After seven years in the works, I’m happy to report that the No Bullshit Guide to Statistics is finally done and available as a digital download from Gumroad: gum.co/noBSstats. The book ended up being 1100 pages long and so I had to split it into two parts: Part 1 covers prerequisites (DATA and PROB), then Part 2 covers statistical inference topics: classical (frequentist) statistics, linear models, and Bayesian statistics.
The prerelease price is US\$34, which is a 50% discount for all the true fans who signed up to the “Interested in Stats” mailing list. See below for the table of contents, links to preview PDFs, and an explanation about why the book took so long to ship.
TL;DR: Ivan ventures into the statistics mountains, faces many uphills, but is not a quitter, so comes out alive, bringing back a condensed guide to statistical inference topics (Part 2; 656 pages) and prerequisites (Part 1; 433 pages).
Backstory
I’d like to share a bit about how I got tricked into writing a stats book.
In the past, I’ve made a reputation as a math tutor who can explain complicated concepts in a clear and concise manner. After teaching math and physics for 17 years, I collected enough material to write a book on high school math, mechanics, and calculus. Five years later, I wrote another book on linear algebra. These books have been widely successful, and readers appreciate the No Bullshit Guide approach to explaining concepts intuitively and with prerequisites included.
Fans of these books encouraged me to continue writing on other topics. In particular, many readers requested that I write a book on statistics, a topic they find difficult and confusing. Following the startup principle of “listen to your customers,” I decided to write a book on statistics. I had taken a STATS 101 class many years ago, and I figured I just needed to brush up my stats knowledge. I thought to myself, “How hard could this possibly be?”
Pretty hard, it turns out!
I started working on this book back in 2018 and initially made good progress covering the standard STATS101 topics. However, I ran into problems when I tried to explain the logic behind statistics procedures. It didn’t take me long to realize that the standard STATS101 curriculum based around teaching statistical analysis recipes is problematic. As a teacher, I feel it is my duty to explain how things work, not ask readers to memorize a bunch of formulas…
Luckily there is a better way. The modern statistics curriculum relies on computation to provide learners with a more direct, intuitive way to understand statistics procedures. Instead of relying on analytical approximation formulas pulled out of thin air, we can use a Python for-loop to generate random samples and observe the variability in the estimates. I wrote a blog post “Fixing the introductory statistics curriculum” that explains the advantages of the modern computation-first curriculum, which captures the enthusiasm I was experiencing when I had this realization.
Adopting the modern curriculum protects readers from math complexity, but there is a trade-off: readers need to have at least basic coding skills in order to follow the Python code examples. People signed up to learn STATS, but I’m telling them they have to learn Python first.
Initially, this seemed like a problem, but it’s not that bad, actually. You don’t need to become a Python programmer, you just need to know how to use Python as a calculator, as described in this blog post “Python coding skills for statistic.” The solution I came up with is to include a Python tutorial in Appendix C of the book. Click here to run the tutorial as an interactive notebook in the cloud.
Once I had the computational plan of attack figured out, the writing process was much smoother. It still took me three years to write and edit the No Bullshit Guide to Statistics, but that’s because of the inherent complexity of the subject and the breadth of topics I decided to cover (both frequentist and Bayesian inference).
Y’all asked me to write a book on statistics, so you know you’re going to get a full account on the subject!
My journey learning and writing about statistics often felt like riding a bicycle uphill in a mountainous region. Statistics is full of conceptual complexity, math complexity, important technical details, methodological conventions, historical baggage, etc. With each difficulty I faced as a learner, my motivation for writing the book increased, because I saw how I could bring value to No Bullshit Guide readers, by making their journey into the statistics mountains easier. Everyone has to face the same uphills, but having a guide makes the journey more straightforward.
