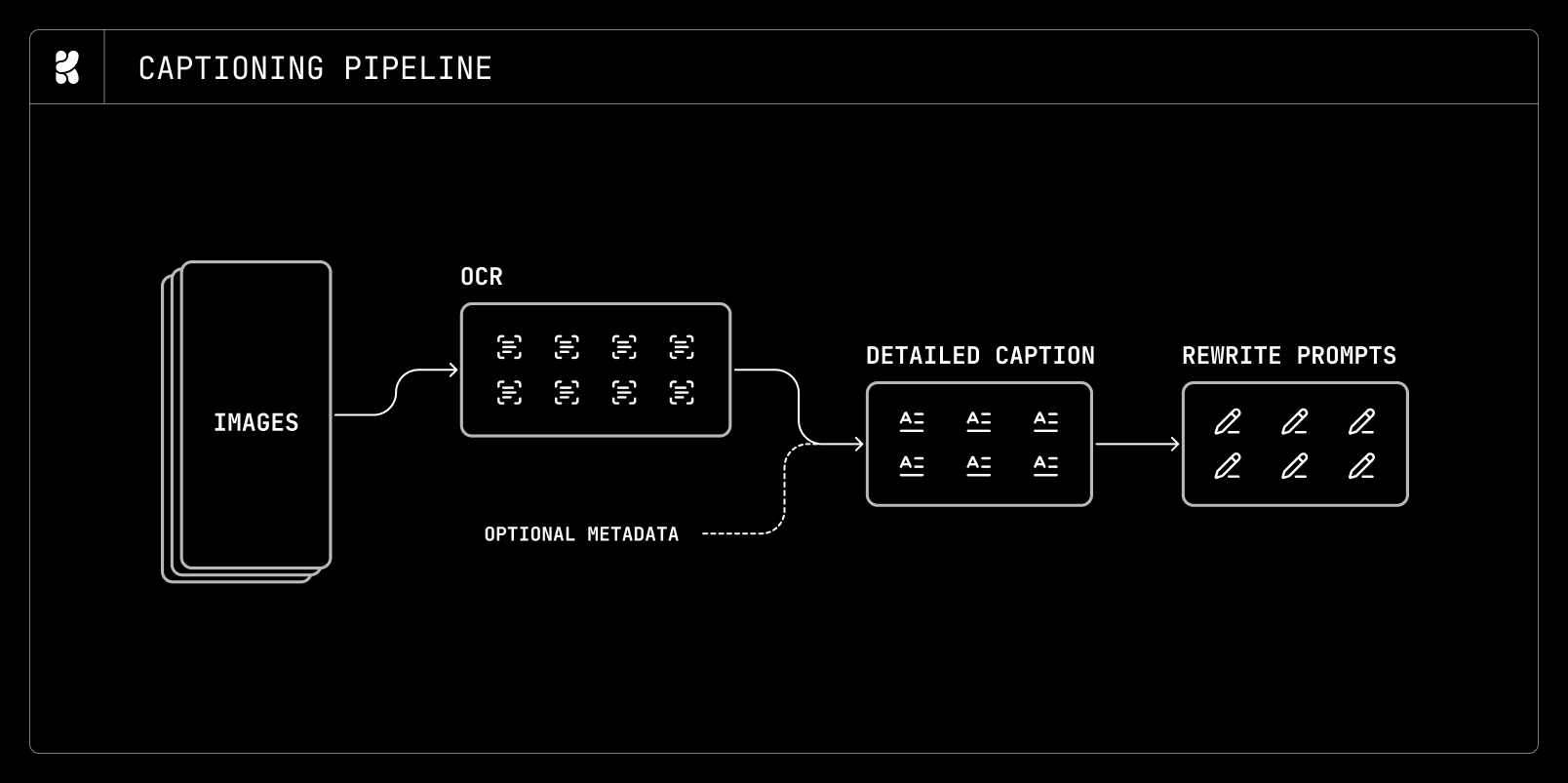
General captioning pipeline
Once a context-rich, long-form natural-language caption is obtained, we use a cheaper LLM to reformat it into a variety of lengths and formats, exposing the model to a range of prompt styles. Empirically, we find that training on long prompts provides dense supervision, yielding faster convergence and lower training loss. For many downstream and applied use cases, however, performance on short and medium-length prompts remains important. We therefore train predominantly on long captions while ensuring the model is exposed to short and medium-length prompts throughout training.
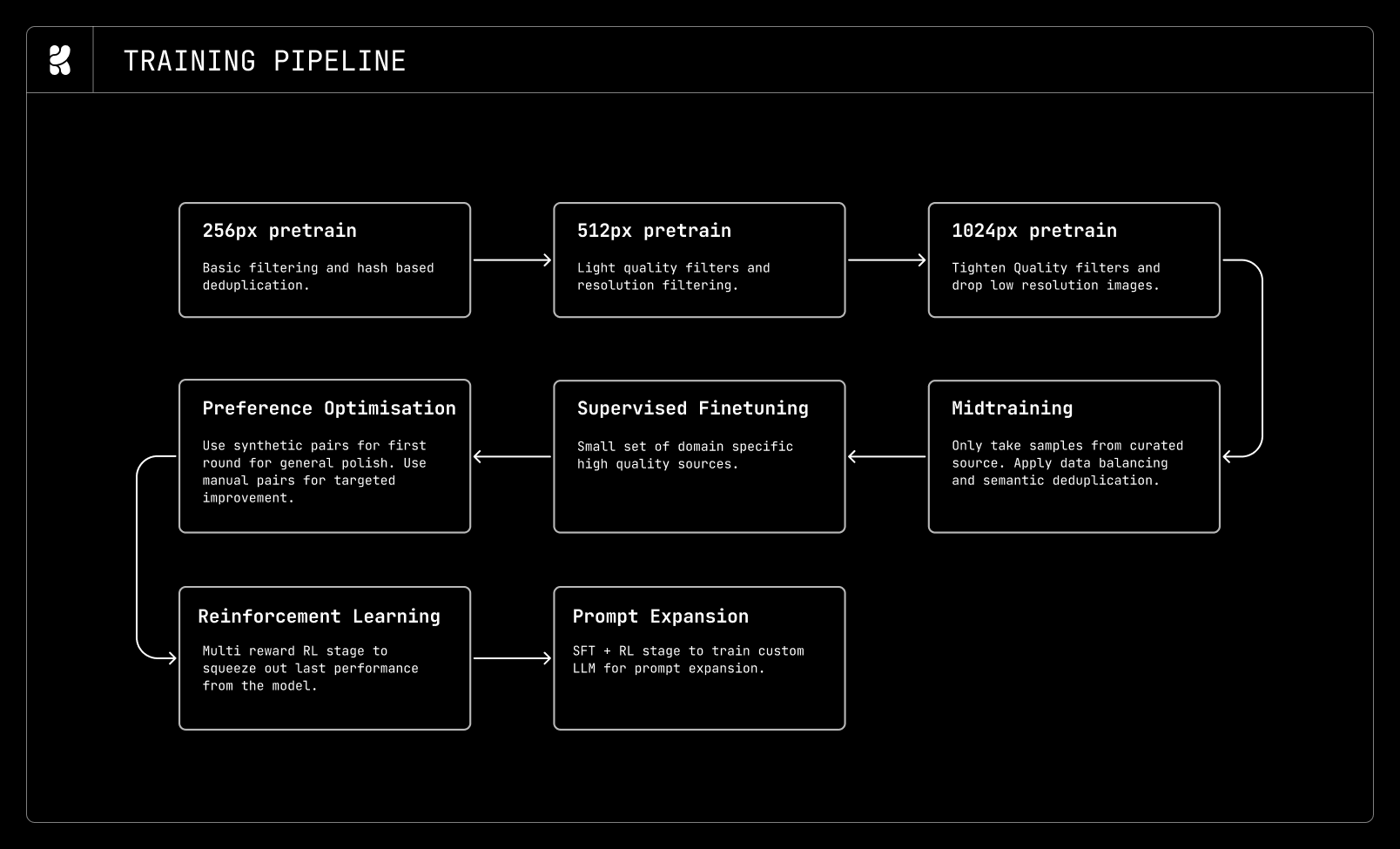
Our overall training pipeline and data stages
Pretraining Data
Pretraining data spans 256px, 512px, and 1024px resolution stages. Progressively scaling the resolution forms a curriculum-learning strategy: we dedicate the majority of FLOPs to the low-resolution stages to build core model capabilities efficiently, then equip the model with high-fidelity generation capabilities as the training resolution increases.
Low-resolution pretraining is the stage at which basic text-image alignment and structure are learned. At this stage the dataset is on the order of billions of images, so we rely heavily on inexpensive CPU-based filters to remove low-quality images. These range from simple broken-file, resolution, and aspect-ratio filters that remove unqualified images, to Laplacian filters that remove images with extreme textures and noise patterns.
As an example, one issue we encountered while pretraining K2 was a tendency for the model to generate flat-color backgrounds and border artifacts. To mitigate this, we used RGB entropy, white/black pixel ratios, custom heuristics, and in-house classifiers to filter out samples that induced this behavior.
Building an in-house classifier, one effective strategy was to use a large VLM to craft a task-specific system prompt for the filtering task (for example, detecting a specific pattern or artifact), produce a pseudo-labeled dataset, and then train a small DINOv3- or SigLIP-2-based classifier to run the filter at scale. Any filtering model that requires GPU compute at the low-resolution stage is kept under 1B parameters for efficiency.
For deduplication at the low-resolution stages, we primarily use inexpensive hash-based methods, combining md5, phash, and colorhash to remove duplicate images with minimal compute. We find that the default 8x8 phash does not account for color and has a high false-positive rate; we therefore combine a 12x12 phash with colorhash for more robust deduplication.
As we scale the training resolution, we introduce image-quality and aesthetic filters. Importantly, these quality scores are used only to drop images of extremely poor quality, not to oversample images on the basis of their scores. We additionally use an image-complexity score and text density (from OCR results) to exclude images whose text and content cannot be meaningfully represented at low resolution. We adjust the quality, complexity, and text-density thresholds as training progresses.
Beyond conventional quality filters, we also train a sparse autoencoder (SAE) on SigLIP-2 embeddings computed over a sample of our pretraining corpus. After training the SAE, we use a VLM to annotate each SAE feature based on its top-k activating samples. These annotated features form an unsupervised tagging system in which we extract the predominant SAE features from each image. This tagging system was useful for filtering clear visual artifacts without training an explicit classifier.
Midtraining Data
Unlike the pretraining stages, midtraining explicitly selects specific image sources known to offer good stylistic coverage and high-quality images for particular visual domains. Whereas pretraining is a bottom-up process that begins from a general pool, midtraining data is curated top-down: the domains and sources are chosen first. Midtraining is a crucial stage that smoothly bridges the general pretraining distribution and the high-quality SFT distribution. To improve the quality of the distribution, we introduce semantic clustering and use retrieval-based strategies to ensure world-knowledge coverage.
Building on the approach in Automatic Data Curation for Self-Supervised Learning, we use FAISS to perform hierarchical k-means clustering, which we then sample so as to retain long-tail visual concepts without wasting compute over-sampling head concepts. After computing the hierarchical clusters, we have a VLM examine the images nearest each cluster centroid in order to name and, where appropriate, flag the cluster. Following human review of the flagged clusters, we dropped several that were low quality or problematic. We remove further redundant data through semantic deduplication, computing the SigLIP similarity between images within each remaining leaf cluster.
An important capability of image generation models is faithfully representing known entities that users may reference simply by name. Some entities, such as sports players or actors, can fall into semantic clusters containing many other entities, which risks their being dropped under straightforward hierarchical sampling. To address this, we ran PageRank over English Wikipedia using Danker and retained the top 90% of articles by rank. We then filtered out all articles describing unrepresentable subjects based on their Wikidata metadata, and for the remaining ~5 million concepts we performed a full-text search across all captions in our dataset to assess coverage. When sampling, we prioritized images whose captions referenced rare concepts. Finally, we repeated this coverage analysis on the resulting sample to confirm that no concepts present in the initial dataset had been dropped entirely.
Supervised Finetuning Data
For the supervised finetuning (SFT) stage, we use a small, hand-curated dataset focused on individual visual domains. We find that, once a sufficient volume is reached, the quality of the dataset matters far more than its scale.
Architecture
For our architectural ablations, we found it useful to classify each ablation’s objective into one of the following categories:
- Stability: Does it make training more stable? Does it reduce loss and gradient spikes?
- Performance: Does it make the model converge faster? If so, does the trend hold over an extended horizon and at higher resolution?
- Efficiency: Does it reduce parameter count, FLOPs, memory, or communication requirements without compromising model quality?
- Simplicity: Can we make the model simpler without affecting the other categories?
It is worth noting that many of our architectural decisions are guided by their adoption in the LLM space. Choosing an architecture that is well established in the LLM ecosystem allows us to take advantage of existing kernels and optimizations, even for diffusion models.
With these objectives in mind, we begin from the following baseline.
| Component | Baseline | Ablations | Final component |
|---|---|---|---|
| Attention | Multi head attention | GQA, MLA, Gated Sigmoid attention | GQA with gated sigmoid attention |
| MLP | GeLU MLP | SwiGLU | SwiGLU |
| Residual | Standard residual | Value residual, Laurel | Standard residual |
| Text encoder | T5-XXL encoder | T5Gemma, Qwen 2.5 VL, Qwen 3 VL, umT5 | Qwen 3 VL |
| Modulation | MLP modulation per block | Light modulation with bias | Light modulation with bias |
| Autoencoder | FLUX AE | Qwen Image VAE, DC-AE, FLUX 2 AE, Internal VAE | Qwen Image VAE & FLUX 2 AE |
| Block design | Single stream transformer block | Hybrid Stream, Parallel single stream, | Single stream transformer block |
| Norm | Layer normalisation, QKNorm | RMSNorm, Zero center RMSNorm, Derf | Zero center RMSNorm, QKNorm |
| Positional encoding | 3D Axial RoPE | Golden Gate RoPE, MRoPE, Normalised RoPE, Partial RoPE | 3D Axial RoPE |
Transformer block
We begin by replacing the GeLU MLP with SwiGLU layers at a 4x expansion factor, which have become a de facto module in LLM architectures. Introducing SwiGLU led to consistent performance gains, so we adopted it across all subsequent ablations.
