Last August, I delivered my traditional Go Cryptography State of the Union talk at GopherCon US 2025 in New York.
It goes into everything that happened at the intersection of Go and cryptography over the last year.
You can watch the video (with manually edited subtitles, for my fellow subtitles enjoyers) or read the transcript below (for my fellow videos not-enjoyers).
The annotated transcript below was made with Simon Willison’s tool. All pictures were taken around Rome, the Italian contryside, and the skies of the Northeastern United States.
Annotated transcript

{kind=link}
Welcome to my annual performance review.
We are going to talk about all of the stuff that we did in the Go cryptography world during the past year.

{kind=link}
When I say "we," it doesn't mean just me, it means me, Roland Shoemaker, Daniel McCarney, Nicola Morino, Damien Neil, and many, many others, both from the Go team and from the Go community that contribute to the cryptography libraries all the time.
I used to do this work at Google, and I now do it as an independent as part of and leading Geomys, but we'll talk about that later.

{kind=link}
When we talk about the Go cryptography standard libraries, we talk about all of those packages that you use to build secure applications.
That's what we make them for. We do it to provide you with encryption and hashes and protocols like TLS and SSH, to help you build secure applications.

{kind=link}
The main headlines of the past year:
We shipped post quantum key exchanges, which is something that you will not have to think about and will just be solved for you.
We have solved FIPS 140, which some of you will not care about at all and some of you will be very happy about.
And the thing I'm most proud of: we did all of this while keeping an excellent security track record, year after year.
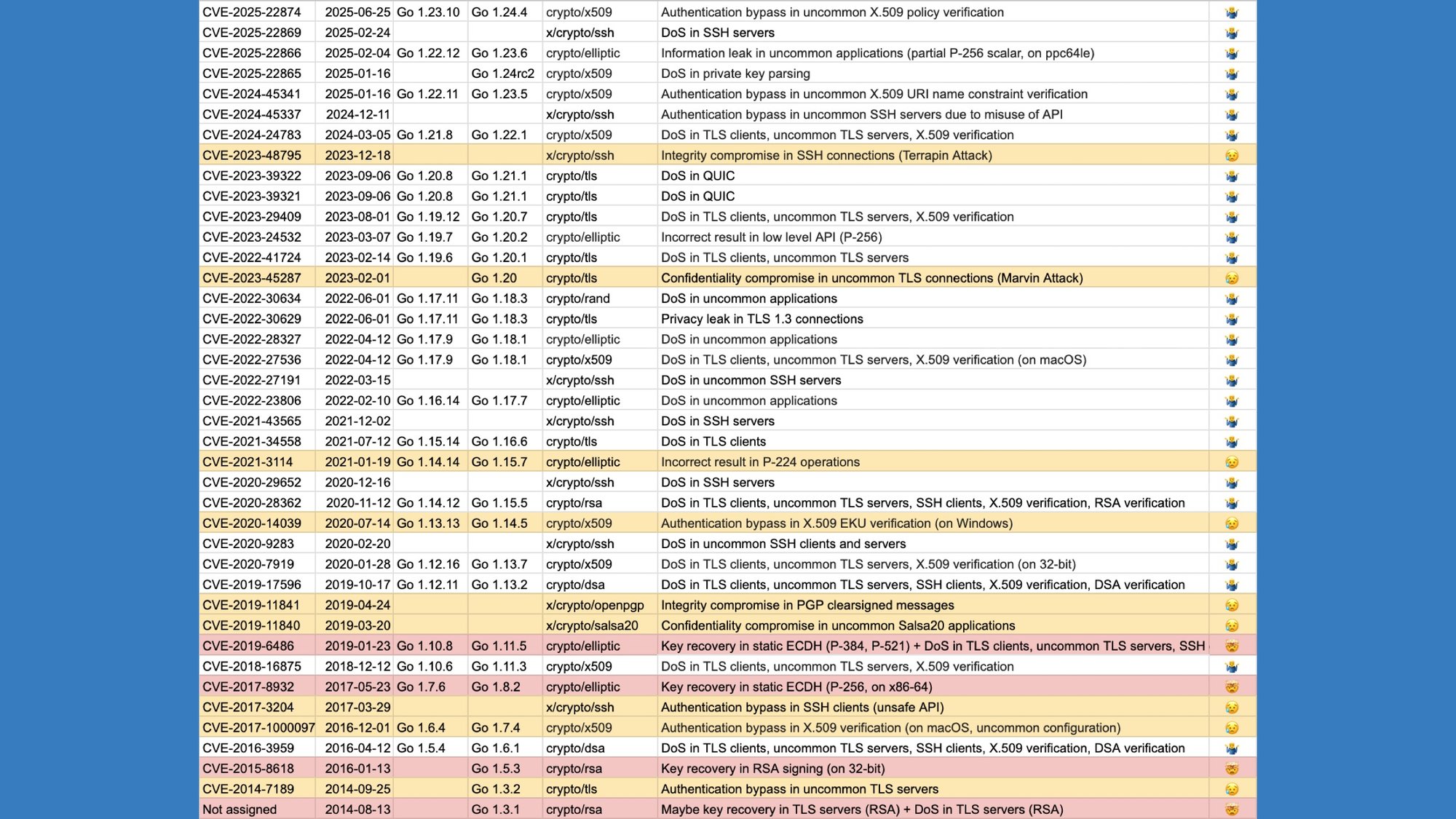
{kind=link}
This is an update to something you've seen last year.
It's the list of vulnerabilities in the Go cryptography packages.
We don't assign a severity—because it's really hard, instead they're graded on the "Filippo's unhappiness score."
It goes shrug, oof, and ouch.
Time goes from bottom to top, and you can see how as time goes by things have been getting better. People report more things, but they're generally more often shrugs than oofs and there haven't been ouches.
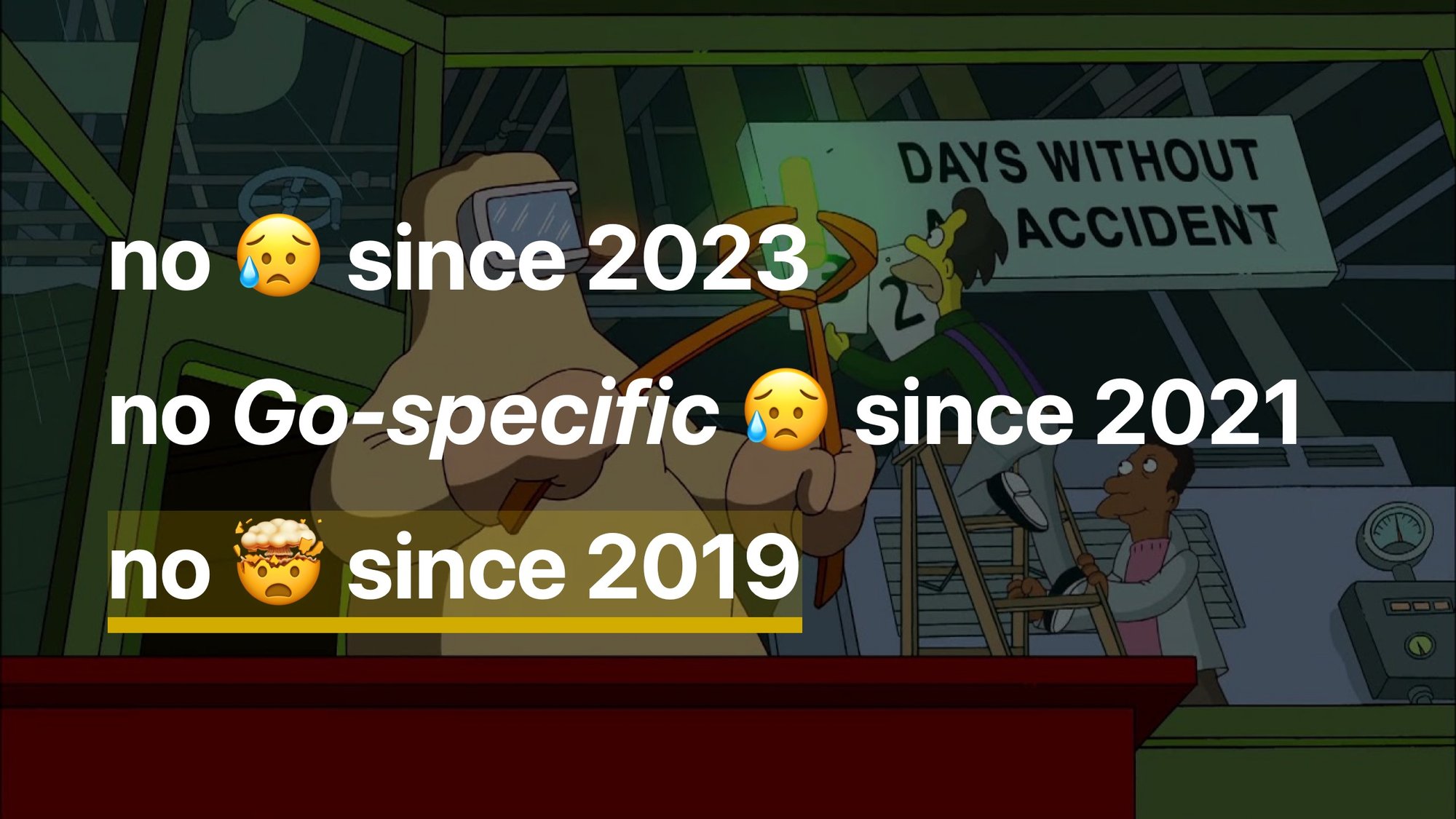
{kind=link}
More specifically, we haven't had any oof since 2023.
We didn't have any Go-specific oof since 2021.
When I say Go-specific, I mean: well, sometimes the protocol is broken, and as much as we want to also be ahead of that by limiting complexity, you know, sometimes there's nothing you can do about that.
And we haven't had ouches since 2019. I'm very happy about that.