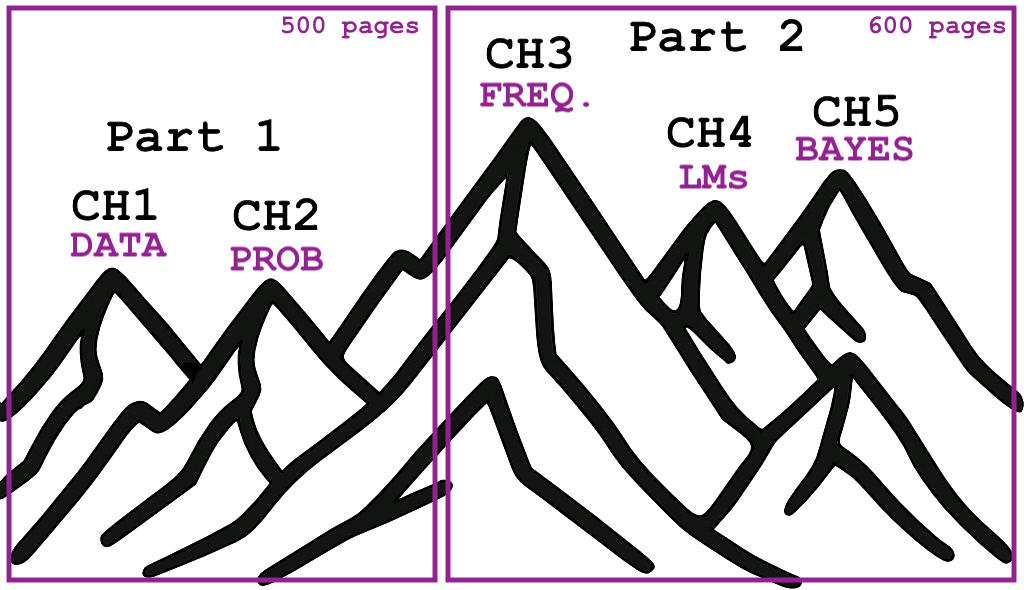 Figure 1. Learning statistics is like a bike ride with lots of uphills. Part 1 of the book covers all the essential prerequisites, and prepares the readers for the big statistical inference hills in Part 2 of the book.
Figure 1. Learning statistics is like a bike ride with lots of uphills. Part 1 of the book covers all the essential prerequisites, and prepares the readers for the big statistical inference hills in Part 2 of the book.
The book
The book comes in two parts: Part 1 is about prerequisites like DATA and PROBABILITY, while Part 2 is about statistical inference.
Part 1: DATA and PROB prerequisites
This is where you’ll learn practical skills for data management and probability calculations.
- CH1. DATA [93pp]
- CH2. PROBABILITY THEORY [187pp]
- Appendix:
- Python tutorial [50pp, see also bit.ly/pytut3 ] = using Python as a fancy calculator
- Pandas tutorial [60pp] = hands-on data management skills
- Seaborn tutorial [40pp] = essential data visualizations skills
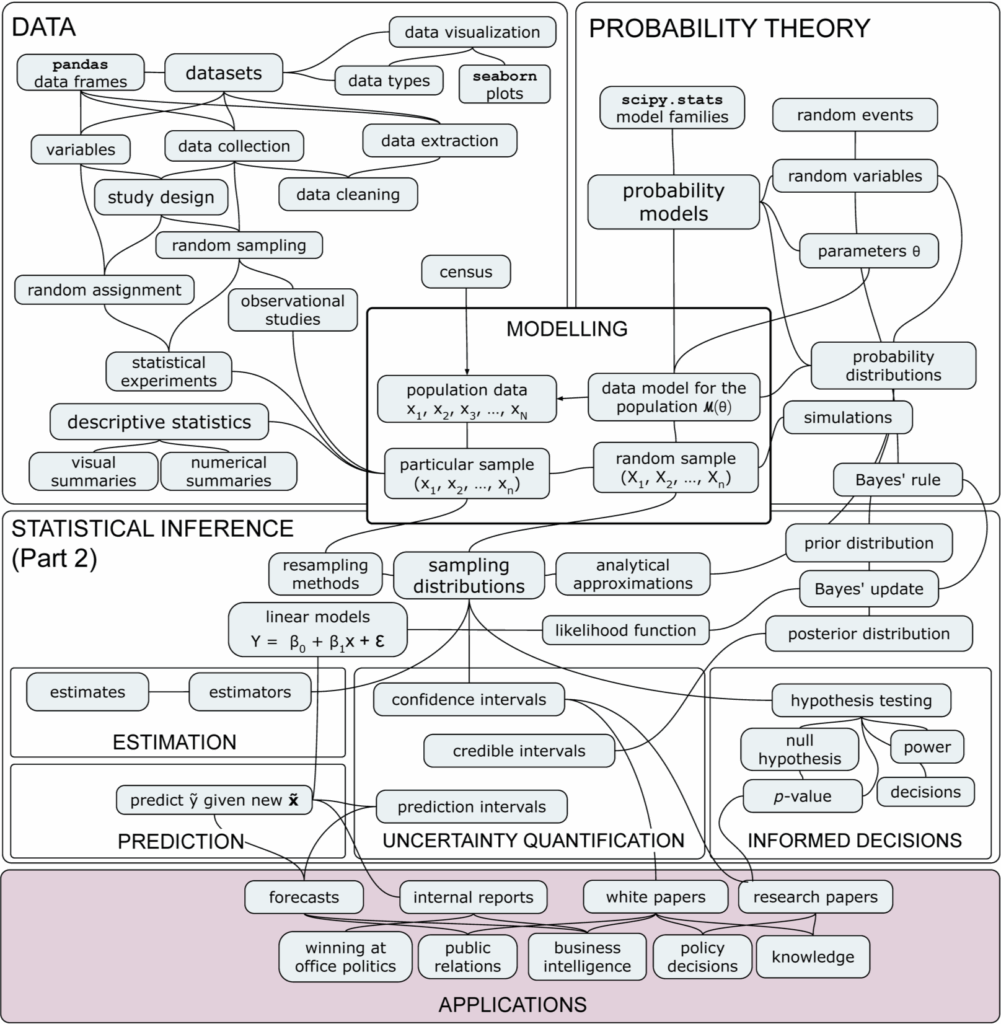
Figure 2. Overview of the topics and concepts from Part 1 of the book.
You can see an extended preview of Part 1 here: noBSstats_part1_preview.pdf [223pp, 9MB].
Figure 3 illustrates how the prerequisites covered in Part 1 form the foundation of statistical inference topics covered in Part 2 of the book.
If you want to learn statistics, then you need to know about data management and probability models. This is why the Part 1 of the book covers these prerequisite topics. The goal is to make the book self-contained, so readers from all backgrounds will be able to handle the statistical inference topics covered in Part 2 of the book.