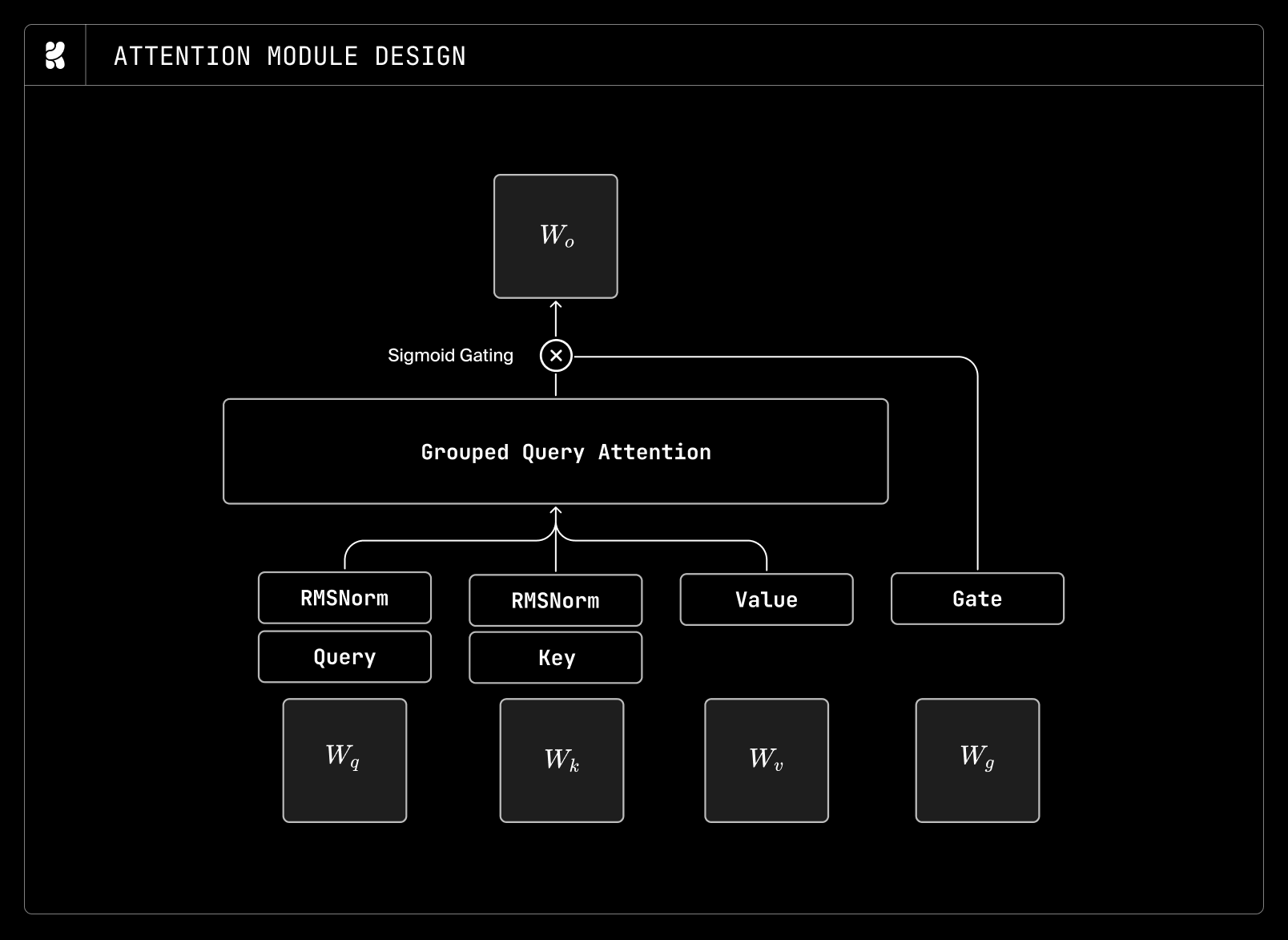
Having revised the MLP design, we considered GQA, MLA, and gated sigmoid attention as alternatives to the multi-head attention baseline. We find that GQA introduces minimal degradation while offering improved computational efficiency. We also explored MLA and observed slight gains over GQA, but did not adopt it, as it introduced additional computational overhead. We used MLA with up/down projection for KV compression and without decoupled RoPE, since diffusion is purely prefill and does not use a KV cache at inference.
On top of GQA, we add gated sigmoid attention, following Gated Attention for Large Language Models. Gated sigmoid attention adds very little compute and parameter overhead. While it did not yield significant performance gains, it produced more stable training dynamics, as reflected in the loss and gradient-norm curves throughout training.
We also ablate the modality-stream design:
- Single-stream design: a standard transformer block in which the attention and MLP weights are shared between text and image tokens.
- Dual-stream design: joint attention with separate attention and MLP weights for text and image tokens.
- Hybrid-stream design: a mix of the two, using dual-stream blocks for the first third of the network and single-stream blocks for the remaining two-thirds.
We did not observe significant performance differences among the three designs, with the exception of the hybrid-stream design, which slightly outperformed the others. For the sake of simplicity, however, we use single-stream blocks in our final architecture.
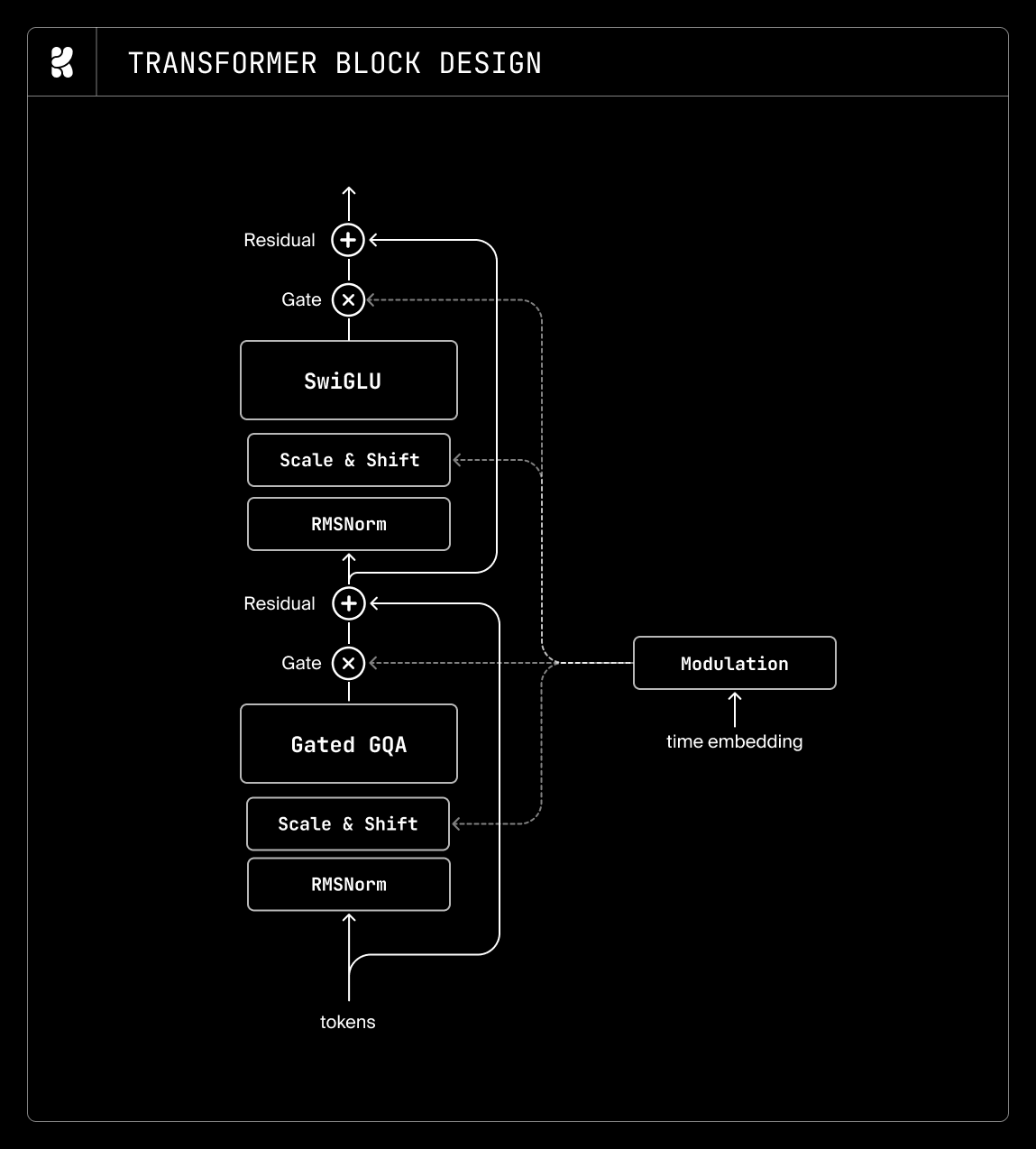
Timestep conditioning
Many MMDiTs use a per-block MLP to produce scale, shift, and gate factors. These MLP blocks can account for 20—30% of the total parameter count, which we consider excessive for injecting a scalar condition. We therefore replace the per-block MLP with a per-block tunable bias term. This change allows us to allocate more parameters to the attention and MLP layers without sacrificing model performance.
Beyond AdaLN modulation, we explored two alternatives: (1) removing timestep conditioning entirely, and (2) in-context timestep conditioning via timestep tokens. In our low-resolution pretraining runs, removing timestep information entirely consistently underperformed the AdaLN baseline. For in-context conditioning, we create time embeddings using sinusoidal embeddings, concatenate them into a unified text + image + time sequence, and remove the AdaLN layers entirely. At 256px pretraining, 4—16 timestep tokens were sufficient to replace AdaLN. At 512px and 1024px, however, in-context conditioning performed poorly relative to the AdaLN baseline. We attempted to mitigate this by increasing the number of timestep tokens, but observed diminishing returns and could not achieve competitive performance at higher resolutions.
Positional encoding
We implemented several RoPE schemes for our ablations. We use 3D axial RoPE, with head dimensions dedicated to frame, height, and width. For text tokens, we set the RoPE indices to zero. At low resolution, we did not observe significant gains from switching to Golden Gate RoPE, MRoPE, normalized RoPE, or partial RoPE. For partial RoPE, we rotate only the first half of the head dimension and leave the remainder unrotated. As expected, partial RoPE produced better zero-shot inference results when scaling the model from 256px to 512px and did not suffer from the common duplication artifacts. Despite this initial resolution generalization, partial RoPE ultimately performed worse than the baseline RoPE setting as high-resolution training continued.
Autoencoder
Recent work suggests that the latent-space design of the autoencoder can significantly accelerate the training of image generation models. We start from the FLUX.1-dev autoencoder as a baseline and benchmark it against the Qwen Image VAE, DC-AE, FLUX 2 VAE, and our internal autoencoder. We initially tested the DC-AE series, as it offers up to 32x spatial compression, which can substantially benefit both training and inference efficiency. However, we found that DC-AE imposes a hard upper limit on the diffusion model’s ability to resolve fine detail, owing to its reconstruction error.
By contrast, the Qwen Image VAE and FLUX 2 VAE offer a latent space with significantly faster convergence across our pretraining ablations while maintaining excellent reconstruction quality. We therefore initially used the Qwen Image autoencoder to scale our early models and later adopted the FLUX 2 VAE for our larger models. We also briefly explored training an internal autoencoder using DINOv3 for semantic alignment together with a light diffusion loss, following an approach similar to REPA-E. We validated that it performs competitively with the Qwen Image autoencoder, but owing to time constraints we opted for the Qwen Image and FLUX 2 VAEs, which have been validated at scale.
Residual design
We use standard residual connections as our default. We briefly experimented with Laurel, which improves the expressivity of the residual connection by adding a low-rank bottleneck branch, but observed no noticeable improvement. For future models, we intend to explore alternatives such as NOBLE, delta attention residuals, and mHC to improve the residual design of diffusion transformers.
Normalization
RMSNorm has become a standard component of LLM architectures but has not been fully integrated into recent diffusion transformer architectures. Starting from a LayerNorm baseline, we replaced all normalization layers with RMSNorm and observed very little quality degradation. We therefore use RMSNorm as the default normalization module (for example, for prenorm and QKNorm). We use the zero-centered RMSNorm and apply weight decay to its learnable parameters. We also experimented with more efficient variants such as Derf, but found non-negligible quality degradation.
Text encoder
We used T5-XXL as our baseline text encoder. From the outset, we deliberately chose to keep the architecture simple and use a single text encoder. Notably, we find that T5-XXL remains a very competitive text encoder relative to T5Gemma, umT5, Qwen 2.5 VL, and Qwen 3 VL. Ultimately, we use Qwen 3 VL as our final text encoder, as a VLM offers a richer input space (text and image) and stronger multilingual generalization.
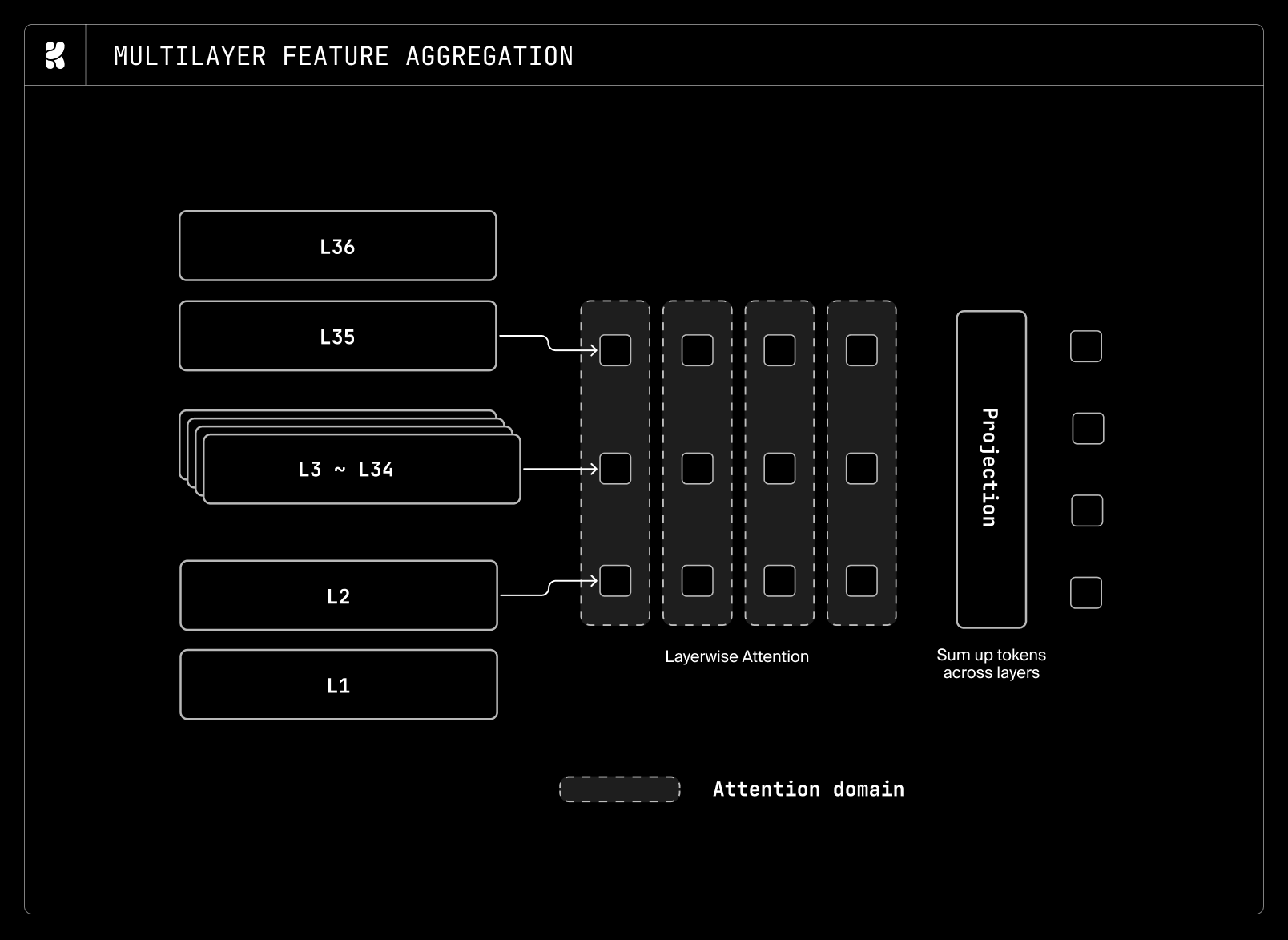
Furthermore, inspired by Unifusion, rather than taking the last layer of the VLM features, we introduce a shallow attention layer that aggregates hidden features across layers. This design allows the model to dynamically select coarse-to-fine text representations. The last-layer features of an autoregressive LLM are suboptimal for our purpose, as they are optimized for next-token prediction rather than image generation. Alongside this layerwise feature aggregation, we add lightweight bidirectional transformer layers across the token axis to reduce the autoregressive bias in the representation space.
