Last year, I visited my grandmother's house for the first time after the pandemic and came across a cupboard full of loose old photos. I counted 1,351 of them spanning all the way from my grandparents in their early 20s, my mom as a baby, to me in middle school, just around the time when we got our first smartphone and all photos since then were backed up online.


Everything was all over the place so I spent some time going through them individually and organizing them into groups. Some of the initial groups were based on the physical attributes of the photograph like similar aspect ratios or film stock. For example, there was a group of black/white 32mm square pictures that were taken around the time when my grandfather was in his mid 20s.
As I got done with grouping all of them, I was able to see flashes of stories in my head, but they were ephemeral and fragile. For instance, there was a group of photos that looked like it was taken during my grandparents' wedding but I didn't know the chronological order they were taken because EXIF metadata didn't exist around that time.
So I sat down with my grandmother and asked her to reorder the photos and tell me everything she could remember about her wedding. Her face lit up as she narrated the backstory behind the occasion, going from photo to photo, resurfacing details that had been dormant for decades. I wrote everything down, recorded the names of people in some of the photos, some of whom I recognized as younger versions of my uncles and aunts.
After the "interview", I had multiple pages of notes connecting the photos to events that happened 50 years ago. Since the account was historical, as an inside joke I wanted to see if I could clean it up and present it as a page on Wikipedia so I could print it and give it to her. So I cloned MediaWiki, spun up a local instance, and began my editorial work. I used the 2011 Royal Wedding as reference and drafted a page starting with the classic infobox and the lead paragraph.
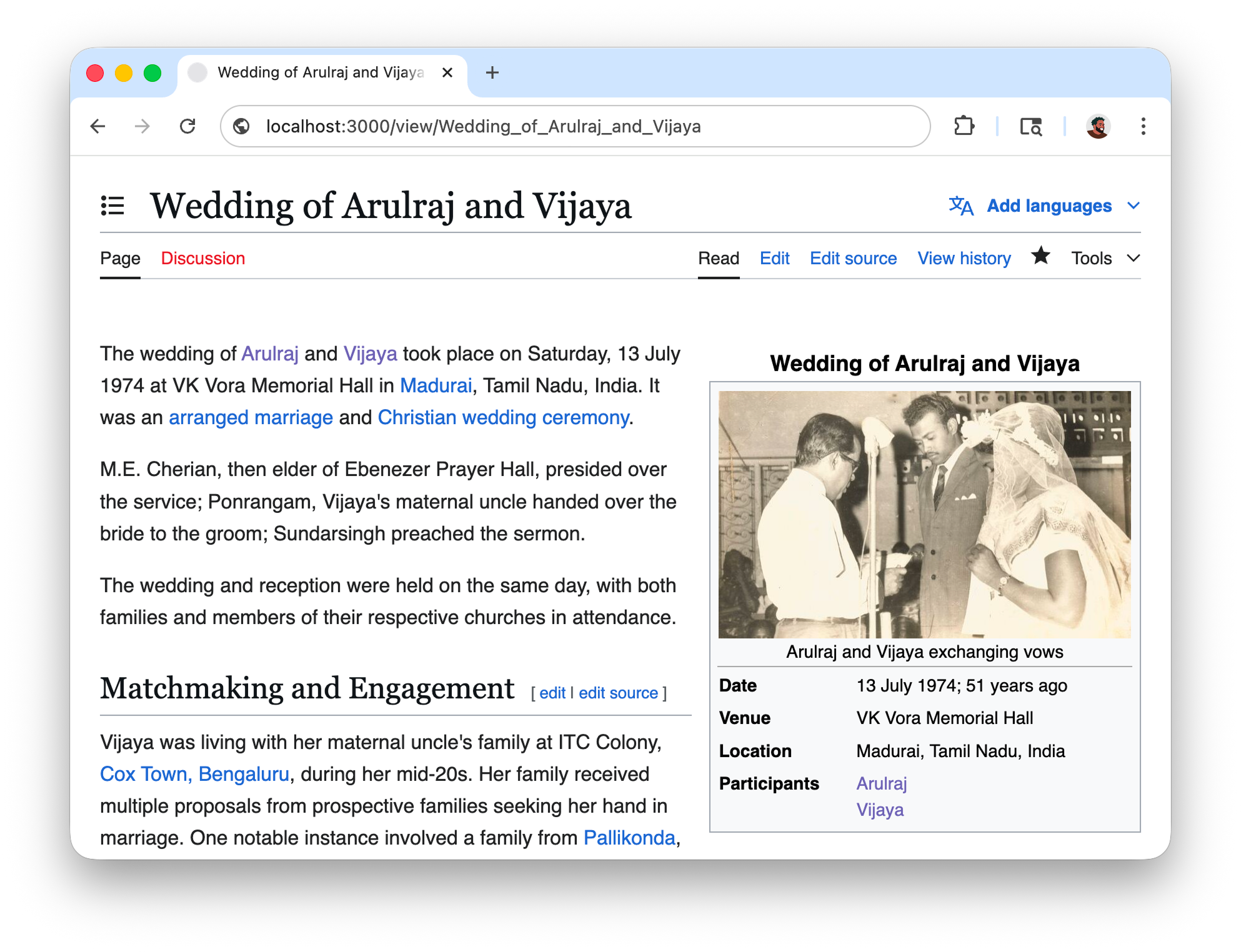
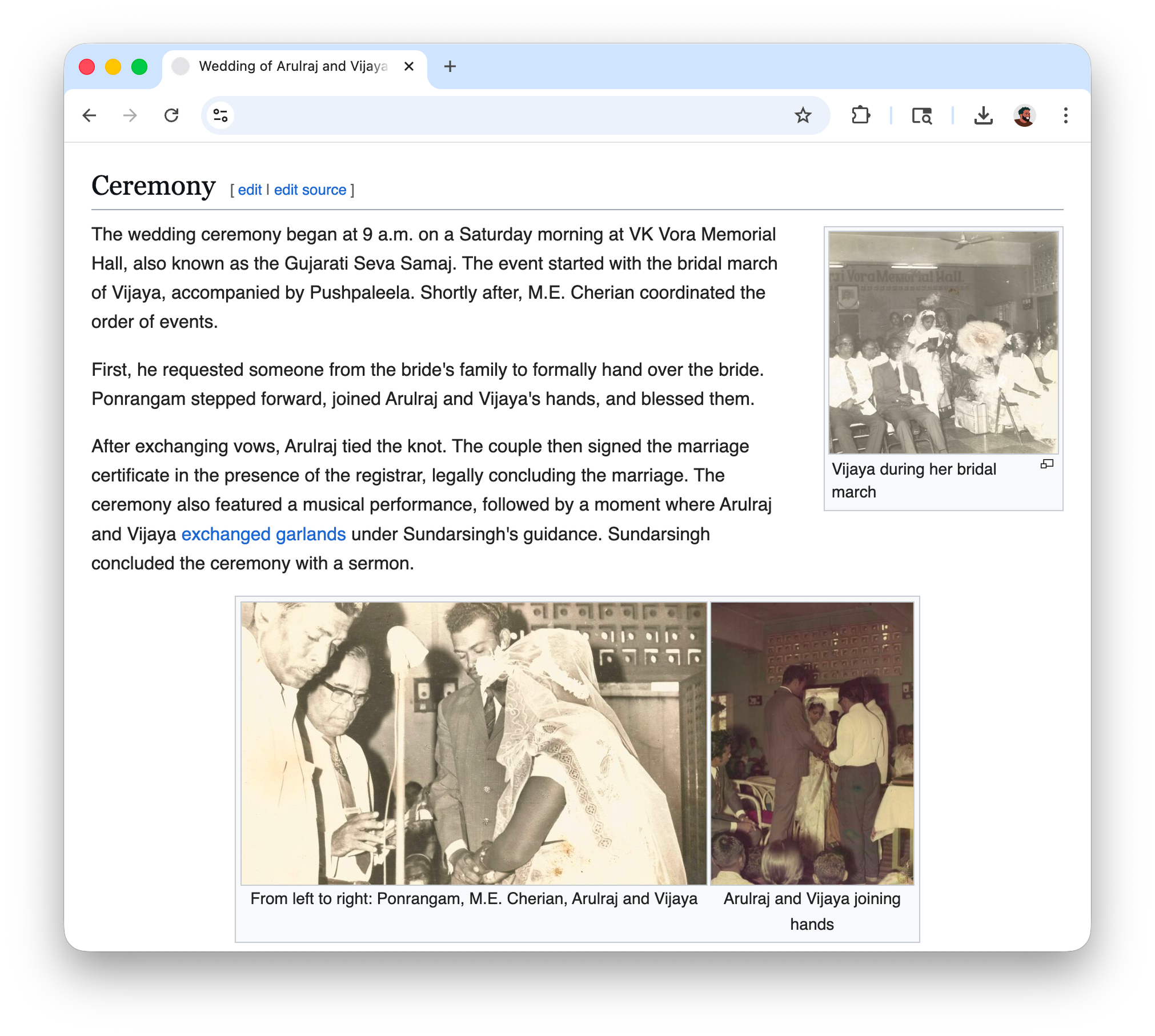
I split up the rest of the content into sections and filled them with everything I could verify like dates, names, places, who sat where. I scanned all the photos and spent some time figuring out what to place where. For every photo placement, there was a follow up to include a descriptive caption too.