If you’re a non-technical reader and you’re starting to get worried that the book will require too much coding, I suggest you flip through the PDF preview and look at the code examples. You’ll see that we’re not doing any programming, but just using Python as a calculator. That being said, I hope that by the end of the book you know Python at least a little bit better, which will open many doors for you.
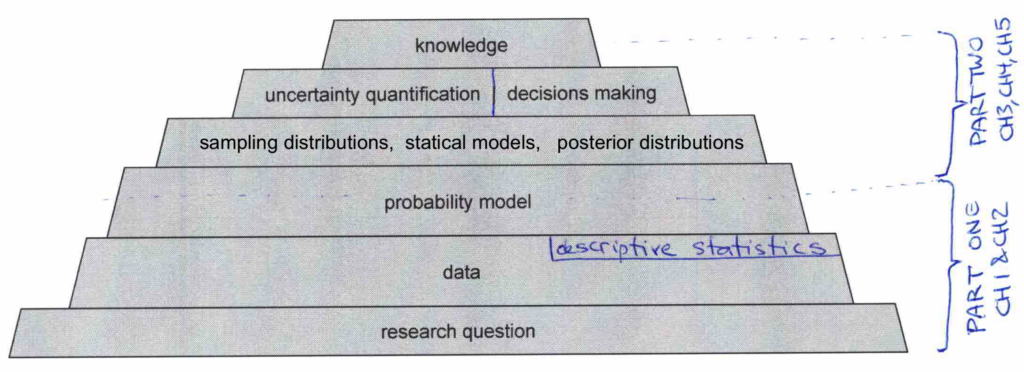
Figure 3. Savov’s ziggurat of statistical needs. Part 1 of the book establishes the foundation of data skills and probability models. In Part 2, we’ll use probability models for statistical inference including classical statistics based on sampling distributions (Chapter 3), linear models (Chapter 4), and Bayesian statistics (Chapter 5). Statistical inference deliverables include uncertainty quantification, and decision making, and ultimately knowledge.
Part 2: STATISTICAL INFERENCE
Part 2 of the book is about statistical inference, which is the process of learning about the properties of an unknown population based on a representative sample taken from that population. It covers the standard topics for a first-year STAT101 university-level course, as well as modern statistics topics like resampling methods and Bayesian inference.
- CH3. CLASSICAL STATISTICS [274pp]
- CH4. LINEAR MODELS [154pp]
- CH5. BAYESIAN STATISTICS [184pp]
You can see an extended preview of Part 2 here: noBSstats_part2_preview.pdf [191pp, 16MB].