Optimization
We use AdamW as our primary optimizer throughout the pipeline. We initially saw mixed results applying Muon to the MMDiT architecture. By default, we use the Muon implementation from Dion and the RMS-matched setting from Moonlight to transfer AdamW hyperparameters.
In our exploration, Muon converged faster than AdamW in the initial steps but underperformed it over longer horizons. We also encountered a number of stability issues with Muon, including frequent loss and gradient-norm spikes throughout training. We found it crucial to exclude the first and last linear layers of the MMDiT from the Muon parameters; this is consistent with the LLM literature, where embedding and LM-head parameters are excluded from Muon. After excluding these layers and adding Nesterov momentum, Muon consistently outperformed the AdamW baseline at both low and high resolution. We did not adopt Muon for our most recent pretraining run owing to time constraints, but given these strong results we plan to adopt it in our next pretraining cycle.
Training
Our training pipeline follows a multi-stage structure inspired by modern LLM training pipelines.
Pretraining
Pretraining establishes the model’s basic capabilities, including text-image alignment, text rendering, stylistic coverage, and structural consistency. We progressively scale the resolution from 256px to 512px to 1024px. For our final model, we train with the standard rectified-flow loss under v-parameterization. To accelerate the early stages, we use iREPA for the first epoch of the 256px stage and then remove it, which encourages the MMDiT to learn its own representations while substantially speeding up initial convergence. We also explored alternative acceleration strategies such as TREAD, but saw little benefit.
During the 256px and 512px stages, we use 8-bit training and observe 15—20% gains in training speed over a bf16 baseline, with very minimal degradation in training loss and evaluation metrics. At 256px we use 8-bit training with tensorwise scaling, and at 512px we use finer-grained rowwise scaling. From 1024px onward, and through the final RL stage, we use standard bf16 training.
Another important aspect of high-resolution pretraining is adapting the resolution-dependent timeshift schedule. We use a shifted logit-normal sampling schedule for both training and inference, and gradually increase the shift as resolution increases. Following FLUX 2 VAE blog, we sweep for the optimal training timeshift at each resolution. We sweep the shift only for training and keep the inference shift schedule constant, as certain autoencoders are less sensitive to the inference timeshift.
During pretraining, we use a warmup-stable-decay learning-rate schedule and apply PMA following Model Merging in Pre-training of Large Language Models. We validate that PMA achieves performance comparable to EMA while avoiding its significant memory overhead. We do not observe significant differences between merging methods, although tuning the number of merged checkpoints and the merge interval can yield slight gains on downstream metrics.
Midtraining
Midtraining has become common in the LLM literature, and we incorporate an analogous stage into our pipeline. Its focus is to warm up the model’s distribution before the supervised finetuning (SFT) stage. We find that midtraining is typically the last point in the pipeline at which we can equip the model with downstream capabilities such as high-fidelity, high-resolution generation, strong domain coverage, and text rendering.
Supervised finetuning (SFT)
In the supervised finetuning (SFT) stage, we curate a small, dedicated set of highly aesthetic images. The objective is to further bias the model toward aesthetically desirable directions. We find this stage particularly helpful for improving overall checkpoint quality and for addressing the high-saturation and texture issues that are prevalent in earlier checkpoints.
After training domain-specific SFT checkpoints, we use model merging to produce a generalist SFT checkpoint. Model merging yields diminishing returns toward the later stages of the pipeline, as the directions of improvement begin to conflict across checkpoints.
Preference optimization (PO)
Preference optimization (PO) is the first stage of our post-training stack and consists of a two-stage pipeline. In the first stage, we run a large-scale synthetic preference-pair generation pipeline for initial refinement, using a strategy similar to delta learning; we ensure that the majority of pairs include at least one on-policy sample. The second stage is a calibration stage that uses only human annotations. These annotations are collected entirely in house, by people familiar with the specific strengths, weaknesses, and quirks of the model.
A common phenomenon during PO is policy divergence. At a high level, preference-optimization methods such as DPO encourage the model to increase the margin between its likelihood of generating a preferred sample and that of generating a dispreferred one, relative to the reference model. In practice, across different preference-dataset mixtures, we observe that the model achieves this objective by decreasing the likelihood of generating both samples, but at different rates. This would be desirable if both the winning and losing samples were of lower quality than the current model distribution, but that assumption does not always hold, depending on how the preference set was curated. Moreover, this divergence drifts the model away from the general pretraining distribution, which manifests as high-frequency artifacts in the later stages of training. To mitigate this, we designed a variant of DPO, which we call STPO, that adds an auxiliary loss and a modification to the original DPO formulation in order to reduce this divergence.
Reinforcement learning (RL)
Reinforcement learning (RL) is the final stage of the training pipeline. We use a multi-reward GRPO-style method with several reward models: (1) a general aesthetic model, (2) a prompt-following reward , (3) a text-rendering reward, (4) an artifact and structure reward. The general aesthetic model is obtained by finetuning an open-source VLM on the preference data collected during the PO stage. We carefully design the reward structure and tune the data mixture to prevent artifacts introduced by reward hacking.
Unlike general aesthetic rewards, which are inherently subjective, prompt following and text rendering provide more concrete signals because they can be checked against the user’s stated intent. The challenge is that this intent varies widely across prompts. To handle this, we use a prompt-specific rubric reward inspired by rubric-based evaluation in LLM training. Instead of asking a judge model for a single holistic score, we decompose each prompt into verifiable requirements and evaluate the generated image against them. This gives the RL stage a more structured signal for alignment with user intent, making the model better at satisfying fine-grained prompt constraints without reducing prompt following to generic image quality.
We also found that optimizing only for aesthetics and prompt following can lead to reward hacking. The model may learn to produce images that appear plausible at first glance while containing structural artifacts such as extra fingers, malformed limbs, or distorted text. These failures are visually obvious to humans but are often missed by general-purpose VLM judges. To address this, we train a dedicated artifact reward model that detects these structural errors and discourages the RL stage from improving benchmark-facing signals at the expense of visual correctness.
During the RL stage, we find that success depends not only on the quality of the reward models, but also on how efficiently training compute is allocated across prompts. Reward models define the direction of improvement, while the prompt pool determines where the model receives useful learning signal. We therefore curate a broad pool of prompts spanning diverse styles, concepts, settings, and subjects, then continuously analyze the reward statistics of generated groups to identify which prompts are most informative. Prompts that are already too easy, consistently too hard, or produce little variance across samples contribute limited signal and are deprioritized or removed. In practice, effective RL requires treating prompt selection as a resource-allocation problem, where the training process should spend more compute on examples where the model can still learn, and less on examples that provide saturated or noisy feedback.
Another practical consideration in diffusion RL is how to handle classifier-free guidance (CFG). Both rollout generation and training can be performed with or without CFG, and different choices create different trade-offs between alignment, stability, and efficiency. After ablations, we found it important to keep the rollout and training distributions aligned while avoiding unnecessary computational overhead. We therefore train the whole RL stage without CFG. This setting quickly improves the conditional model distribution, bringing no-CFG samples much closer to guided samples early in training. At inference time, CFG can still be enabled as an additional control knob, further improving quality when desired.
Timestep distillation
After the RL stage, we include an optional timestep-distillation stage in which we apply guidance distillation and timestep distillation simultaneously. We considered several distillation techniques, including DMD, DMD2, Decoupled DMD, piFlow, and APT, but adopted Trajectory Distribution Matching (TDM) for the following reasons. We sought a technique that was simple to tune, with minimal hyperparameters, which ruled out GAN-based methods and piFlow (the latter requires adapting the model into a multi-timestep prediction model). We chose TDM because it provides a fast, data-free method with flexible multistep distillation.
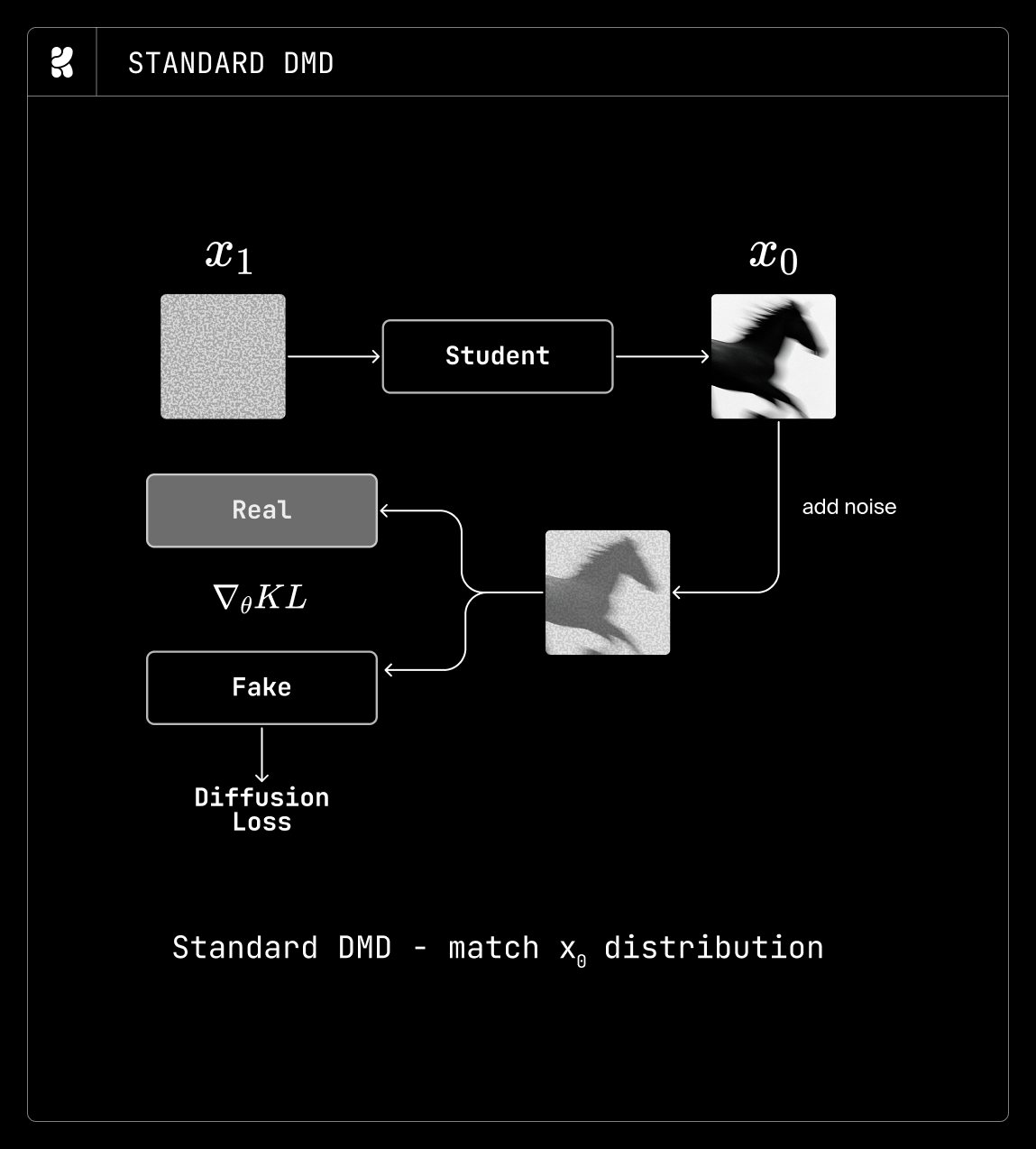
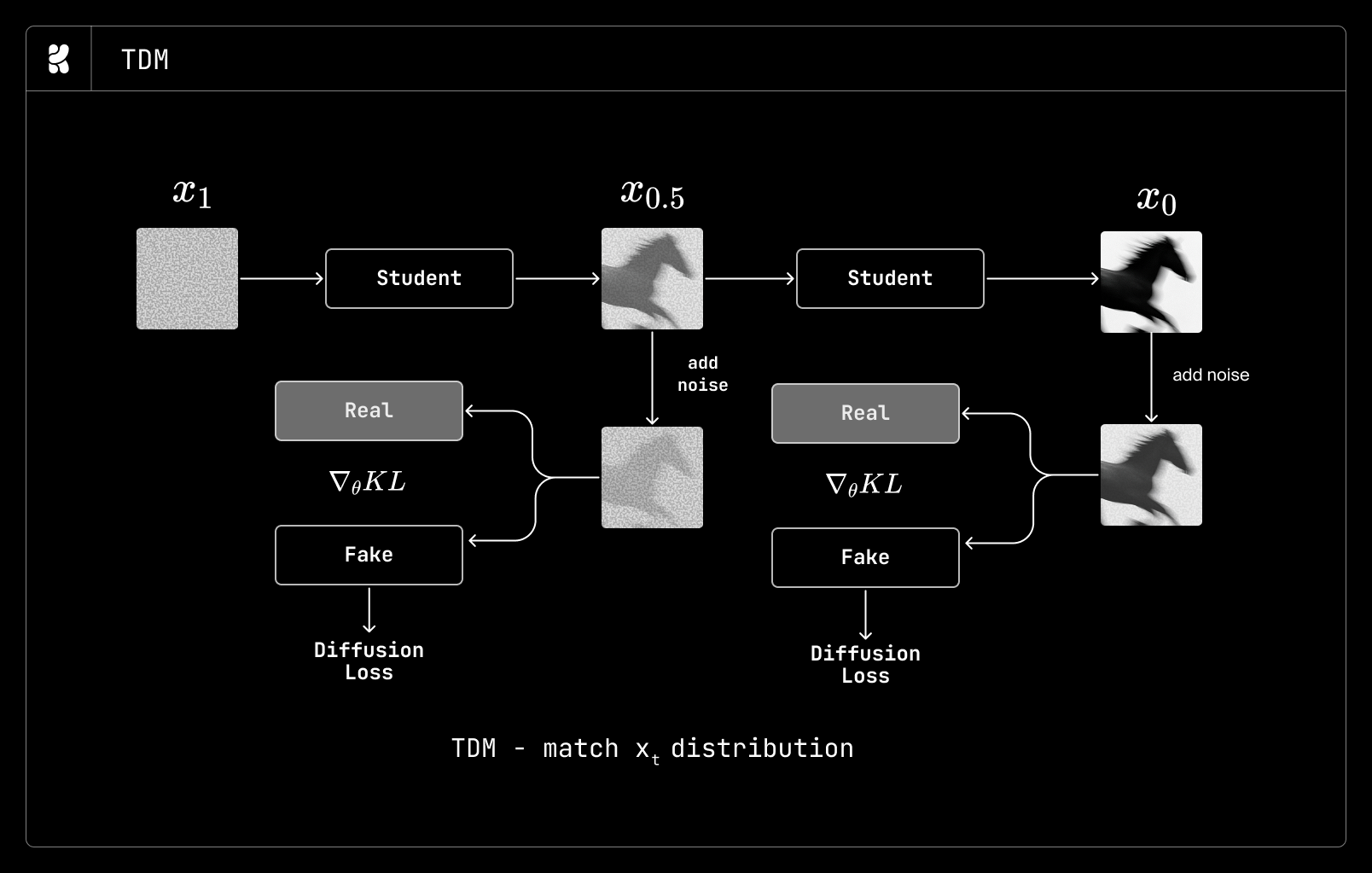
DMD distills the teacher by matching the distributions of real and generated samples over the clean-image distribution. Accordingly, standard DMD uses a few-step student to predict a clean image and then renoises the prediction to train the student (see figure above). Unlike DMD, which matches only the clean-image distribution, TDM applies DMD across timesteps, effectively performing distribution matching at the trajectory level rather than at the sample level. Since our goal was a flexible multistep student, we found TDM to be the most suitable method for our use case.