Whenever I mentioned a person, I linked them to an empty stub page. After I found out I could also link to the real Wikipedia, I was able to link things to real pages that provided wider context to things like venues, rituals, and the political climate around that time, like for instance a legal amendment that was relevant to the wedding ceremony.
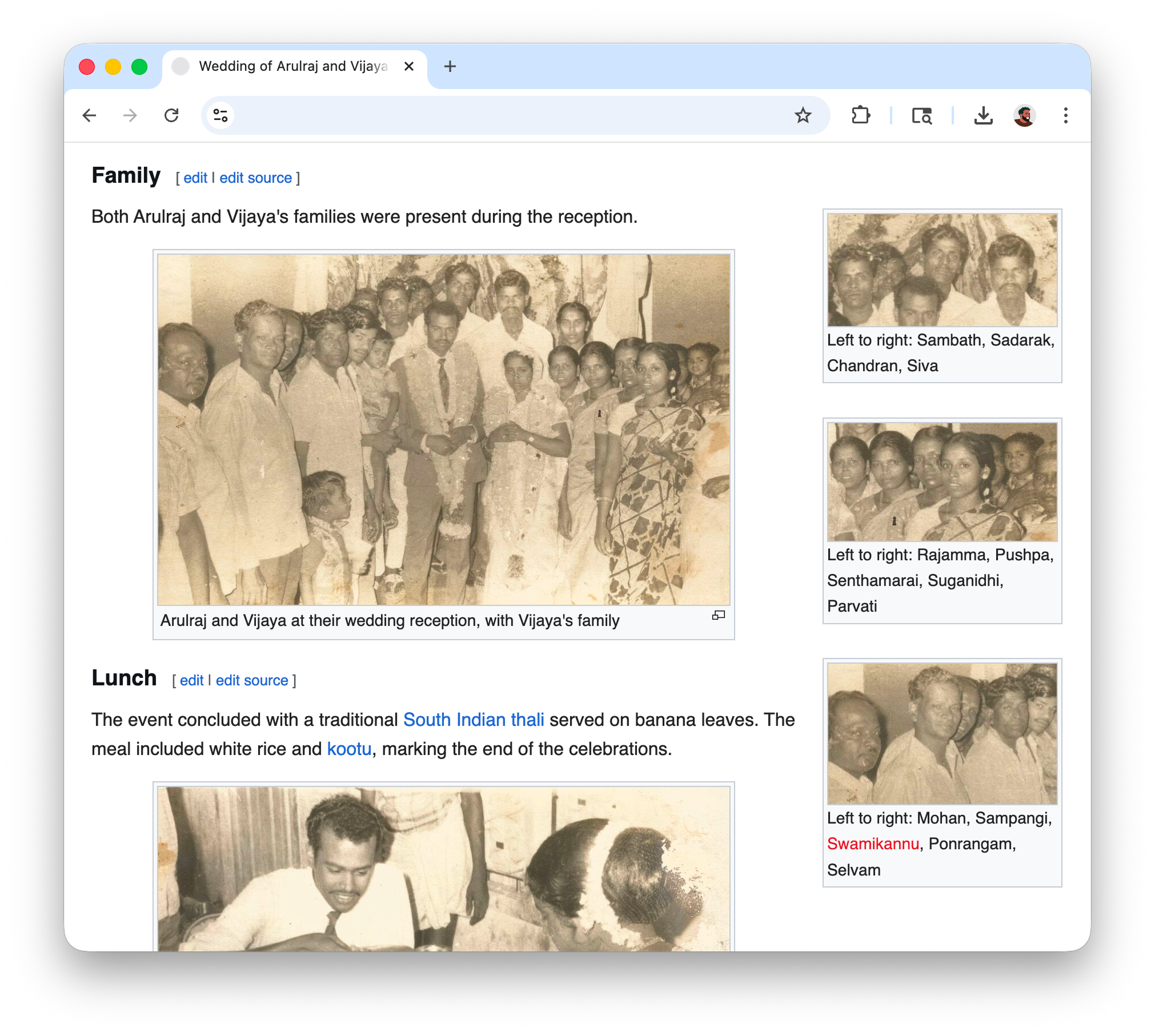
In two evenings, I was able to document a full backstory for the photos into a neat article. These two evenings also made me realize just how powerful encyclopedia software is to record and preserve media and knowledge that would've otherwise been lost over time.