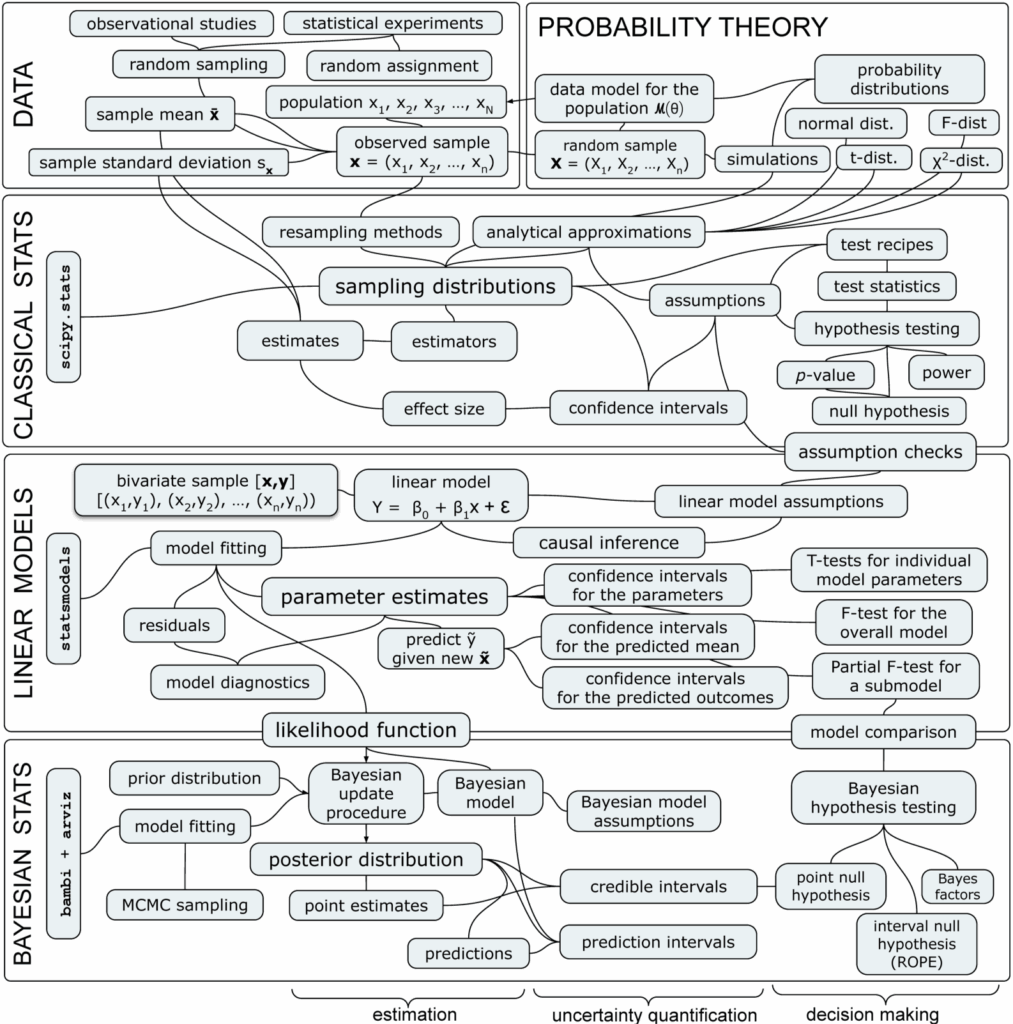
Figure 4. Concept map showing the topics covered in Part 2 of the book.
If this list of subjects and topics looks like the kind of journey you want to take, then head over to Gumroad and get your copy: gum.co/noBSstats. The prerelease purchase today includes all future updates to the book.
Good news; bad news
The good news is that I’m going to teach you everything I know about statistics. We’ll start by building a solid foundation of DATA and PROB knowledge in Part 1 of the book, which will enable you to deeply understand the statistical inference topics in Part 2. You’ll learn multiple approaches for doing statistical calculations: analytical (math formulas) and computational (Python code). Part 2 of the book covers the standard topics from STATS101, but also includes topics normally covered in more advanced courses like linear models, causal inference, and Bayesian statistics. I’m not taking sides in the ongoing debate that opposes frequentist and Bayesian statisticians, but instead making sure readers know about all the essential procedures in the statistics toolbox, both frequentist and Bayesian.
