My LinkedIn and Twitter feeds are full of screenshots from the recent Forbes article on Cursor claiming that Anthropic's $200/month Claude Code Max plan can consume $5,000 in compute. The relevant quote:
Today, that subsidization appears to be even more aggressive, with that $200 plan able to consume about $5,000 in compute, according to a different person who has seen analyses on the company's compute spend patterns.
This is being shared as proof that Anthropic is haemorrhaging money on inference. It doesn't survive basic scrutiny.
What the $5,000 figure actually is
I'm fairly confident the Forbes sources are confusing retail API prices with actual compute costs. These are very different things.
Anthropic's current API pricing for Opus 4.6 is $5 per million input tokens and $25 per million output tokens. At those prices, yes - a heavy Claude Code Max 20 user could rack up $5,000/month in API-equivalent usage. That maths checks out.
But API pricing is not what it costs Anthropic to serve those tokens.
The OpenRouter reality check
The best way to estimate what inference actually costs is to look at what open-weight models of similar size are priced at on OpenRouter - where multiple providers compete on price.
Qwen 3.5 397B-A17B is a good comparison point. It's a large MoE model, broadly comparable in architecture size to what Opus 4.6 is likely to be. Equally, so is Kimi K2.5 1T params with 32B active, which is probably approaching the upper limit of what you can efficiently serve.
Here's what the pricing looks like:
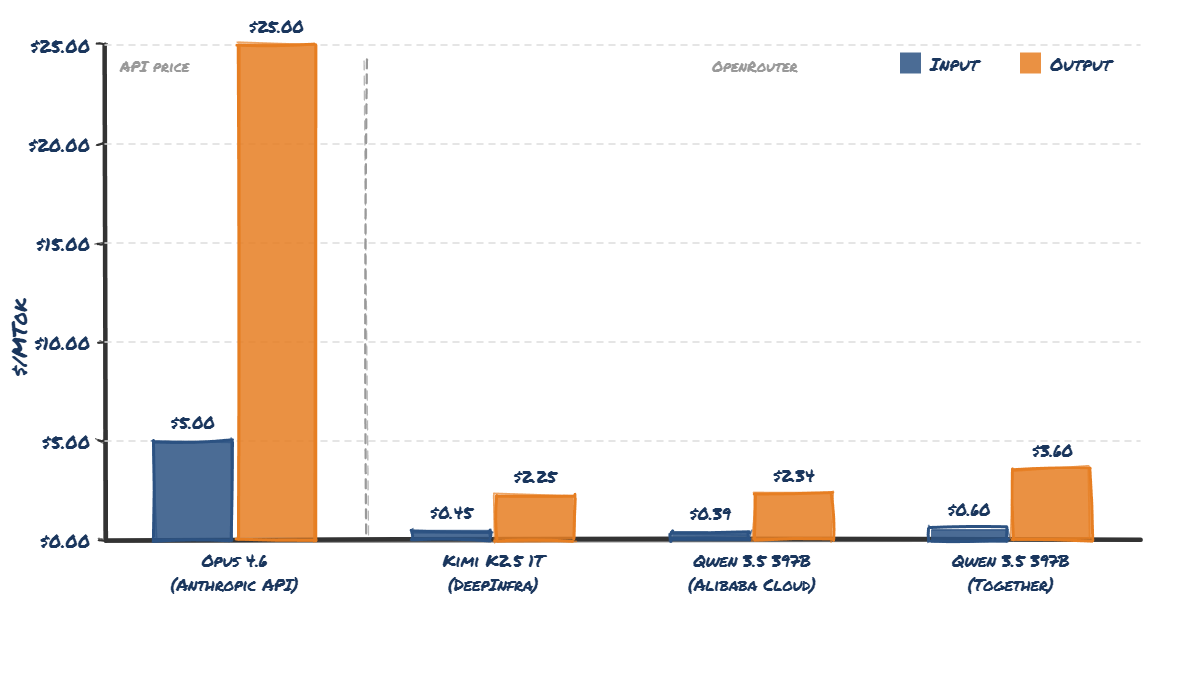 The Qwen 3.5 397B model on OpenRouter (via Alibaba Cloud) costs _$0.39_ per million input tokens and _$2.34_ per million output tokens. Compare that to Opus 4.6's API pricing of $5/$25. Kimi K2.5 is even cheaper at $0.45 per million input tokens and $2.25 output.
The Qwen 3.5 397B model on OpenRouter (via Alibaba Cloud) costs _$0.39_ per million input tokens and _$2.34_ per million output tokens. Compare that to Opus 4.6's API pricing of $5/$25. Kimi K2.5 is even cheaper at $0.45 per million input tokens and $2.25 output.