Prompt Expansion
Dense prompts reliably produce better image-generation results, but users rarely write prompts that resemble the rich captions used during training. We frame this as a distribution-mapping problem: the image model is best conditioned on detailed captions that lie close to its training distribution, while real user prompts are often short, conversational, and underspecified. We therefore develop a prompt expander that interprets user intent and maps an input prompt into a richer, model-friendly caption.
We first perform supervised finetuning on an existing open-source LLM. To curate training data, we use another language model to generate synthetic “user captions” from long captions: shorter, more conversational, semi-instructional prompts that intentionally omit many visual details present in the target caption. This produces paired data of the form underspecified user prompt -> expanded, model-friendly caption. We also synthesize thinking traces to preserve the model’s reasoning ability, as we find that an intermediate intent-reconstruction step improves downstream behavior. Beyond this, we apply a small amount of targeted distribution shaping. At a high level, we oversample visually rich and artistic imagery to give the expander broader coverage of creative and aesthetic prompt styles, and add a lightweight photographic-medium bias for prompts that should expand into photorealistic descriptions. The goal is not to impose a house style, but to ensure that the expanded-prompt distribution covers both expressive, art-directed imagery and straightforward photorealistic requests.
SFT brings the expander close to the desired caption distribution, but matching synthetic targets is not the same as improving the final image. We therefore use RL to optimize the expander directly through the generations it produces. At this stage, the objective shifts from imitating the target caption to producing expansions that improve image quality while preserving the user’s intent. We train with GDPO under a multi-reward objective: image-level rewards measure the quality and preference of the resulting generations, while prompt-level verifiable rewards check whether the expansion remains faithful to the original request. We also include safety and constraint checks to prevent the expander from introducing clearly unprompted or unacceptable content. Since these checks are sparse by nature, we use them as gates on the overall reward rather than as dense optimization signals.
We sought to balance matching a realistic distribution of user inputs with ensuring that each group contained a high-contrast mix of good and bad rollouts. To this end, the RL prompt mix combines realistic user-like traffic with mined hard cases. The realistic side includes actual prompts and previously observed failures, supplemented with hand-curated failures and synthetic augmentations of known failure modes. Curated examples come from internal downvotes, bug reports, and manually rewritten prompts, and are bucketed so that every known failure class remains represented. Synthetic examples start from hand-authored reward-trigger probes, are expanded into many variants, and are scored offline with the same reward schema used during RL. We select prompts that are “hard but not hopeless,” producing groups with intermediate composite scores and real reward variance, so that GDPO receives a meaningful preference signal rather than only obvious wins or total failures.
One failure mode we explicitly optimize against is diversity collapse. Prompt expanders can learn a single safe, high-reward house style, especially when image rewards dominate. To counter this, we add a simple DINOv3 embedding diversity score over prompt groups, rewarding intra-group visual diversity alongside quality and alignment. We briefly experiment with annealing the diversity reward, but find that once its weight becomes too small, the model quickly collapses toward less varied generations. In practice, keeping the diversity reward active throughout training is necessary to preserve variation.
Style reference system
Our style-reference system builds on the base model. It allows users to generate images from text while using one or more reference images to guide the output style. We designed the system to support (1) smooth semantic mixing of multiple styles, (2) continuous control over the strength of each style reference, and (3) state-of-the-art adherence to complex styles.
Style transfer is difficult because of the ambiguity in what constitutes “style” versus “content” in an image. One of the most common failure modes was the leakage of content and subject matter from the style image into the final image. Furthermore, unlike conventional editing tasks, whose data can be mined from sources such as video, style-transfer data is significantly harder to obtain in large quantities at the fidelity we targeted.
To address these challenges, we devised a novel self-supervised technique for training the style-reference module, followed by a preference-optimization step to further align the outputs.
Training infrastructure
Our distributed training framework is built from scratch on PyTorch. We rely primarily on the DTensor abstraction and the torch-native features supported by the torchtitan project. For most of our pretraining and post-training runs, we use FSDP2 together with Megatron-LM-style tensor parallelism. For settings with a TP size larger than 2, we enable async-TP via a torch.compile flag, which offers a moderate speedup over naive TP. Since the autoencoder parameters add minimal memory overhead, we leave them replicated across all devices and shard only the text encoder and the main MMDiT backbone. For intra-node connections, we use NVLinkSharp, and for inter-node connections we use InfiniBand.
For training efficiency, we use a slightly wider model with larger hidden dimensions, for two reasons. First, a larger hidden size increases the computational intensity of each layer, which makes it easier to hide latency with FSDP2 prefetching; reducing the number of layers also reduces the number of all-gather and reduce-scatter operations. This change significantly reduced NCCL-related errors throughout our pretraining runs. Second, larger matrix-multiplication sizes help amortize the quantization and dequantization overhead of 8-bit training.
We rely heavily on torch.compile as our main optimization strategy. For attention, we default to the latest cuDNN kernel and use FlexAttention or FlashAttention 3 as needed. At low resolution we use selective activation checkpointing, and at higher resolution, where activations begin to dominate memory, we use full activation checkpointing.
For dataloading, we use Parquet as our primary format. For each row, we store a reference to the image (for example, a local path or S3 location), the crop and resize dimensions, the captions, and any other relevant metadata. For large runs, we shuffle and pack the rows ahead of time so that each dataloader worker loads a batch of images with the same aspect ratio. This packing allows us to encode the latents in a single autoencoder pass.
This implementation has several benefits. By preshuffling the data, we can perform a sequential scan over disk for performant dataloading while ensuring proper global shuffling. Preshuffling is also essential for reproducibility and debugging, since the data can be replayed in exact order to identify any sample that may have caused a loss spike.
During our largest pretraining runs, we encountered various infrastructure and fault-tolerance challenges. Conventional large-scale distributed training introduces many global synchronization points across the cluster (for example, the gradient all-reduce across DP replicas) and is inherently flaky: a single GPU failure or straggler can bring down the entire run. Fault-tolerance solutions such as torch-ft and decoupled DiLoCo exist, but at our scale we found that optimizing for mean time between failures (MTBF) and mean time to recovery (MTTR) through fast, frequent checkpointing and improved startup time was a satisfactory solution.
Another crucial factor for reliability was maintaining homogeneous load on I/O, CPU, and GPU across the training devices. We explicitly design the dataloader so that each CPU and GPU is under approximately equal load. In our initial large runs, a high-resolution image used during a low-resolution stage would be cropped and resized to low resolution on the fly; for our largest runs, however, this added uneven CPU and I/O load across devices depending on whether the original image was high resolution. To mitigate this, we crop and resize all images to the target training resolution ahead of time. We further ensure that every GPU receives a tensor input padded to exactly the same shape, which evens out the load.
For our RL infrastructure, we disaggregate reward-model inference from the main training process. Since Krea 2 was our first major RL iteration, we use a simple design in which the training and rollout GPUs are shared. In the near future, we plan to implement a disaggregated training and inference setup to support techniques such as PipelineRL for asynchronous RL training.
Systems Infrastructure
Our research ran within a single Kubernetes cluster in which GPUs were shared with production inference. The system was designed so that research could claim the entire GPU pool when required: if every GPU in the cluster was allocated to a training run, Krea’s inference workload would automatically migrate elsewhere. This allowed us to disregard production capacity when launching training runs, as the system handled traffic failover and kept production responsive even when no GPUs remained available locally.
This capability was not present from the outset. The scheduling and management systems evolved alongside the research team’s needs over the course of the research cycle. In the following sections we describe the main components: workload scheduling with Kueue, scaling inference outside the cluster, the scheduling policy that ties the two together, our training launch procedure, and the observability stack that proved essential for large-scale pretraining.
Scheduling with Kueue
Kueue has been central to our setup, although our usage has changed substantially. It provides a two-tier priority system that combines Kueue’s Workload priority with Kubernetes’ Pod priority. When configured correctly, this two-tier design yields useful scheduling semantics.
We considered custom schedulers such as Volcano, as well as modifying the kube-scheduler directly, which would have offered additional desirable properties. Ultimately, the default Kubernetes scheduler combined with Kueue was sufficient for our requirements. We anticipate that continued scaling will eventually require us to move off Kueue and the default scheduler in favor of a custom scheduler — likely in the near future, given the unusual nature of our workloads — but we have not yet reached that point.
Kueue enables gang-scheduling, which is necessary for multi-node training. Additionally, the queueing primitives of “borrowing”, “lending”, and “reclamation” are helpful in maximizing utilization. However, we wish Kueue allowed GPU-counts per queue to be dynamically inferred rather than manually specified. This manual operation, required when node count changes, was a consistent annoyance.
Scaling Inference Outside the Cluster
The second component addresses how inference scales elsewhere when all GPUs are allocated to research. Our initial designs introduced considerable complexity, and we ultimately adopted a simpler approach based on a Virtual Kubelet (VK), which emulates a Kubernetes node. Because the resulting system is expressed entirely in Kubernetes primitives, much of the required behavior is inherited directly from Kubernetes.
We first evaluated InterLink, which is also built on the Virtual Kubelet, but found it unsuitable for our use case. We therefore built our own layer on top of VK that provides the semantics our systems require, along with a clean interface for integrating new GPU providers, provided each offers a programmatic means of scaling capacity up and down.
The system operates as follows. A virtual Kubernetes node is registered in the cluster. When a pod is scheduled onto it, our code transforms the pod specification into a form compatible with the target provider, deploys it there, and reconciles the two sides in the event of a provider-side failure.
A key advantage of this design is that scaling behavior is inherited from Kubernetes. Consider an HPA configured for ten replicas, all running outside the cluster, where one replica fails. Rather than attempting to repair it, the reconciliation loop detects the failure, marks the pod as failed (and garbage-collects it subsequently to avoid accumulating dead pods), and allows the HPA to schedule a replacement. The system therefore does not attempt to repair failures directly; it detects them, propagates them to Kubernetes, and delegates recovery to Kubernetes.
The integration requires implementing a small set of primitives: pod creation, pod deletion, exec (where needed), and the node’s startup behavior — for example, recovery when our code crashes while pods remain running on the provider side. A dedicated layer absorbs the requirements specific to our systems, and new providers are integrated through a clean interface to these primitives so that business logic does not leak into provider implementations.
Launching Training Runs
This component is simpler than the others but still thought us a lot about ergonmics and whats worth automating. As the GPU count grew, additional operational issues emerged, and our launch procedure evolved accordingly.
During large runs we frequently encountered a small number of faulty nodes (discussed further below) that disrupted the run until they were rotated out. Initially we cordoned the known-faulty nodes before launching and allowed pods to schedule onto the healthy pool. As the set of faulty nodes grew over time, however, each crash required substantial manual intervention. This list of faulty nodes was initially maintained as a plain text file of node names.
We also observed that running additional processes on a node — even processes that did not access the GPUs — introduced instability as the run scaled across more nodes. The manual procedure consequently grew to include identifying a clean set of nodes, labeling them so that training pods would schedule via affinity, tainting them to prevent other workloads from scheduling (with the exception of the training), and finally draining them.
Tainting was necessary only for very large runs requiring maximum stability. The procedure was therefore partially automated: the launch CLI retrieved the faulty-node list, excluded those nodes along with nodes already running trainings or dev machines, and selected the required number of nodes from the remainder, labeling and tainting them automatically. On teardown, it removed the labels and taints.
This list subsequently migrated from a text file to node labels, which allowed us to express soft or hard anti-affinity against faulty nodes directly. It also enabled a Kubernetes operator, “Packerman”, which packs pods such as dev machines onto faulty nodes so that healthy nodes remain available for training. For most purposes, dev machines running on faulty nodes are acceptable: during development, one GPU running 5—10 degrees C hotter than the others in the node is tolerable, whereas for training it is not.
Observability
Metrics
Observability is the area in which we learned the most about large-scale pretraining. Each crash had a set of recurring causes, but new and unexpected failure modes appeared throughout, and over time we became proficient at diagnosing the cause of a given crash. Training at this scale would not have been possible without metrics for GPU, PCIe, NVLink, InfiniBand, and related subsystems. We collected these through a combination of DCGM and custom DaemonSets that exported additional metrics of interest.
Below we describe several of the most useful metrics and their behavior when a run deviated from expected values. Each is accompanied in the original report by a figure from a production run.
DCGM_FI_DEV_GPU_TEMP GPUs are highly temperature-sensitive. We observe that any GPU exceeding 75—78 degrees C increases training instability, as it begins to throttle and reduce overall throughput.