This was so much fun that I spent the following months writing pages to account for all the photos that needed to be stitched together.
I got help from r/genealogy about how to approach recording oral history and I was given resources to better conduct interviews, shoutout to u/stemmatis! I would get on calls with my grandmother and people in the family, ask them a couple of questions, and then write. It was also around this time that I began using audio transcription and language models to make the editorial process easier.
Over time, I managed to write a lot of pages connecting people to different life events. The encyclopedia format made it easy to connect dots I would have never found on my own, like discovering that one of the singers at my grandparents' wedding was the same nurse who helped deliver me.
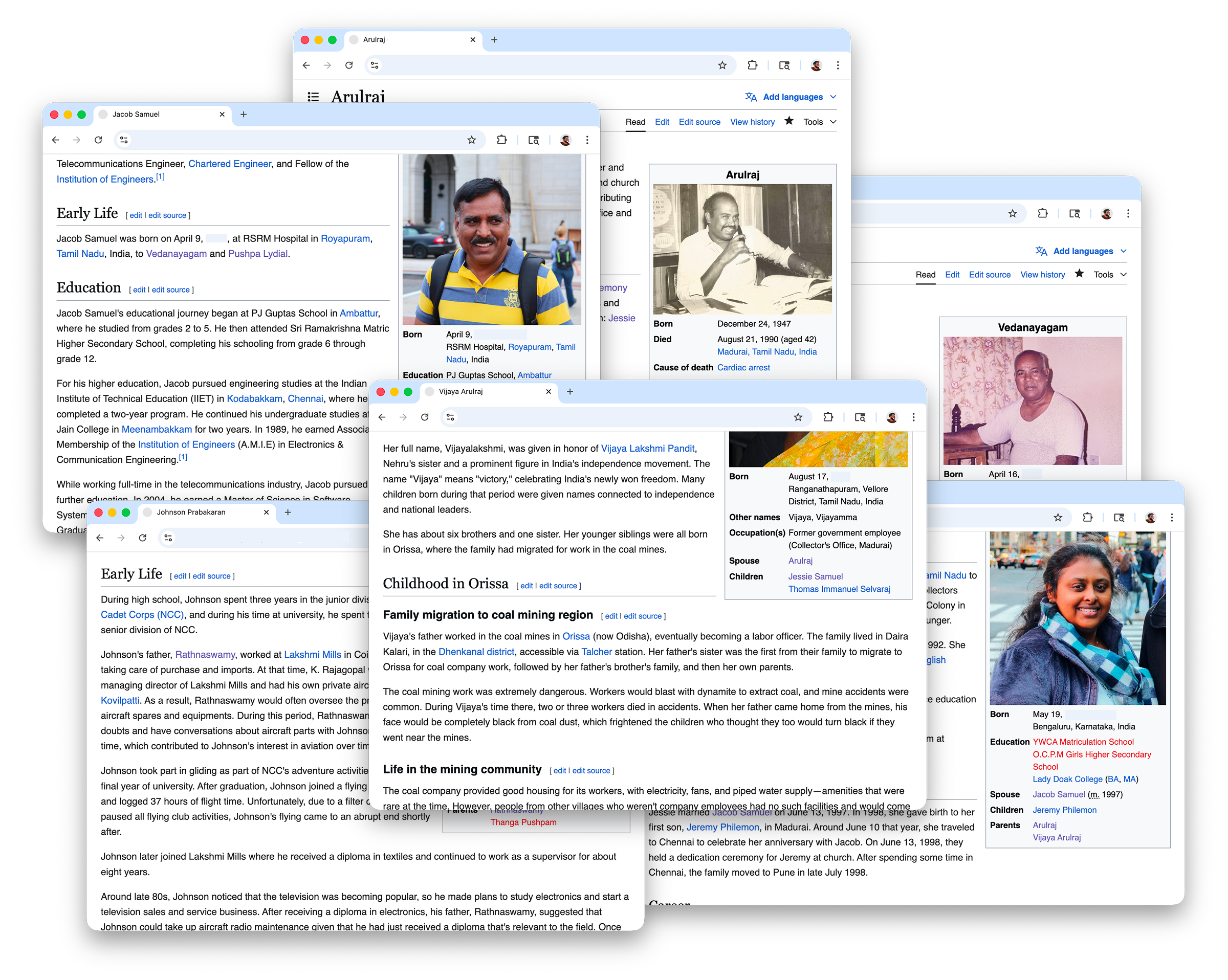
After finding all the stories behind the physical photos, I started to work on digital photos and videos that I had stored on Google Photos. The wonderful thing about digital photos is that they come with EXIF metadata that can reveal extra information like date, time, and sometimes geographical coordinates.
