It’s been a week since I published the original pgrust post. pgrust is my attempt to rewrite Postgres in Rust. My ultimate goal is to build a database that is safer to work with so that I can work on improving Postgres. pgrust now passes about two thirds of the queries in the Postgres regression suite, up from one third a week ago. The codebase is over 450k lines. I have 8 Codex accounts running in parallel at $200/month each, and 280 PRs have merged in the last two weeks. I expected progress to slow down by now. Instead the opposite has happened. I’m now moving an order of magnitude faster against the Postgres test suite than I was when working on the foundational work, even when weighting against token usage.
Building a Factory
The easiest way I can describe what the experience has been like is by comparing it to building a factory. If you’ve ever played the game Factorio, you know exactly what I’m talking about. My role in building pgrust has become less about hand writing code and more about designing a system that produces the output I want, then optimizing that system to move faster. Things will break all the time and it’s my job to fix the system so it doesn’t break again. A lot of my work has been dealing with bottlenecks in the factory and there’s been a number of really interesting ones I’ve dealt with.
For most of the last week, my laptop has been at 80–100% CPU. As it turns out, running multiple instances of the Rust compiler while running multiple instances of a database at the same time can consume a lot of CPU. Even with my beefy macbook pro with 14 CPUs, I’m still frequently maxing out the CPU. When you’re running 20 agents at one, it’s not hard to max out the CPU on your computer. I ended up spending a lot of time over the past week optimizing CPU usage.
I did some profiling into where the CPU was going during builds. From the profiling I did, compiling the parser made about half of the time it took to build pgrust. Moving the generated grammar code into its own compilation unit dropped the time it took to rebuild the rest of pgrust from about 60 seconds to 36 seconds. That sounds small, but it gets multiplied by every test every agent runs. After this change, I could run more agents at once.
One issue I was not expecting was running out of disk. Because I’m using git worktrees, each agent will get it’s own directory it works in. Initially that was resulting in every agent getting its own build artifacts as well. With each agent building pgrust multiple times over it’s lifecycle, I was ending up with over 100GB of build artifacts before I knew it. I now have a dedicated target directory for all my agents to share to ensure build artifacts are shared across agents.
The biggest win overall ended up being setting up a CI workflow. Previously to move quickly, I would have my agents make small changes, run a subset of the tests, and then merge their code into main. This meant the agents could move quickly, but also resulted in the build breaking all the time. Often at the end of the day, it would take a couple of hours of agents running in the background to merge all the code together and fix any merge conflicts and bugs that were introduced. I now have a GitHub merge queue set up that runs before code makes it into main. This allows my agents to still maintain a fairly high velocity, while also making sure the code that makes it into main passes all checks I have in place.
Switching between 8 codex accounts
I currently have 8 Codex accounts. Each one is a $200/month Codex subscription. At any given moment I’m running between 10 and 20 Codex sessions through Conductor. Each session has its own git worktree and is working on a different feature of pgrust. One may be working on jsonb, another on foreign keys, and so on and so on. As I’m getting further along with pgrust, I’m starting to point each agent at a specific test failure.
The reason I need 8 accounts is that each account has a 5-hour rate limit window and a separate weekly cap. When a single account hits its rate limit, every session running on that account stops. One account initially worked fine, but as I’ve started running more agents in parallel, I’ve needed to sign up for more Codex subscriptions to navigate around the rate limits.
As I was spinning up new accounts, it actually was a big pain to manage them all. As I would hit different rate limits, I would switch between my different accounts and see which one had any credits. I eventually started using a tool called codex-auth that shows me my remaining quota across all 8 accounts. This makes it easy to see how much usage I have left and easily find which account I should switch to.
GPT 5.5
GPT-5.5 came out last week. As soon as it came out, I was super excited to try it. I ended up having to do some hacks to get Conductor to support it before Conductor released official support for it. Off the bat, I tried using it the same way I’d been using 5.4. Many parallel agents, all in fast mode. I ended up hitting the rate limits incredibly fast. One time it took only 15 minutes to hit the 5 hour rate limit on one of the codex’s account. This was happening because 5.5 costs about 2x as much as 5.4 and ast mode adds another 2x multiplier on top in exchange for being about 50% faster.