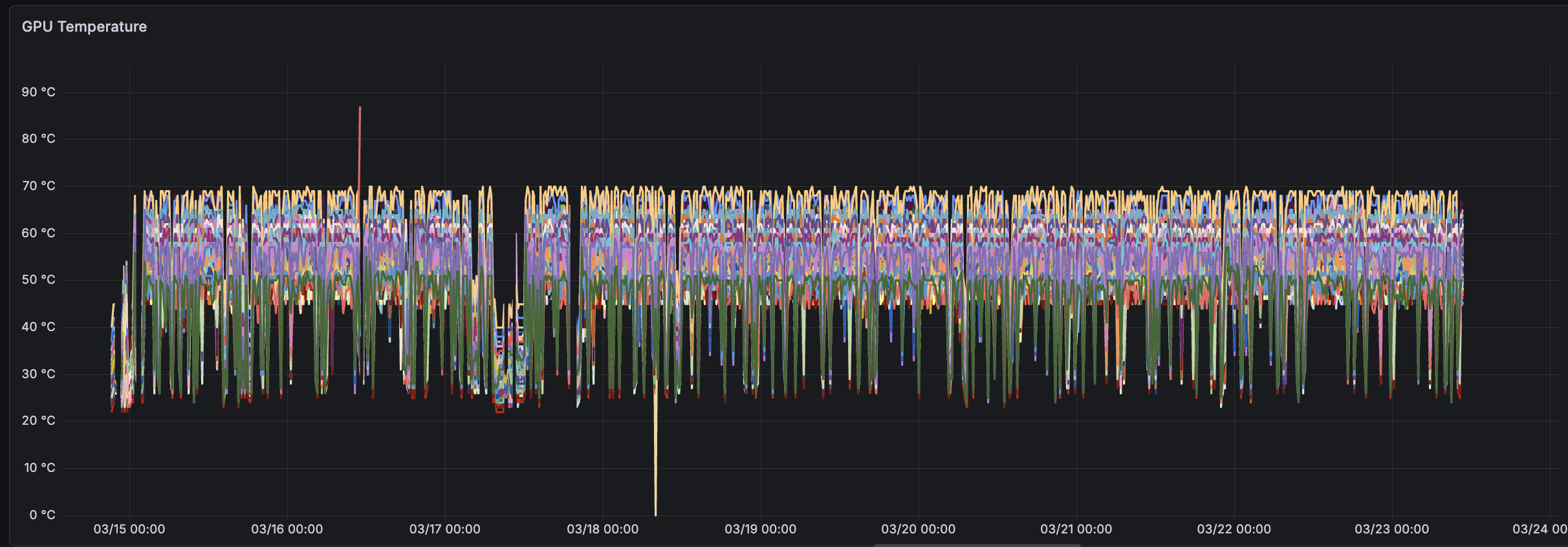
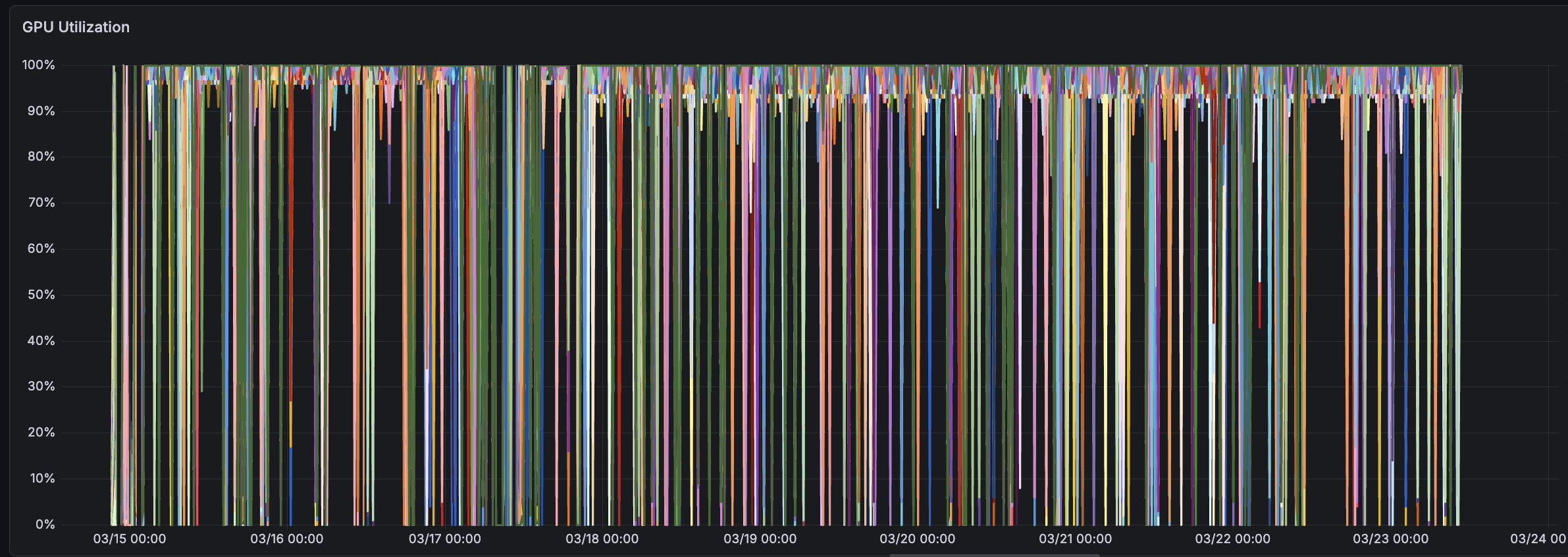
DCGM_FI_DEV_GPU_UTIL We find this metric to be often misleading as it often presents a symptom, not a cause. Given many distributed training errors proceed from one process crashing initially, we find that this metric often contains an unhelpful report of one GPU dropping to 0% utilization followed shortly by a crash. Additionally, we find this “utilization” metric generally misleading as it only reports ”% of time any CUDA kernel is running on the GPU” rather than “real” use of the capabilities.
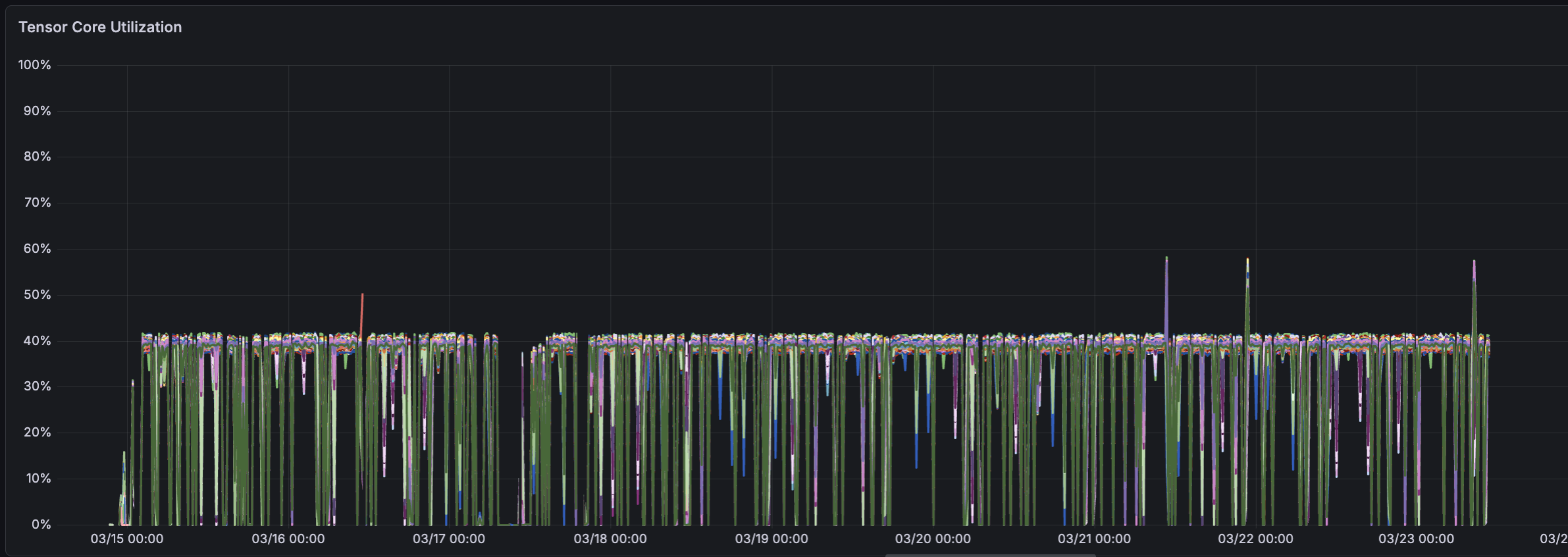
DCGM_FI_PROF_PIPE_TENSOR_ACTIVE Tensor core utilization was our preferred indicator of whether training was performing as expected. We observed a clear correlation across training stages, with higher-resolution images producing higher tensor core utilization. It also served as a proxy for other conditions: nodes with overheating GPUs exhibited abnormally high tensor core utilization (counterintuitively), and a steady decline over the course of a run typically indicated a faulty node or other instability.
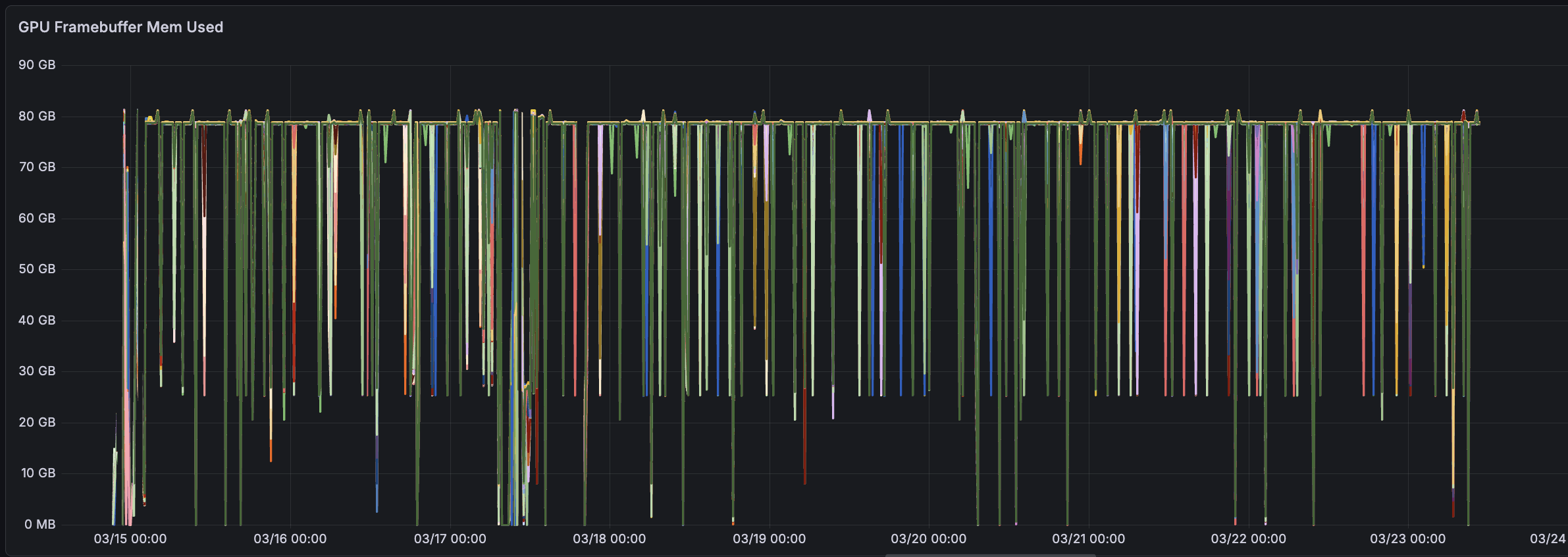
DCGM_FI_DEV_FB_USED Memory usage was useful, though for a different reason than is commonly expected. OOM events were rare and, once a configuration stabilized, effectively never occurred. The metric was instead useful when a small number of GPUs failed or stalled during memory allocation: most GPUs allocated their memory at the start of training, while a few remained stuck at roughly 5 GiB of VRAM. The corrective action was to reboot the affected node.
DCGM_FI_DEV_XID_ERRORS As with memory usage, XIDs were useful in a minority of cases. Most crashes produced no XID, but when one was emitted it identified the cause directly.
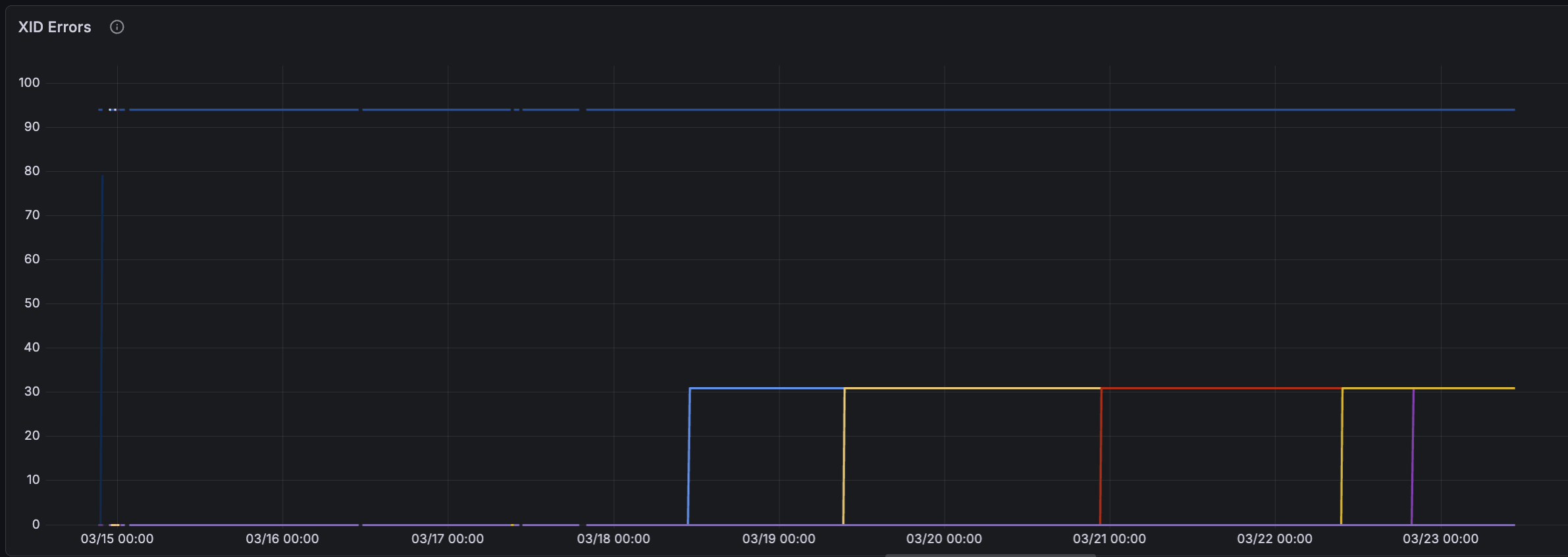
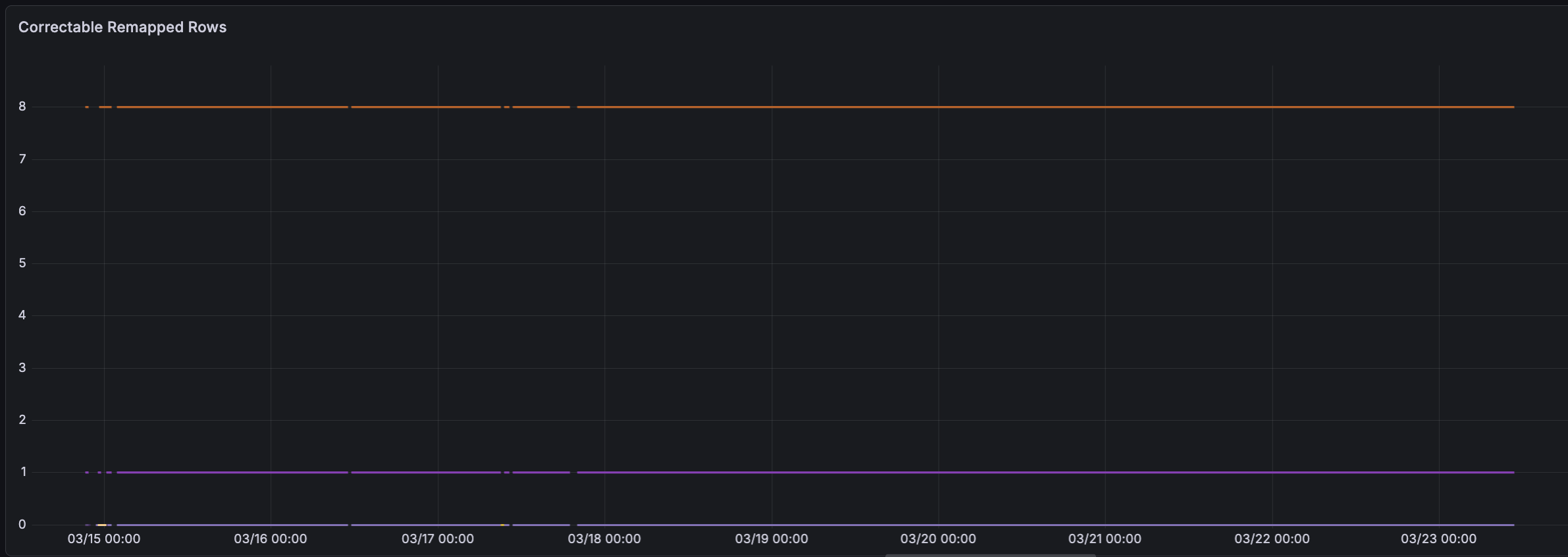
DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS, DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS, and DCGM_FI_DEV_ROW_REMAP_FAILURE These metrics were useful for identifying GPUs with faulty memory modules; when memory was the root cause, the signal was generally unambiguous.