{kind=link}
But if this sounds a little informal, I'm also happy to report that we had the first security audit by a professional firm.
Trail of Bits looked at all of the nuts and bolts of the Go cryptography standard library: primitives, ciphers, hashes, assembly implementations. They didn't look at the protocols, which is a lot more code on top of that, but they did look at all of the foundational stuff.
And I'm happy to say that they found nothing.

Two of a kind t-shirts, for me and Roland Shoemaker.

{kind=link}
It is easy though to maintain a good security track record if you never add anything, so let's talk about the code we did add instead.
First of all, post-quantum key exchanges.
We talked about post-quantum last year, but as a very quick refresher:
- Post-quantum cryptography is about the future. We are worried about quantum computers that might exist… 5-50 (it's a hell of a range) years from now, and that might break all of asymmetrical encryption. (Digital signatures and key exchanges.)
- Post-quantum cryptography runs on classical computers. It's cryptography that we can do now that resists future quantum computers.
- Post-quantum cryptography is fast, actually. If you were convinced that for some reason it was slow, that's a common misconception.
- However, post-quantum cryptography is large. Which means that we have to send a lot more bytes on the wire to get the same results.
Now, we focused on post-quantum key exchange because the key exchange defends against the most urgent risk, which is that somebody might be recording connections today, keeping them saved on some storage for the next 5-50 years and then use the future quantum computers to decrypt those sessions.
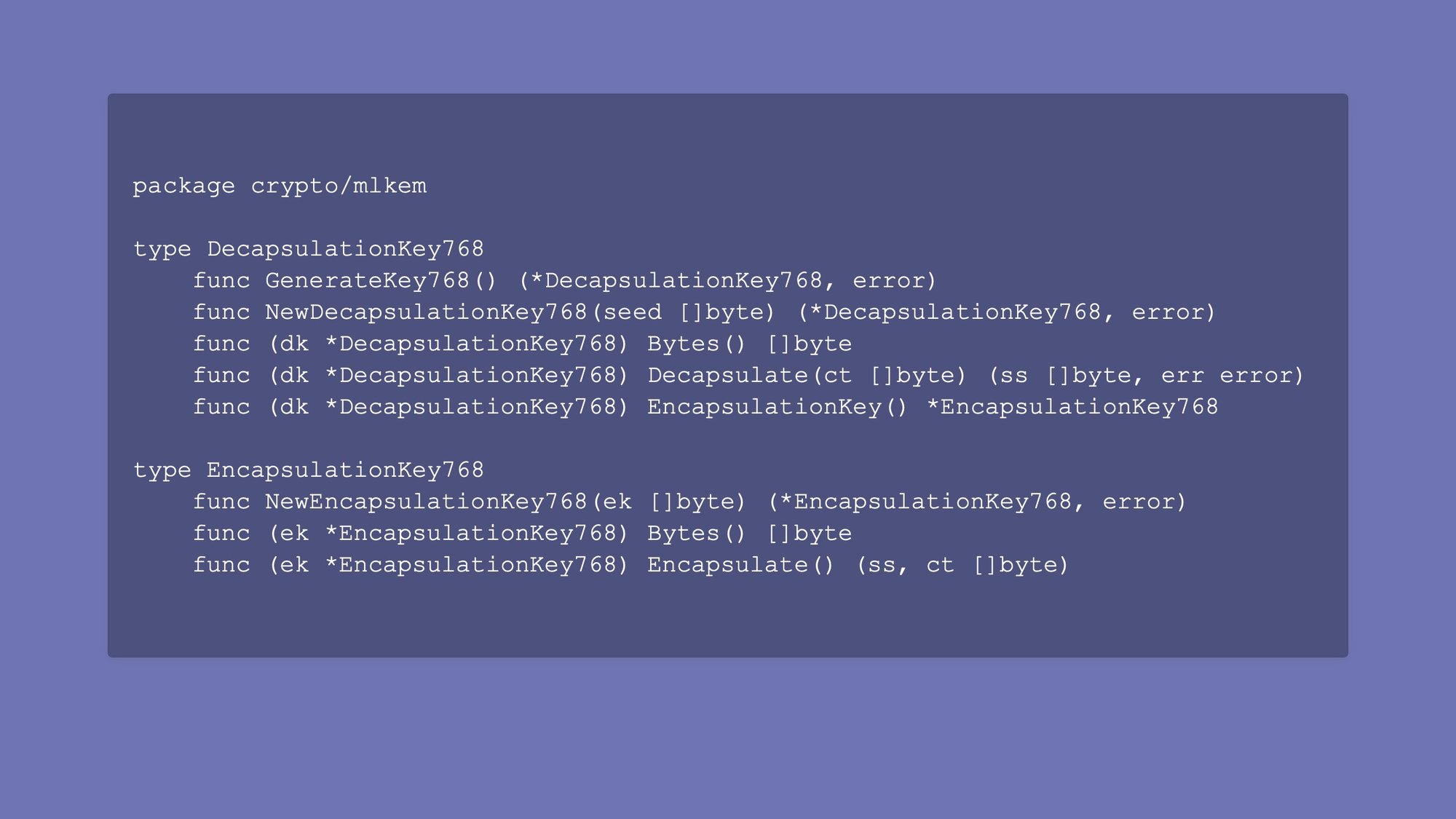
{kind=link}
I'm happy to report that we now have ML-KEM, which is the post-quantum key exchange algorithm selected by the NIST competition, an international competition run in the open.
You can use it directly from the crypto/mlkem standard library package starting in Go 1.24, but you're probably not gonna do that.

