A good portion of my week was consumed by life admin, end-of-batch activities for Recurse, and playing catchup on my overdue task backlog. And as the seasons change, daylight savings kicks in, and US election mania proliferates; so too does the darkness consume everything.
Despite all of that, I still made things, read things, and wrote things — here are a few you might enjoy.
Never graduate from RC
This was my 12th and final week at The Recurse Center (RC) which meant a bittersweet never graduation. I’ve tracked what I learned and built throughout the process, but I’ll be doing a big post about the whole experience in coming weeks. Stay tuned.
That also meant the final group meetings for ML Paper Cuts, Graphics, and Game Dev. Many of those were a bit sentimental as we reflected on what we’d done and how we’d grown. But most groups are continuing and I’ll certainly be involved in a few RC groups going forward.
We also did some writing and receiving of niceties — some kind words to other Recursers about our experiences interacting with them during the batch. This is a great tradition at RC and far more meaningful than any graduation ceremonies.
Aside from all this sentimentality, some technical work was also done.
Becoming an armchair physicist to make a game
I spend many hours studying orbital mechanics and applying the theory to my Orbital sim/game that I’ve written about the past few weeks. I mainly worked on streamlining the planetary data file and fixing bugs with inherited rotation in satellites, before moving on to work on dynamic orbit changes for spacecraft under acceleration. So far it’s working on my dev branch for elliptic orbits below an eccentricity of 1.
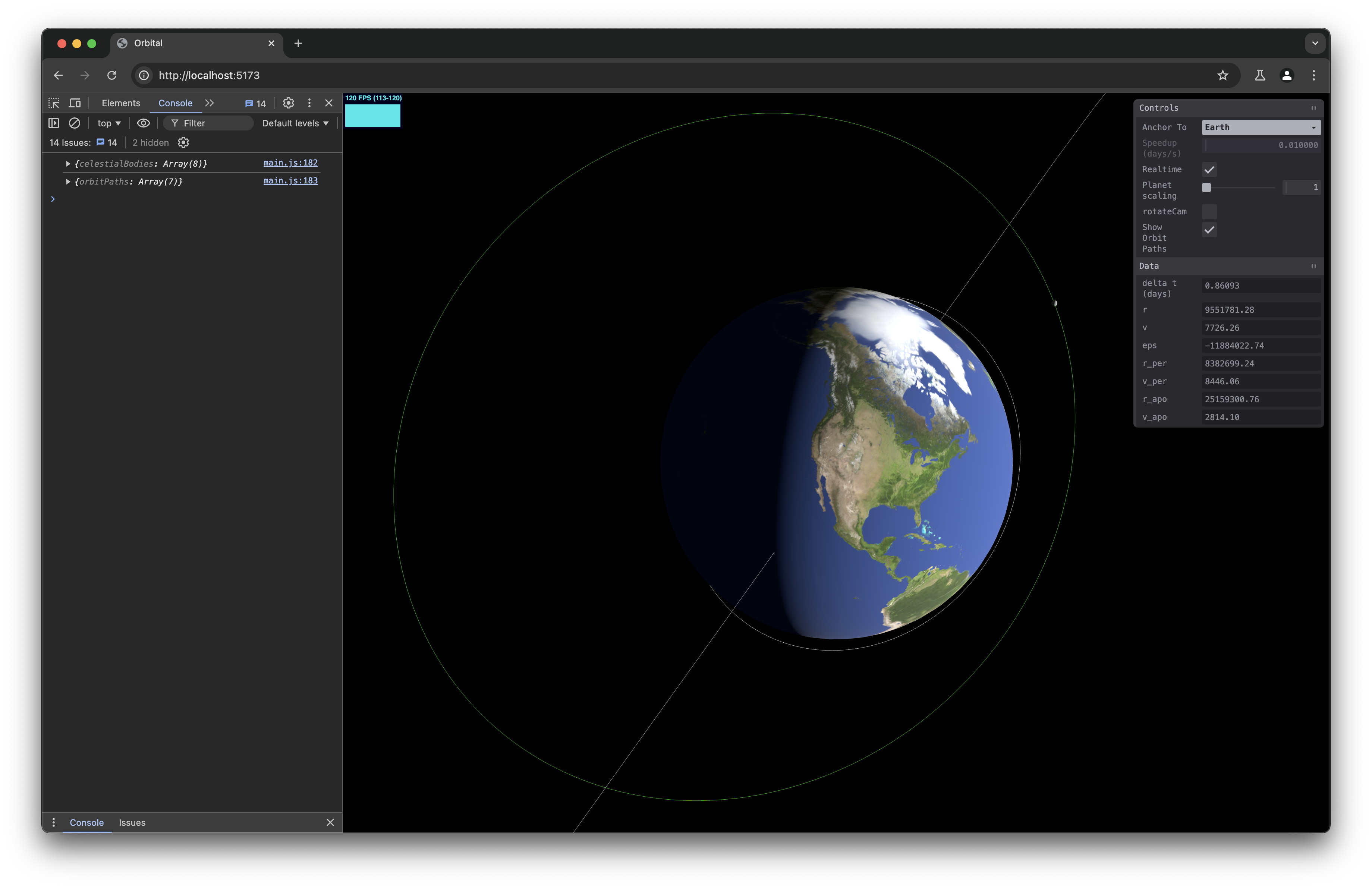
I also had a little diversion into loading a detailed 3D model of the ISS to replace the sphere I’ve been using as a stand-in. But that ended up being a pain because model loading in Three.js seems to use JavaScript promises, so I’d have to majorly refactor my code so that the model can fully load and be rotated/scaled appropriately before the script progresses. So I’ve tabled that for another time.
Revisiting AlphaGo and co.
For the ML Paper Cuts group, we studied the AlphaGo-AlphaZero-MuZero family of reinforcement learning models from DeepMind. I covered some aspects of these shortly after they came out, but it was highly instructive to revisit them years later as a progression. Krishna did an exceptionally-thorough job of collecting resources and covering all the material the group needed to get a deep understanding — the dynamics of Go, Chess, and Shogi; Monte Carlo Tree Search; Reinforcement Learning (Value, Policy, and combined networks); etc.