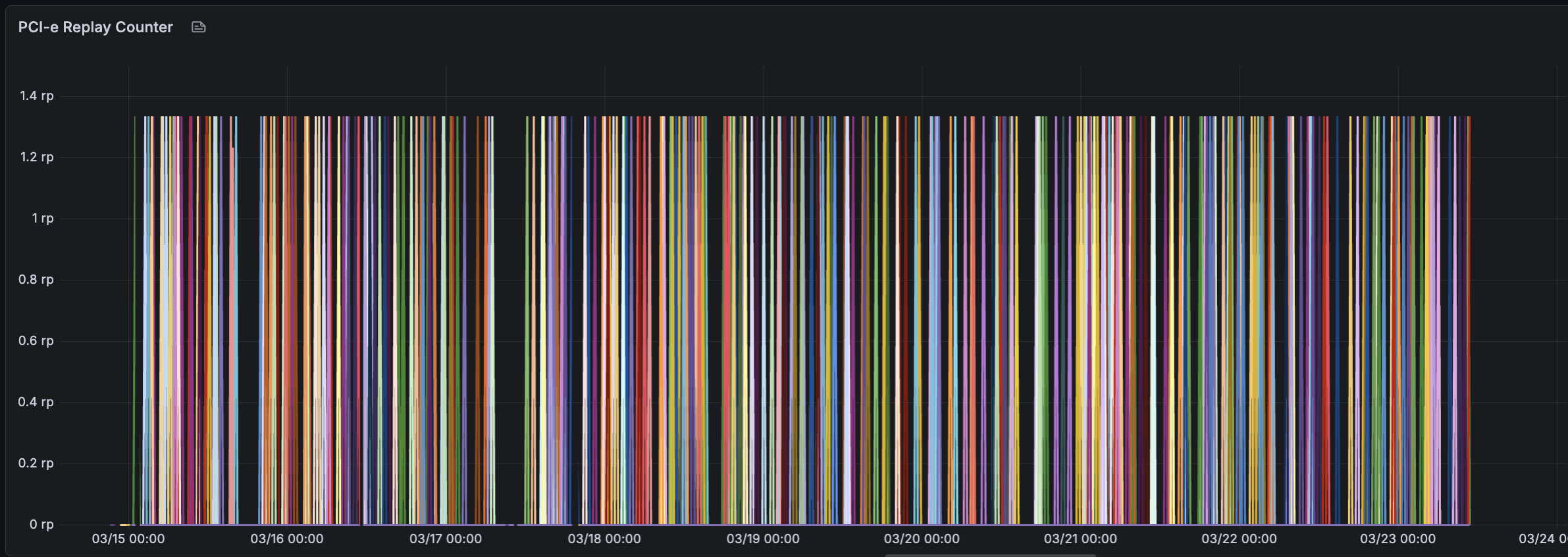
DCGM_FI_DEV_PCIE_REPLAY_COUNTER — This metric reports the quality of a GPU’s connection to the motherboard. A burst of replays on a specific GPU consistently preceded a crash. Occasional replays distributed across random GPUs were benign; the failure mode manifested as a large spike on a single GPU.
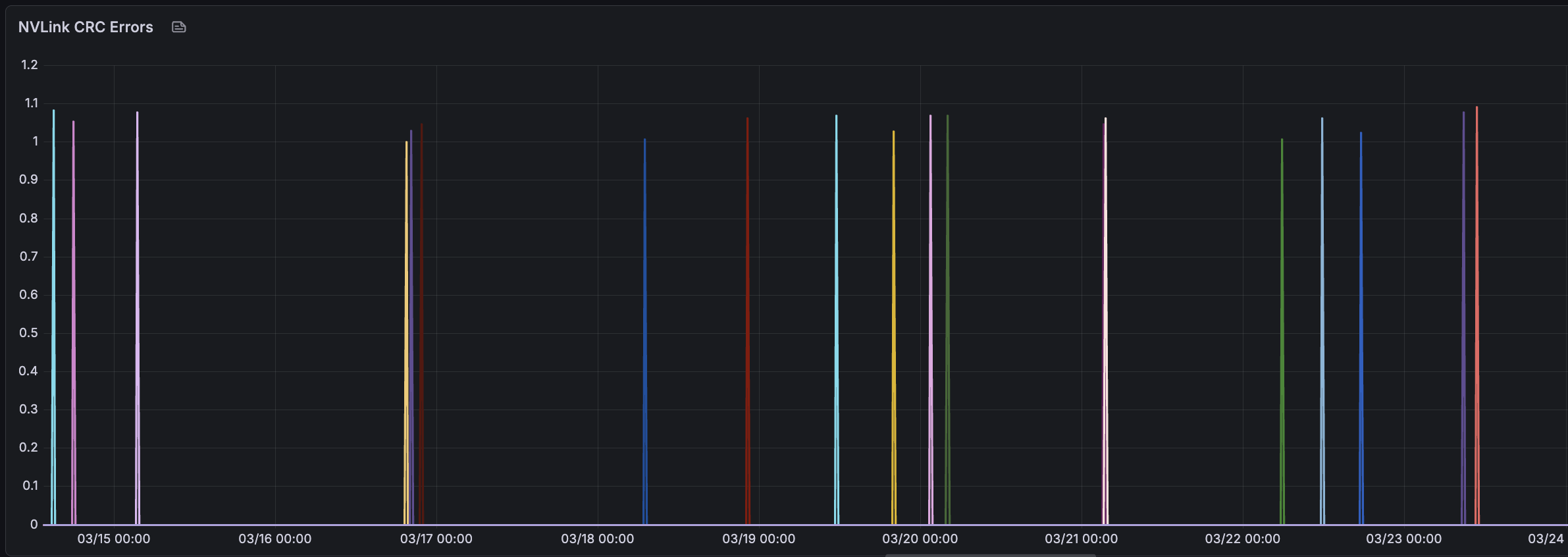
NVLink errors (custom) — DCGM does not export these by default, so we implemented a custom DaemonSet to collect CRC, replay, and recovery errors. In rare cases, as with PCIe replays, these metrics allowed us to identify a faulty node.
InfiniBand metrics (custom) — IB metrics were arguably the most important metrics we collected, particularly because the cluster fabric was not consistently stable. We collected the following:
VL15_dropped
excessive_buffer_overrun_errors
link_downed
link_error_recovery
local_link_integrity_errors
multicast_rcv_packets
multicast_xmit_packets
port_rcv_constraint_errors
port_rcv_data
port_rcv_errors
port_rcv_packets
port_rcv_remote_physical_errors
port_rcv_switch_relay_errors
port_xmit_constraint_errors
port_xmit_data
port_xmit_discards
port_xmit_packets
port_xmit_wait
symbol_error
unicast_rcv_packets
unicast_xmit_packets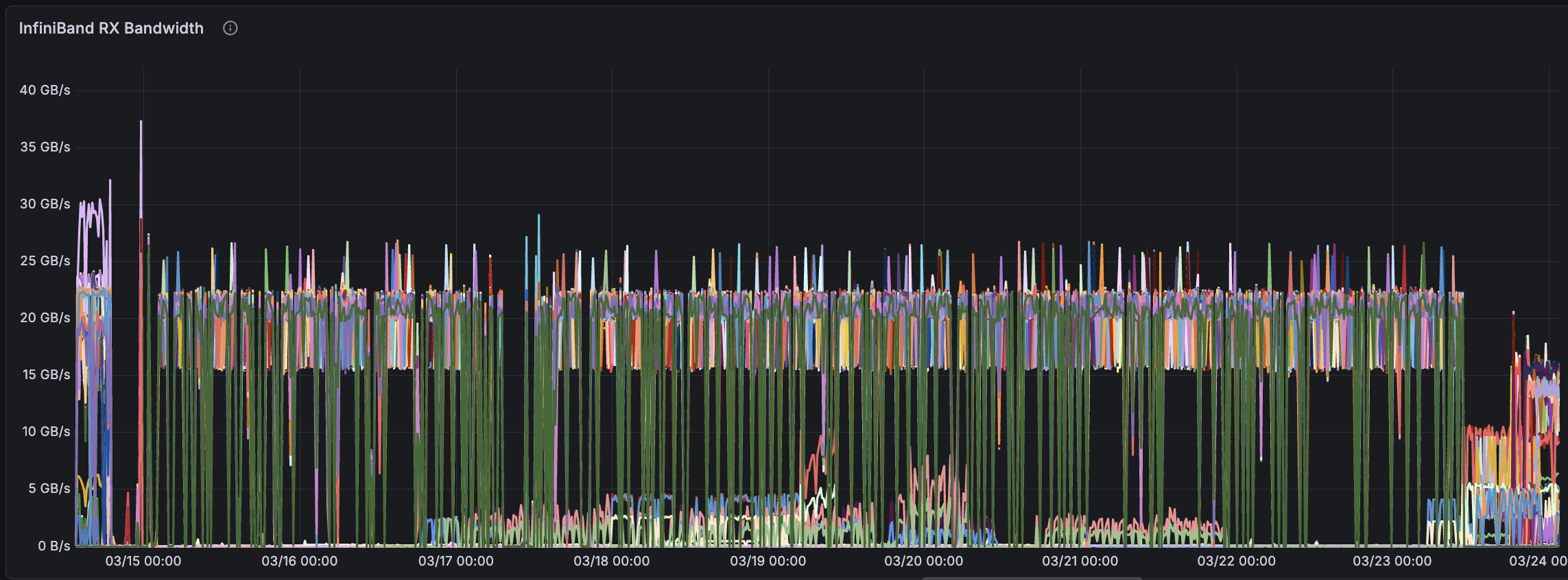
These metrics were essential for diagnosing a wide range of InfiniBand-related issues. Fabric instability was the single largest contributor to run crashes, including link flapping, packet errors, congestion, symbol errors, and throughput disparity between devices. The metrics allowed us to localize misbehaving sections of the fabric — for example, packet errors confined to mlx5_10 and mlx5_11, or reduced throughput on mlx5_0. We found ibtop useful for debugging these issues.
Lessons
Training at scale taught us a great deal about the behavior of our cluster and about large-scale training more generally. Early on, our response to a crash was aggressive: swapping nodes, relaunching, and changing configurations. Over time we learned to distinguish issues worth addressing from transient quirks. In some instances a run would crash repeatedly within a two-hour window and then, without any change other than relaunching, run for sixteen hours without incident.
We also encountered the difficulty of scaling the GPU count, and our experience may differ from that of other pretraining efforts. The failure rates commonly reported as a function of scale did not match our observations: doubling the GPU count produced substantially more instability than anticipated. As an illustration, with identical code and data, runs on fewer than 128 GPUs were very stable, often running for days without incident, with crashes generally attributable to a genuine fault. As we scaled the GPU count, however, runs began to crash far more frequently, and we did not complete a single run at very large scale that exceeded 24 hours without a crash. Many of these crashes had no obvious cause; they presented silently, such as an NCCL timeout, while all metrics appeared healthy.
Filesystem and Checkpointing
One of our most significant early mistakes was adopting Ceph, which did not perform well at our scale or for our use case. For this reason, we switched to Weka and have not reconsidered the decision. Filesystem-related problems and downtime dropped sharply, while performance improved by a comparable margin. The transition was not entirely without friction. We encountered numerous quirks and edge cases both during installation and over the filesystem’s lifetime, but Weka was consistently responsive in helping us resolve them. This was particularly valuable given that the Kubernetes offering was not fully mature when we adopted it, although it has improved considerably since, with new features and bug fixes.
As discussed in the section on reliability, Weka was a crucial enabler for training Krea 2, where we checkpointed very aggressively. The filesystem kept pace with this demand: a checkpoint completed in roughly 30 seconds, so little time was lost to checkpointing. This single filesystem stored everything — research and development data, images, checkpoints, datasets, and all other artifacts — and performed well in every case.
The one notable quirk, which is not attributable to Weka, concerns our use of IPoIB mode: we suspect it contributes to InfiniBand fabric instability in our cluster. The fabric was already unstable prior to Weka, however, so at most this exacerbated an existing condition.
Max read throughput on our Weka cluster
Max write throughput on our Weka cluster
Data infrastructure
To ingest and curate the data for K2, we built a custom warehousing and queueing system around a cluster of PostgreSQL servers. We call each Krea tablet server a krablet. Each krablet consists of:
- a Postgres instance holding one shard of the data, and
- a deployment of “funnel” servers for that shard, which asynchronously batch and queue mutations to minimize lock contention.
All reads are proxied through a large-scale deployment of “RPC” servers, which replace a traditional connection pooler such as PgBouncer. Each RPC server maintains a connection pool to every shard of the database.