This time, without any interviews, I wanted to see if I could use a language model to create a page based on just browsing through the photos. As my first experiment, I created a folder with 625 photos of a family trip to Coorg back in 2012.
I pointed Claude Code at the directory and asked it to draft a wiki page by browsing through the images. I hinted at using ImageMagick to create contact sheets so it would help with browsing through multiple photos at once.
After a few minutes and a couple of tokens later, it had created a compelling draft with a detailed account of everything we did during the trip by time of day. The model had no location data to work with, just timestamps and visual content, but it was able to identify the places from the photos alone, including ones that I had forgotten by now. It picked up details on the modes of transportation we used to get between places just from what it could see.
After I had clarified who some of the people in the pictures were, it went on to identify them automatically in the captions. Now that I had a detailed outline ready, the page still only had content based on the available data, so to fill in the gaps I shared a list of anecdotes from my point of view and the model inserted them into places where the narrative called for them.
The Coorg trip only had photos to work with. My trip to Mexico City in 2022 had a lot more. I had taken 291 photos and 343 videos with an iPhone 12 Pro that included geographical coordinates as part of the EXIF metadata.
On top of that, I exported my location timeline from Google Maps, my Uber trips, my bank transactions, and Shazam history. I would ask Claude Code to start with the photos and then gradually give it access to the different data exports.
Here are some of the things it did across multiple runs:
- It cross-referenced my bank transactions with location data to ascertain the restaurants I went to.