I ended up backing off fast mode and running 5.5 at normal speed, with more agents in parallel. The big shift since the launch post is that my agents now spend more time waiting for builds and tests than waiting for inference. Since that’s true, the cost per token of being faster matters less than the ability to run more agents at once.
Progress is Accelerating
Going into this week, I expected progress to slow down. That’s how every project I’ve worked on has felt with the long tail of features eventually slowing down progress.
It was a pleasant surprise when I observed the opposite happening. Yesterday, I added around 90k new lines to pgrust. Now I know that lines of code is a terrible metric. But if you compare those lines of code to the progress I made on the Postgres test suite, those 90k lines of code improved the percentage of Postgres tests passing from 57% to around 67%. Given Postgres is 1M lines of code, adding 90k lines of code to get 10% of the Postgres tests to pass sounds pretty reasonable.
The more interesting data point is when you look at the amount of effort it takes to get an additional test to pass. Codex has pretty good telemetry on how many tokens you’ve been using. I’ve been able to compare my token usage against the number of regression tests I get passing and it’s been taking less tokens over time to get regression tests passing and not more.
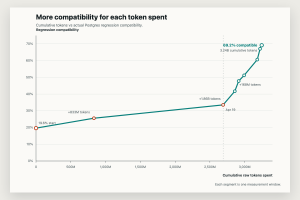
In my opinion, the reason this is happening is I’ve already laid the foundation for pgrust. Most of the core systems are now in place. The planner exists, the buffer cache exists, PL/pgSQL is there, JSONB mostly works, and so does a long list of other things that took the first week to build. The work that’s left is mostly small and very specific. Things like adding this specific JSONB function or change the way certain query plans get displayed. Agents handle that kind of work well. I can hand five specific functions to an agent and say “implement these,” walk away, and it does a reasonable job. The macro features were where I had to be most careful.
What I’d like to build next
This week, I want to get as close to 100% query-level compatibility as I can. There’s still a long tail of behavior to cover. At the current rate, there’s no specific reason it can’t happen this week.
Then, stability. Compatibility means “this query returns the right answer.” Production-readiness means “this query returns the right answer for the next 90 days under load.” Bug-bashing on real workloads is the next phase, and I want to do it on real workloads, not toy ones.
Then, the parts of Postgres I wish were different. The architectural opinions I had going into this project, like multi-threading, auto-tuning, and less stack-glue, are still where I think the value is. But I can’t get to those until pgrust looks and behaves like Postgres in every other way.
Want to help us test pgrust on real workloads?
The single most useful thing right now is finding people who run small Postgres workloads who would be open to running pgrust as a replica. Hobby projects, side projects, internal tools at work that nobody depends on. pgrust is a drop in replacement with Postgres, so the setup is just as easy as setting up Postgres. We are able to replicate off of an existing db so you can try out pgrust with minimal impact to your production workload. You don’t have to put pgrust anywhere near your write path.
To be clear, I’m not asking anyone to bet production on this. Synthetic test suites can pass while a database has subtle correctness or durability issues that only show up against real workloads. That’s the gap I’m trying to close, and the only way to close it is to run real workloads against it.
If you have such a workload, or if you have specific Postgres pain you’d like to see addressed first, I’d love to hear from you.
Updates and links
- The repo: https://github.com/malisper/pgrust
- Browser demo @ pgrust.com: now running the 67% build, with examples for window functions, JSONB, foreign keys, EXPLAIN ANALYZE, regex, and a recursive-CTE Lisp interpreter
- Discord: https://discord.gg/FZZ4dbdvwU
- Weekly updates by email: https://malisper.me/subscribe/
- Docker images are being refreshed on the same build
If you’ve made it this far, thanks for reading. The mailing list link above is the easiest way to keep up with where this goes next.