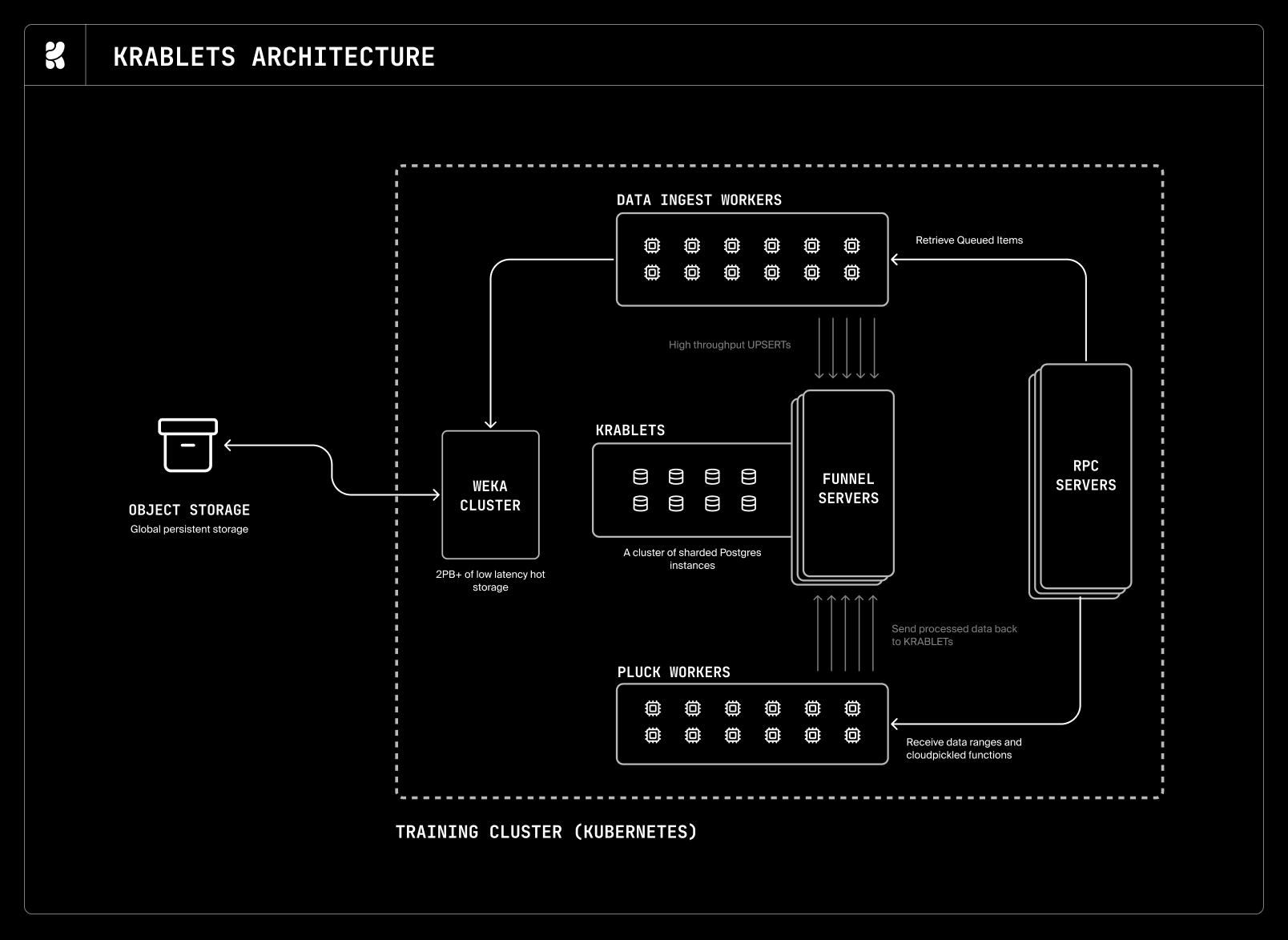
The krablet servers hold all metadata for our training datasets and store keys that reference the images in object storage.
Although nontraditional, the krablet system has scaled to 208 TB of metadata alone and can process tens of thousands of contended UPSERT transactions per second. More importantly, it provides a single source of truth for all research data and allows our stream-processing layer to be the same as our data layer.
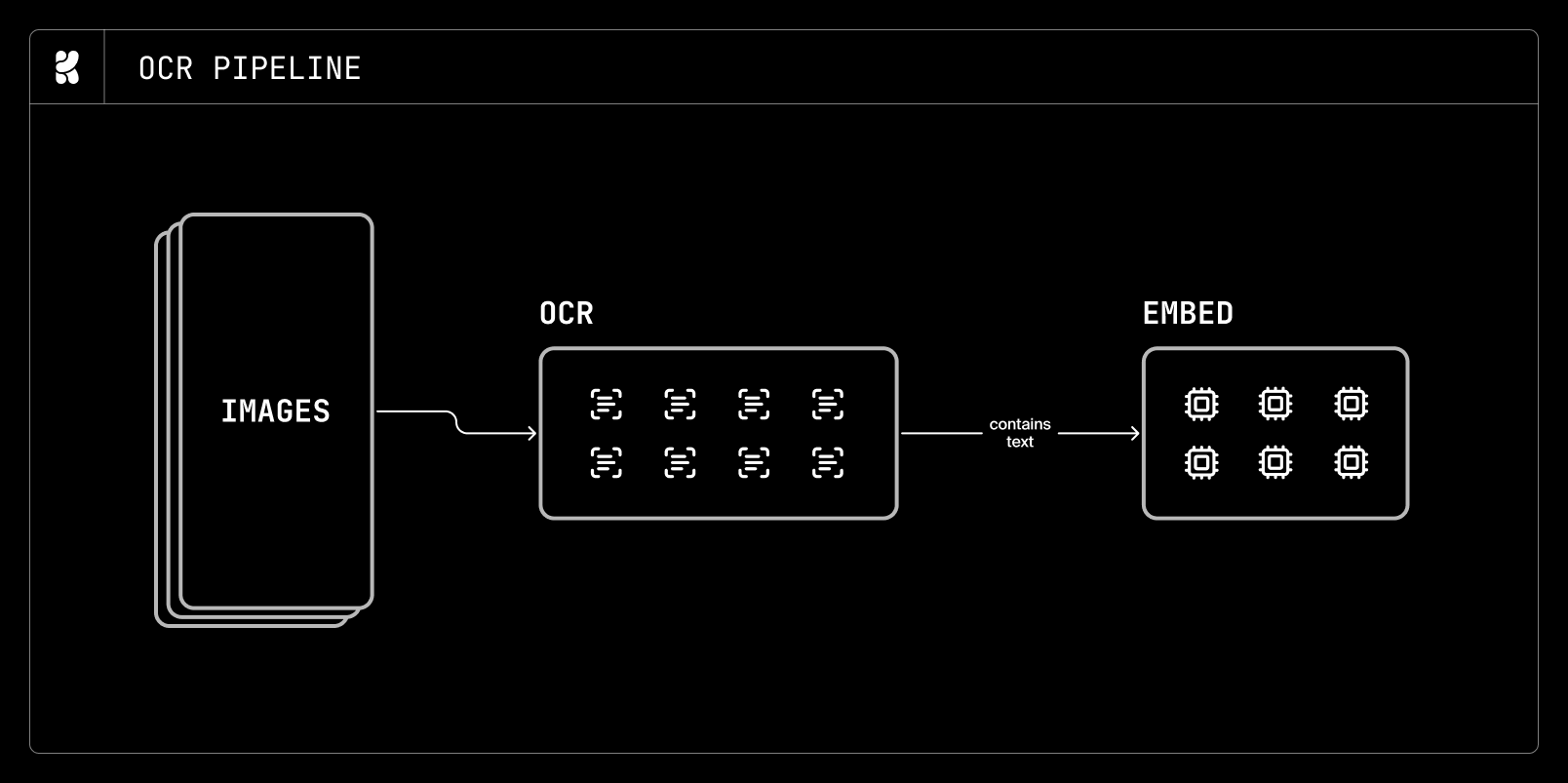
A typical job-processing workflow at Krea is laid out as follows. We first create a table, for example:
CREATE TABLE images (
image_name TEXT PRIMARY KEY,
contains_text BOOLEAN DEFAULT NULL,
ocr_last_tried_at TIMESTAMP DEFAULT NULL,
embedding_path TEXT DEFAULT NULL,
embed_last_tried_at TIMESTAMP DEFAULT NULL
)This table defines two jobs that can be performed for each image: OCR and embedding. The OCR workers run the following query to find rows to process:
-- OCR worker
WITH picked AS (
SELECT image_Name FROM images
WHERE contains_text IS NULL
ORDER BY ocr_last_tried_at NULLS FIRST
LIMIT 8
FOR UPDATE SKIP LOCKED
)
UPDATE images i
SET ocr_last_tried_at = NOW()
FROM picked p
WHERE i.id = p.id
RETURNING i.*and the embed workers run:
-- Embed worker
WITH picked AS (
SELECT id FROM images
WHERE embedding_path IS NULL
AND contains_text = FALSE -- Only process rows which have completed OCR and passed a filter
ORDER BY embed_last_tried_at NULLS FIRST
LIMIT 16
FOR UPDATE SKIP LOCKED
)
UPDATE images i
SET embed_last_tried_at = NOW()
FROM picked p
WHERE i.id = p.id
RETURNING i.*Implicitly, this processing workflow is a DAG (Directed Acyclic Graph):
Many large-scale data-processing systems, including Ray, Spark, and Daft, can process DAG workflows. However, treating these workflows as queues in this model gives us several practical benefits:
- Retries: Unlike Kafka or Ray, this system never drops rows on failure or sends them to a dead-letter queue (DLQ). Any row that fails processing, for any reason, is retried at the end of the queue (owing to the atomic update of
last_tried_at), which also prevents head-of-line blocking. - Fault tolerance: Any worker may crash at any time without crashing the entire job or losing progress. Many classes of failure, such as a bad GPU or a temporarily unavailable API, are in fact handled automatically through the system’s eventual retries.
- Dynamic worker count: We deploy our processing jobs with Kubernetes, and any deployment can be scaled up or down arbitrarily without resharding or moving data; a job may have one worker or one thousand. For many workloads, we expose a Prometheus scaling metric based on the
COUNT(*)of the claim query (for example,COUNT(*) WHERE embedding_path IS NULL AND contains_text = FALSE), which lets us autoscale each part of the pipeline according to the available work. - Partial processing: Because the results for each row are immediately durable in Postgres, one may process as little or as much of a table as desired; no single job ever needs to run to completion. This lets us take advantage of interruptible and spot priority classes for many processing jobs, running them only when spare capacity is available.
- Immediate visibility: Researchers can see the results of any job in visualization dashboards immediately and iterate continuously. They can also inspect the throughput of any part of the queue, for example with
SELECT COUNT(*) FROM images WHERE embed_last_tried_at > NOW() - INTERVAL '5 minutes'. - Heterogeneous batch sizes: Each worker may choose the batch size natural to it.
- Continuous incremental processing: We can continuously add new data to the system and let it flow through every stage without manually rerunning jobs, backfilling old rows, or tracking disparate stages.
For researcher convenience, we expose a system called “pluck” on top of this, which provides a global map API suitable for use in a notebook. For example:
def embed_func(batch): # users may also provide stateful Actors rather than one-off functions
...
t = pluck.Table(
"images", # table name
"image_name", # primary / shard key
"embedding_path IS NULL AND contains_text = FALSE", # condition
)
t.map(embed_func) # returns a handle the user can attach to in order to see live progressUnder the hood, pluck uses TABLESAMPLE and statistical estimates to partition the table’s keyspace and create a batch queue, which is then consumed with the same FOR UPDATE SKIP LOCKED semantics shown above. The user-defined function (UDF) is pickled with the cloudpickle library and executed on remote workers.
For the next generation of our research, our team is building a successor system that preserves the krablet and FOR UPDATE SKIP LOCKED queue semantics but stores data in LSM trees on object storage. If you are interested in working on this, our supercomputing / distributed systems team is hiring!
Discussion and Future Work
Although we have explored many directions across the stack, many promising research problems remain.
Scaling
For Krea 2, we made relatively conservative architecture and optimizer choices to prioritize stability and iteration speed. For our next pretraining cycle, we wish to adapt modern LLM transformer designs to the diffusion transformer, including MoE; scale to native 2K—4K resolution using sparse attention; pretrain in NVFP4; and scale with Muon, among other directions. Beyond architectural and algorithmic changes, we find that our current models are undertrained and would benefit from longer training.
Multi-teacher on-policy distillation (MOPD)
We conclude our current training pipeline with a multi-reward RL stage. In recent LLM literature, it has become common to train domain experts and distill their capabilities through dense expert supervision. Compared with methods such as model merging and offline distillation, MOPD has been shown to distill multiple experts into a single student without the different capabilities conflicting with one another. MOPD is also highly scalable from an organizational standpoint, as it allows different RL teams to focus purely on domain-specific capabilities without risking regressions elsewhere. We have already validated that both OPD and MOPD are effective distillation methods for diffusion models using our internal experts, and we hope to share more results soon.
Architectural simplification
At present, most production diffusion models require a complex set of interdependent models. Serving a latent diffusion model typically requires an autoencoder, a diffusion transformer, a text encoder, and a prompt-expansion model, and depending on the stack one may add further modules such as a style-reference model or an upscaler. Maintaining multiple components that require independent training and have mutual dependencies makes it inherently difficult for research teams to coordinate. This contrasts with LLM training pipelines, which center on a single unified model and allow research effort to be parallelized across data teams or across separate expert trainings for an MOPD stage; more importantly, it allows the research team to concentrate its scaling effort on a single model. For these reasons, we plan to simplify our architecture and unify the various components under a single model in our next pretraining cycle.
New capabilities
For Krea 2, we focused primarily on image generation for creative exploration. We aim to expand the capabilities of Krea models to include robust editing, image reference, and native 2K/4K generation. We are also increasingly finding that traditional natural-language prompting is no longer sufficient to support the full range of user requests. Across our user prompts, we observe a wide variety of prompting styles, including natural language, tags, detailed JSON, bounding boxes, instructions, visual guidelines, and Markdown, among others. While prompt expansion can address some of this, we believe that natively comprehending such prompts should also be a core capability of the model.
Conclusion
We presented Krea 2, our first foundation-model series built for creative exploration. In this technical report, we shared the infrastructure, data systems, training pipeline, and research choices behind the model family. We believe foundation image models are still in their early stages, and we look forward to sharing more of our research.