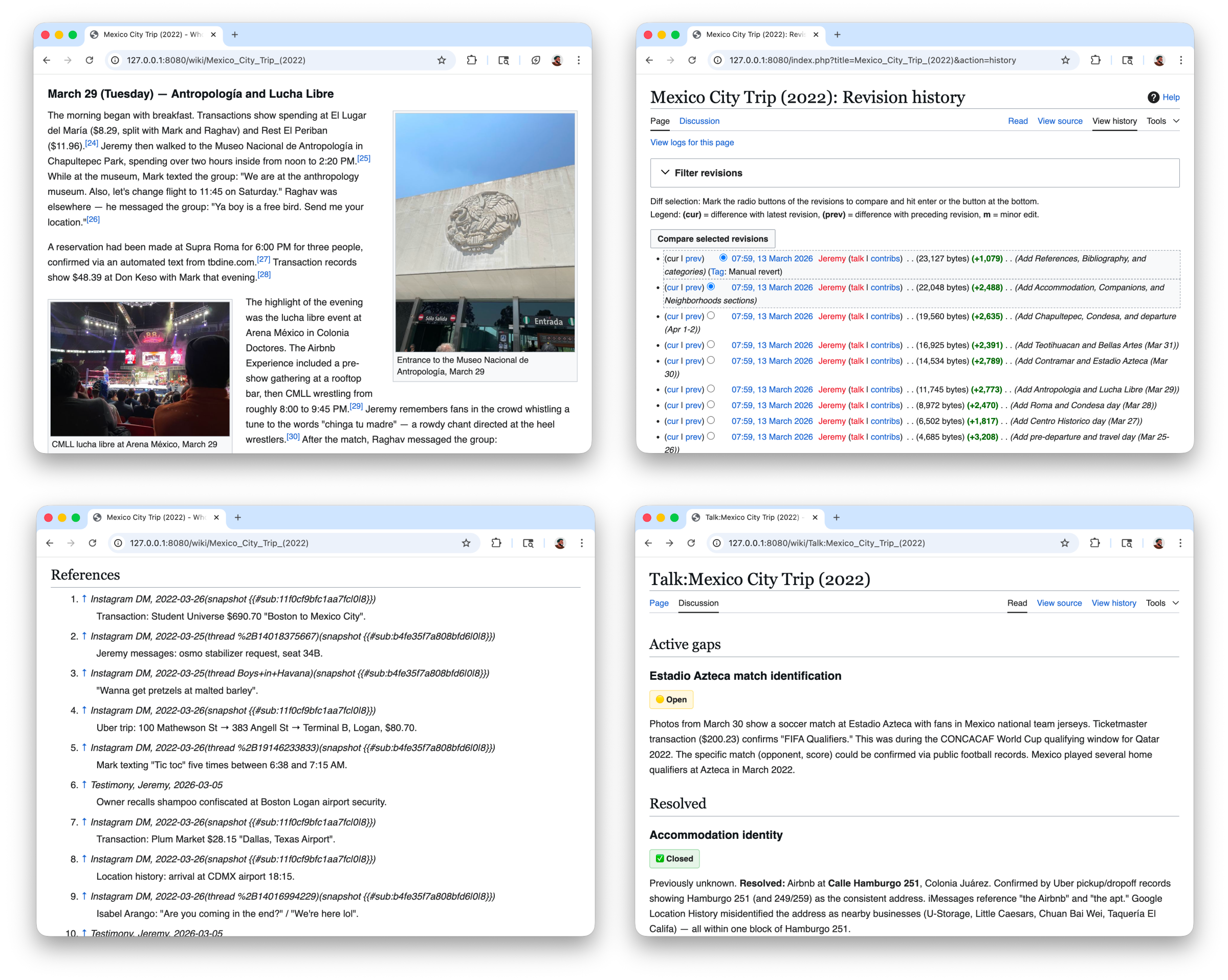
- Some of the photos and videos showed me in attendance at a soccer match, however, it was unknown which teams were playing. The model looked up my bank transactions and found a Ticketmaster invoice with information about the teams and name of the tournament.
- It looked up my Uber trips to figure out travel times and exact locations of pickup and drop.
- It used my Shazam tracks to write about the kinds of songs that were playing at a place, like Cuban songs at a Cuban restaurant.
- In a follow-up, I mentioned remembering an evening dinner with a guitarist playing in the background. It filtered my media to evening captures, found a frame in a video with the guitarist, uploaded it, and referenced the moment in the page.
The MediaWiki architecture worked well with the edits, since for every new data source it would make amendments like a real Wikipedia contributor would. I leaned heavily on features that already existed. Talk pages to clarify gaps and consolidate research notes, categories to group pages by theme, revision history to track how a page evolved as new data came in. I didn't have to build any of this, it was all just there.
What started as me helping the model fill in gaps from my memory gradually inverted. The model was now surfacing things I had completely forgotten, cross-referencing details across data sources in ways I never would have done manually.
So I started pointing Claude Code at other data exports. My Facebook, Instagram, and WhatsApp archives held around 100k messages and a couple thousand voice notes exchanged with close friends over a decade.
The model traced the arc of our friendships through the messages, pulled out the life episodes we had talked each other through, and wove them into multiple pages that read like it was written by someone who knew us both. When I shared the pages with my friends, they wanted to read every single one.