Suggestion: Check out this colloquium talk by Thore Graepel who worked on them.
One of the high-level observations is how both the performance and generality of the approaches has increased as the degree of human expert knowledge decreased. Old Chess engines are thousands of hand-coded heuristics informed by professional players. AlphaGo mostly learned from previous Go matches between human experts, supplemented with some self play. AlphaZero was even better without looking at any human data and only learning from self play. MuZero generalises to arbitrary games and learns a latent representation of the action space, so it also learns the rules of the game as well as how to play well.
A weird observation is that these ideas were the absolute cutting edge of AI research in 2019, but then were eclipsed by these things called LLMs and diffusion models. The labs claim that RL is still a key part of how they build frontier models, but we haven’t been told specifics about that since the RLHF paper.
More dotfiles fiddling: Tmux edition
I updated my Tmux config to conditionally renames panes based on the directory (if bash or zsh or nvim) else the program running.
- Conditional tmux pane renaming based on directory/program. · gianlucatruda/dotfiles@26bea0d · GitHub
- Update tmux pane renaming to show directory if in nvim. · gianlucatruda/dotfiles@e18059c · GitHub
Ideas and links
- With all my space/orbital browsing, I recently rediscovered this 1-minute clip of the greatest shot in television and I can confirm it is still the greatest.
- Lindsay Ellis’ wildly interesting video essay on Yoko and The Beatles. It’s only 60% about that specific thing and it’s full of interesting anecdotes and ideas I hadn’t considered, as well as being exceptionally well made.
- Paul Graham’s latest Writes and Write-Nots is full of pithy bangers and motivation to prioritise writing. A quick but invaluable read for anyone.
- Gavin Leech on Nonmonetary Payoffs to Starting a Company, which I found relatable but hadn’t thought about explicitly. A useful framing.
- We have general purpose AI systems in our pockets but nobody really cares, which is why this guy will fucking piledrive you if you mention AI again.
- Inspired by this work of art I’m working on an even more devastating name for my next company registration.
- The inimitable Yacine finally got interviewed and the aspie-Chad vibes are so good. A really fun listen while doing housework.
Thanks for reading! I’ll be back next week.
Find previous weeknotes here.