References (84)
-
Denoising diffusion probabilistic models. Ho, J., Jain, A. and Abbeel, P., 2020. Advances in Neural Information Processing Systems, Vol 33, pp. 6840—6851. Link
-
High-resolution image synthesis with latent diffusion models. Rombach, R., Blattmann, A., Lorenz, D., Esser, P. and Ommer, B., 2022. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10684—10695. Link
-
Flow straight and fast: Learning to generate and transfer data with rectified flow. Liu, X., Gong, C. and Liu, Q., 2022. arXiv preprint arXiv:2209.03003. Link
-
Flow matching for generative modeling. Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M. and Le, M., 2022. arXiv preprint arXiv:2210.02747. Link
-
Visual autoregressive modeling: Scalable image generation via next-scale prediction. Tian, K., Jiang, Y., Yuan, Z., Peng, B. and Wang, L., 2024. Advances in Neural Information Processing Systems, Vol 37, pp. 84839—84865. Link
-
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. Han, J., Liu, J., Jiang, Y., Yan, B., Zhang, Y., Yuan, Z., Peng, B. and Liu, X., 2025. Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 15733—15744. Link
-
Emu: Generative pretraining in multimodality. Sun, Q., Yu, Q., Cui, Y., Zhang, F., Zhang, X., Wang, Y., Gao, H., Liu, J., Huang, T. and Wang, X., 2024. International Conference on Learning Representations, Vol 2024, pp. 12352—12380. Link
-
Generative pretraining from pixels. Chen, M., Radford, A., Child, R., Wu, J., Jun, H., Luan, D. and Sutskever, I., 2020. International Conference on Machine Learning, pp. 1691—1703. PMLR. Link
-
Scaling autoregressive models for content-rich text-to-image generation. Yu, J., Xu, Y., Koh, J.Y., Luong, T., Baid, G., Wang, Z., Vasudevan, V., Ku, A., Yang, Y., Ayan, B.K. et al., 2022. arXiv preprint arXiv:2206.10789. Link
-
Maskgit: Masked generative image transformer. Chang, H., Zhang, H., Jiang, L., Liu, C. and Freeman, W.T., 2022. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11315—11325. Link
-
Scalable diffusion models with transformers. Peebles, W. and Xie, S., 2023. Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4195—4205. Link
-
Pixart-alpha: Fast training of diffusion transformer for photorealistic text-to-image synthesis. Chen, J., Yu, J., Ge, C., Yao, L., Xie, E., Wang, Z., Kwok, J., Luo, P., Lu, H. and Li, Z., 2024. International Conference on Learning Representations, Vol 2024, pp. 57611—57640. Link
-
Scaling rectified flow transformers for high-resolution image synthesis. Esser, P., Kulal, S., Blattmann, A., Entezari, R., Muller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F. et al., 2024. Forty-first International Conference on Machine Learning. Link
-
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. Ma, N., Goldstein, M., Albergo, M.S., Boffi, N.M., Vanden-Eijnden, E. and Xie, S., 2024. European Conference on Computer Vision, pp. 23—40. Springer. Link
-
Sdxl: Improving latent diffusion models for high-resolution image synthesis. Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Muller, J., Penna, J. and Rombach, R., 2024. International Conference on Learning Representations, Vol 2024, pp. 1862—1874. Link
-
FLUX. BlackForest, 2024. Link
-
FLUX.2: Frontier Visual Intelligence. Black Forest Labs, 2025. Link
-
FLUX.1 Kontext: Flow matching for in-context image generation and editing in latent space. Labs, B.F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dockhorn, T., English, J., English, Z., Esser, P. et al., 2025. arXiv preprint arXiv:2506.15742. Link
-
FLUX.1 Krea [dev]. Black Forest Labs and Krea, 2025. Link
-
Lumina-Image 2.0: A Unified and Efficient Image Generative Framework. Qin, Q., Zhuo, L., Xin, Y., Du, R., Li, Z., Fu, B., Lu, Y., Yuan, J., Li, X., Liu, D. et al., 2025. arXiv preprint arXiv:2503.21758. Link
-
Hunyuan-dit: A powerful multi-resolution diffusion transformer with fine-grained chinese understanding. Li, Z., Zhang, J., Lin, Q., Xiong, J., Long, Y., Deng, X., Zhang, Y., Liu, X., Huang, M., Xiao, Z. et al., 2024. arXiv preprint arXiv:2405.08748. Link
-
Qwen-image technical report. Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.M., Bai, S., Xu, X., Chen, Y. et al., 2025. arXiv preprint arXiv:2508.02324. Link
-
Longcat-image technical report. Team, M.L., Ma, H., Tan, H., Huang, J., Wu, J., He, J.Y., Gao, L., Xiao, S., Wei, X., Ma, X. et al., 2025. arXiv preprint arXiv:2512.07584. Link
-
JoyAI-Image: Awakening spatial intelligence in unified multimodal understanding and generation. Joy Future Academy, JD, 2026. Link
-
HunyuanImage-2.1. Tencent HY, 2025. Link
-
Hunyuanimage 3.0 technical report. Cao, S., Chen, H., Chen, P., Cheng, Y., Cui, Y., Deng, X., Dong, Y., Gong, K., Gu, T., Gu, X. et al., 2025. arXiv preprint arXiv:2509.23951. Link
-
Z-image: An efficient image generation foundation model with single-stream diffusion transformer. Cai, H., Cao, S., Du, R., Gao, P., Hoi, S., Hou, Z., Huang, S., Jiang, D., Jin, X., Li, L. et al., 2025. arXiv preprint arXiv:2511.22699. Link
-
Seedream 3.0 technical report. Gao, Y., Gong, L., Guo, Q., Hou, X., Lai, Z., Li, F., Li, L., Lian, X., Liao, C., Liu, L. et al., 2025. arXiv preprint arXiv:2504.11346. Link
-
Seedream 2.0: A native chinese-english bilingual image generation foundation model. Gong, L., Hou, X., Li, F., Li, L., Lian, X., Liu, F., Liu, L., Liu, W., Lu, W., Shi, Y. et al., 2025. arXiv preprint arXiv:2503.07703. Link
-
Seedream 4.0: Toward next-generation multimodal image generation. Seedream, T., Chen, Y., Gao, Y., Gong, L., Guo, M., Guo, Q., Guo, Z., Hou, X., Huang, W., Huang, Y. et al., 2025. arXiv preprint arXiv:2509.20427. Link
-
Seedream 5.0 Lite. ByteDance Seed, 2025. Link
-
GPT Image 1.5. OpenAI, 2025. Link
-
Nano Banana Pro. Google, 2025. Link
-
Qwen3-vl technical report. Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C. et al., 2025. arXiv preprint arXiv:2511.21631. Link
-
Auto-encoding variational bayes. Kingma, D.P. and Welling, M., 2013. arXiv preprint arXiv:1312.6114. Link
-
Flow-grpo: Training flow matching models via online rl. Liu, J., Liu, G., Liang, J., Li, Y., Liu, J., Wang, X., Wan, P., Zhang, D. and Ouyang, W., 2026. Advances in Neural Information Processing Systems, Vol 38, pp. 40783—40818. Link
-
Diffusionnft: Online diffusion reinforcement with forward process. Zheng, K., Chen, H., Ye, H., Wang, H., Zhang, Q., Jiang, K., Su, H., Ermon, S., Zhu, J. and Liu, M.Y., 2025. arXiv preprint arXiv:2509.16117. Link
-
Improved aesthetic predictor (LAION-Aesthetics Predictor V2). Schuhmann, C., 2022. GitHub repository, christophschuhmann/improved-aesthetic-predictor. Link
-
ArtiMuse: Fine-Grained Image Aesthetics Assessment with Joint Scoring and Expert-Level Understanding. Cao, S., Ma, N., Li, J., Li, X., Shao, L., Zhu, K., Zhou, Y., Pu, Y., Wu, J., Wang, J. et al., 2025. arXiv preprint arXiv:2507.14533. Link
-
UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture. Cao, S., Li, J., Li, X., Pu, Y., Zhu, K., Gao, Y., Luo, S., Xin, Y., Qin, Q., Zhou, Y. et al., 2025. arXiv preprint arXiv:2512.21675. Link
-
DINOv3. Simeoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M. et al., 2025. arXiv preprint arXiv:2508.10104. Link
-
SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features. Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B. et al., 2025. arXiv preprint arXiv:2502.14786. Link
-
Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach. Vo, H.V., Khalidov, V., Darcet, T., Moutakanni, T., Smetanin, N., Szafraniec, M., Touvron, H., Couprie, C., Oquab, M., Joulin, A. et al., 2024. arXiv preprint arXiv:2405.15613. Link
-
GLU Variants Improve Transformer. Shazeer, N., 2020. arXiv preprint arXiv:2002.05202. Link
-
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebron, F. and Sanghai, S., 2023. arXiv preprint arXiv:2305.13245. Link
-
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. DeepSeek-AI et al., 2024. arXiv preprint arXiv:2405.04434. Link
-
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free. Qiu, Z., Wang, Z., Zheng, B., Huang, Z., Wen, K., Yang, S., Men, R., Yu, L., Huang, F., Huang, S. et al., 2025. arXiv preprint arXiv:2505.06708. Link
-
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers. Xie, E., Chen, J., Chen, J., Cai, H., Tang, H., Lin, Y., Zhang, Z., Li, M., Zhu, L., Lu, Y. et al., 2024. arXiv preprint arXiv:2410.10629. Link
-
On N-dimensional Rotary Positional Embeddings. Xiong, J., 2025. Blog post, jerryxio.ng. Link
-
Deep compression autoencoder for efficient high-resolution diffusion models. Chen, J., Cai, H., Chen, J., Xie, E., Yang, S., Tang, H., Li, M., Lu, Y. and Han, S., 2025. International Conference on Learning Representations, Vol 2025, pp. 96539—96560. Link
-
Root mean square layer normalization. Zhang, B. and Sennrich, R., 2019. Advances in Neural Information Processing Systems, Vol 32. Link
-
UniFusion: Vision-Language Model as Unified Encoder in Image Generation. Li, K., Brack, M., Katakol, S., Ravi, H. and Kale, A., 2025. arXiv preprint arXiv:2510.12789. Link
-
Model Merging in Pre-training of Large Language Models. Li, Y., Ma, Y., Yan, S., Zhang, C., Liu, J., Lu, J., Xu, Z., Chen, M., Wang, M., Zhan, S. et al., 2025. arXiv preprint arXiv:2505.12082. Link
-
Diffusion Model Alignment Using Direct Preference Optimization. Wallace, B., Dang, M., Rafailov, R., Zhou, L., Lou, A., Purushwalkam, S., Ermon, S., Xiong, C., Joty, S. and Naik, N., 2023. arXiv preprint arXiv:2311.12908. Link
-
FireRed-Image-Edit-1.0 Technical Report. Super Intelligence Team, Qiao, C., Hui, C., Li, C., Wang, C., Song, D., Zhang, J., Li, J., Xiang, Q., Wang, R. et al., 2026. arXiv preprint arXiv:2602.13344. Link
-
Directly Fine-Tuning Diffusion Models on Differentiable Rewards. Clark, K., Vicol, P., Swersky, K. and Fleet, D.J., 2023. arXiv preprint arXiv:2309.17400. Link
-
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation. Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J. and Dong, Y., 2023. arXiv preprint arXiv:2304.05977. Link
-
Directly Aligning the Full Diffusion Trajectory with Fine-Grained Human Preference. Shen, X., Li, Z., Yang, Z., Zhang, S., Zhang, Y., Li, D., Wang, C., Lu, Q. and Tang, Y., 2025. arXiv preprint arXiv:2509.06942. Link
-
Classifier-Free Diffusion Guidance. Ho, J. and Salimans, T., 2022. arXiv preprint arXiv:2207.12598. Link
-
One-step diffusion with distribution matching distillation. Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T. and Park, T., 2024. IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6613—6623. Link
-
Improved distribution matching distillation for fast image synthesis. Yin, T., Gharbi, M., Park, T., Zhang, R., Shechtman, E., Durand, F. and Freeman, W.T., 2024. Advances in Neural Information Processing Systems, pp. 47455—47487. Link
-
Decoupled DMD: CFG Augmentation as the Spear, Distribution Matching as the Shield. Liu, D., Gao, P., Liu, D., Du, R., Li, Z., Wu, Q., Jin, X., Cao, S., Zhang, S., Li, H. et al., 2025. arXiv preprint arXiv:2511.22677. Link
-
pi-Flow: Policy-Based Few-Step Generation via Imitation Distillation. Chen, H., Zhang, K., Tan, H., Guibas, L., Wetzstein, G. and Bi, S., 2025. arXiv preprint arXiv:2510.14974. Link
-
Diffusion Adversarial Post-Training for One-Step Video Generation. Lin, S., Xia, X., Ren, Y., Yang, C., Xiao, X. and Jiang, L., 2025. arXiv preprint arXiv:2501.08316. Link
-
Learning Few-Step Diffusion Models by Trajectory Distribution Matching. Luo, Y., Hu, T., Sun, J., Cai, Y. and Tang, J., 2025. arXiv preprint arXiv:2503.06674. Link
-
HPSv3: Towards Wide-Spectrum Human Preference Score. Ma, Y., Shui, Y., Wu, X., Sun, K. and Li, H., 2025. arXiv preprint arXiv:2508.03789. Link
-
EvalMuse-40K: A Reliable and Fine-Grained Benchmark with Comprehensive Human Annotations for Text-to-Image Generation Model Evaluation. Han, S., Fan, H., Fu, J., Li, L., Li, T., Cui, J., Wang, Y., Tai, Y., Sun, J., Guo, C. et al., 2024. arXiv preprint arXiv:2412.18150. Link
-
Adam: A Method for Stochastic Optimization. Kingma, D.P. and Ba, J., 2014. arXiv preprint arXiv:1412.6980. Link
-
Muon is Scalable for LLM Training. Liu, J., Su, J., Yao, X., Jiang, Z., Lai, G., Du, Y., Qin, Y., Xu, W., Lu, E., Yan, J. et al., 2025. arXiv preprint arXiv:2502.16982. Link
-
What matters for Representation Alignment: Global Information or Spatial Structure? Singh, J., Leng, X., Wu, Z., Zheng, L., Zhang, R., Shechtman, E. and Xie, S., 2025. arXiv preprint arXiv:2512.10794. Link
-
Kimi K2.6. Moonshot AI, 2026. Link
-
Delta Attention Residuals. Luo, C., Cai, Z. and Hu, J., 2026. arXiv preprint arXiv:2605.18855.
-
Is Noise Conditioning Necessary for Denoising Generative Models? Sun, Q., Jiang, Z., Zhao, H. and He, K., 2025. arXiv preprint arXiv:2502.13129.
-
LAuReL: Learned Augmented Residual Layer. Menghani, G., Kumar, R. and Kumar, S., 2024. arXiv preprint arXiv:2411.07501.
-
Improved Mean Flows: On the Challenges of Fastforward Generative Models. Geng, Z., Lu, Y., Wu, Z., Shechtman, E., Kolter, J.Z. and He, K., 2025. arXiv preprint arXiv:2512.02012.
-
Attention Residuals. Kimi Team, Chen, G., Zhang, Y., Su, J., Xu, W., Pan, S., Wang, Y., Wang, Y. et al., 2026. arXiv preprint arXiv:2603.15031.
-
NOBLE: Accelerating Transformers with Nonlinear Low-Rank Branches. Smith, E., 2026. arXiv preprint arXiv:2603.06492.
-
mHC: Manifold-Constrained Hyper-Connections. Xie, Z., Wei, Y., Cao, H., Zhao, C., Deng, C., Li, J., Dai, D., Gao, H. et al. (DeepSeek-AI), 2025. arXiv preprint arXiv:2512.24880.
-
Gemma: Open Models Based on Gemini Research and Technology. Gemma Team, 2024. arXiv preprint arXiv:2403.08295.
-
Layer Normalization. Ba, J.L., Kiros, J.R. and Hinton, G.E., 2016. arXiv preprint arXiv:1607.06450.
-
Gaussian Error Linear Units (GELUs). Hendrycks, D. and Gimpel, K., 2016. arXiv preprint arXiv:1606.08415.
-
TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training. Krause, F., Phan, T., Gui, M., Baumann, S.A., Hu, V.T. and Ommer, B., 2025. arXiv preprint arXiv:2501.04765.
-
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning. Fu, W., Gao, J., Shen, X., Zhu, C., Mei, Z., He, C., Xu, S., Wei, G. et al., 2025. arXiv preprint arXiv:2505.24298.
-
PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence Generation. Piche, A., Kamalloo, E., Pardinas, R., Chen, X. and Bahdanau, D., 2025. arXiv preprint arXiv:2509.19128.
Citation
@misc{krea-2-2026,
author={Sangwu Lee, Erwann Millon, Le Zhuo, Matthew Newton, Andrei Filatov, Abhinay Devarinti, Andrei Filatov, Elea Zhong, Avram Djordjevic, Gabriel Menezes, Will Beddow, Titus Ebbecke, Mihai Petrescu, Owen Fahey, Gian Saß, Felix Gil, Victor Perez},
title={{Krea 2}},
year={2026},
howpublished={\url{https://www.krea.ai/blog/krea-2-technical-report}},
}