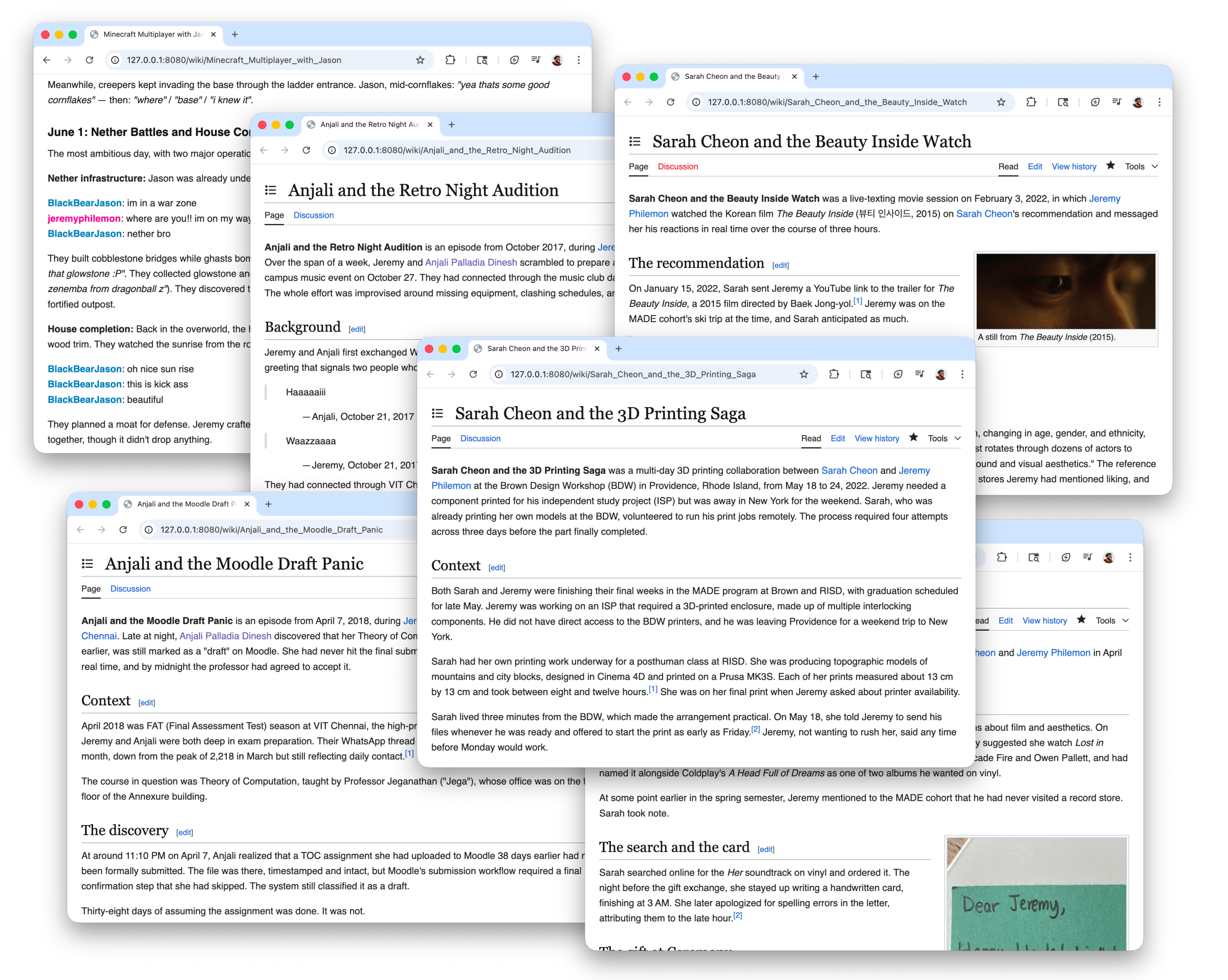
This is when I realized I was no longer working on a family history project. What I had been building, page by page, was a personal encyclopedia. A structured, browsable, interconnected account of my life compiled from the data I already had lying around.
I've been working on this as whoami.wiki. It uses MediaWiki as its foundation, which turns out to be a great fit because language models already understand Wikipedia conventions deeply from their training data. You bring your data exports, and agents draft the pages for you to review.
A page about your grandmother's wedding works the same way as a page about a royal wedding. A page about your best friend works the same way as a page about a public figure.
Oh and it's genuinely fun! Putting together the encyclopedia felt like the early days of Facebook timeline, browsing through finished pages, following links between people and events, and stumbling on a detail I forgot.
But more than the technology, it's the stories that stayed with me. Writing about my grandmother's life surfaced things I'd never known, her years as a single mother, the decisions she had to make, the resilience it took. She was a stronger woman than I ever realized. Going through my friendships, I found moments of endearment that I had nearly forgotten, the days friends went the extra mile to be good to me. Seeing those moments laid out on a page made me pick up the phone and call a few of them. The encyclopedia didn't just organize my data, it made me pay closer attention to the people in my life.
Today I'm releasing whoami.wiki as an open source project. The encyclopedia is yours, it runs on your machine, your data stays with you, and any model can read it. The project is early and I'm still figuring a lot of it out, but if this sounds interesting, you can get started here and tell me what you think!
Thanks to Vishnu Dut, Sarah Cheon, Andy Law, Vishhvak Srinivasan, and Raghav Rmadya, who read early drafts and gave great suggestions while I tinkered around.