The bad news is that I’m going to teach you everything I know about statistics. If you were looking for some “light reading” material that hides the computational details, then this book is not for you. The book gets into the nitty-gritty details! You’ll learn about dealing with messy datasets, study design, sampling procedures, and other practical skills that you need to know to work with real datasets. We’ll also dive deep into probability machinery, which means you’ll have to learn about fancy math expression like summations $\sum_{i=1}^n x_i$ and integrals $\int_{x=a}^{x=b} f_X(x) dx$. You have to trust me that the math complexity I’ll expose you to is necessary complexity—this is what will allow you to understand statistics procedures. You’ll also have to become comfortable with Python code for performing statistical procedures. The dual explanations of stats concepts as math and code will keep us honest: if the answers we obtain using math formulas are the same as the answers we obtain by running Python simulations, then we can be sure that we know what’s going on.
I had to teach myself statistics at the graduate level in order to write concisely about undergraduate statistics and to know which topics to focus on. Now you can benefit from this experience.
Acknowledgements
This book would not have been possible without help of my friend and collaborators who supported me in this crazy quest. First and foremost, I want to thank Robyn Thiessen-Bock who helped me nail down the outline of the book, and co-authored early drafts of the descriptive statistics and hypothesis testing sections with me. My friend Patrick Mineault helped me tune the scope of the book and reviewed the probability chapter in great detail. Many thanks to Edith Viau who helped me fine-tune the data chapter through her meticulous review. I want to thank Chelsea “the chatistician” Parlett-Pelleriti who provided her expert opinion of all the statistical inference topics in Part 2 of the book, keeping me focused on topics of practical importance, and cutting “legacy” topics that are no longer relevant today. The book also benefited from the feedback of many test readers. In particular, the collaboration with Alex Park during the last two years was the most impactful: he reviewed every single section from the book and provided detailed feedback. Thank you all!
Next steps
The book content has been finalized, but it’s not quite done yet. Before I send the book for the first printing, I have some “loose ends” I need to fix, including:
- Add more exercises and problem sets with solutions.
- Prepare computational notebooks with the solutions to all the exercises and problems from the book. If anyone is interested in contribute, I’m open to PRs on the book’s repo: https://github.com/minireference/noBSstats/
- I want to replace some of the hand-drawn figures with higher quality graphics.
- I need to add a glossary and an index of terms.
- I will continue adding videos to the tutorials playlist.
Once these tasks are complete, I’ll go for the first printing (v1.0, a.k.a. First edition). Your purchase of the prerelease (v0.9) from Gumroad today includes the final v1.0 edition, and all future updates to the book (you’ll get email notifications when I upload new PDFs on Gumroad).
Call to action
It’s very simple. If you want to learn statistics, you need to get the book!
Click here to get the book: gum.co/noBSstats
Your purchase includes:
- The PDFs of the two parts of the book:
- noBSstats_part1.pdf [433pp, 13MB]
- noBSstats_part2.pdf [656pp, 31MB]
- Reading guide that tells you where you should start depending on your background, and what you should focus on.
- All future updates to the book.
I realize I’m asking you to fork out US\$34 and several weeks of your mental energy required to learn statistics. The final price for the eBooks will be \$29 + \$39 = \$68, so half price of that is \$34. That’s a good deal, no?
Free stuff
If you’re not ready to accept STATS in your heart yet, then you can check out the free resources developed for the book in the meantime:
- Book preview PDFs: noBSstats_part1_preview.pdf and noBSstats_part2_preview.pdf
- Tables of contents of Part 1 and Part 2.
- Book outline (open for comments and suggestions).
- Concept maps form the books: statistics_concepts.pdf
- Run the Python tutorial in JupyterLab in the cloud: https://bit.ly/pytut3
- Collection of links to statistics learning resources cited in the book.
- The book website is noBSstats.com
- The computational notebooks form the book:
- You can view them online at noBSstats.com/notebooks/
- Play in the notebooks in the cloud here:
- Or run the notebooks locally by following the instructions here.
- A playlist with video tutorials for Chapter 3 (the most complicated stuff).
- Previous blog posts about statistics:
- https://minireference.com/blog/fixing-the-statistics-curriculum/
- https://minireference.com/blog/no-bullshit-guide-to-statistics-progress-update/
- https://minireference.com/blog/what-stats-do-people-want-to-learn/
- https://minireference.com/blog/python-for-stats/
- https://minireference.com/blog/noBSstats-sales-pitch/
- Sign up to the mailing list to be notified about future updates.