{kind=link}
Instead, you're probably going to just use crypto/tls, which by default now uses a hybrid of X25519 and ML-KEM-768 for all connections with other systems that support it.
Why hybrid? Because this is new cryptography. So we are still a little worried that somebody might break it.
There was one that looked very good and had very small ciphertext, and we were all like, “yes, yes, that's good, that's good.” And then somebody broke it on a laptop. It was very annoying.
We're fairly confident in lattices. We think this is the good one. But still, we are taking both the old stuff and the new stuff, hashing them together, and unless you have both a quantum computer to break the old stuff and a mathematician who broke the new stuff, you're not breaking the connection.
crypto/tls can now negotiate that with Chrome and can negotiate that with other Go 1.24+ applications.
Not only that, we also removed any choice you had in ordering of key exchanges because we think we know better than you and— that didn't come out right, uh.
… because we assume that you actually want us to make those kind of decisions, so as long as you don't turn it off, we will default to post-quantum.
You can still turn it off. But as long as you don't turn it off, we'll default to the post-quantum stuff to keep your connection safe from the future.


{kind=link}
Okay, but you said key exchanges and digital signatures are broken. What about the latter?
Well, key exchanges are urgent because of the record-now-decrypt-later problem, but unless the physicists that are developing quantum computers also develop a time machine, they can't use the QC to go back in time and use a fake signature today. So if you're verifying a signature today, I promise you it's not forged by a quantum computer.
We have a lot more time to figure out post-quantum digital signatures. But if we can, why should we not start now? Well, it's different. Key exchange, we knew what hit we had to take. You have to do a key exchange, you have to do it when you start the connection, and ML-KEM is the algorithm we have, so we're gonna use it.
Signatures, we developed a lot of protocols like TLS, SSH, back when it was a lot cheaper to put signatures on the wire. When you connect to a website right now, you get five signatures. We can't send you five 2KB blobs every time you connect to a website. So we are waiting to give time to protocols to evolve, to redesign things with the new trade-offs in mind of signatures not being cheap.
We are kind of slow rolling intentionally the digital signature side because it's both not as urgent and not as ready to deploy. We can't do the same “ta-da, it's solved for you” show because signatures are much harder to roll out.

{kind=link}
Let's talk about another thing that I had mentioned last year, which is FIPS 140.
FIPS 140 is a US government regulation for how to do cryptography. It is a list of algorithms, but it's not just a list of algorithms. It's also a list of rules that the modules have to follow.
What is a module?
Well, a module used to be a thing you would rack. All the rules are based on the idea that it's a thing you can rack. Then the auditor can ask “what is the module’s boundary?” And you're like, “this shiny metal box over here." And, you know, that works.
When people ask those questions of libraries, though, I do get a little mad every time. Like, what are the data input ports of your library? Ports. Okay.
Anyway, it's an interesting thing to work with.

{kind=link}
To comply with FIPS 140 in Go, up to now, you had to use an unsupported GOEXPERIMENT, which would replace all of the Go cryptography standard library, all of the stuff I'm excited about, with the BoringCrypto module, which is a FIPS 140 module developed by the BoringSSL folks. We love the BoringSSL folks, but that means using cgo, and we do not love cgo. It has memory safety issues, it makes cross-compilation difficult, it’s not very fast.
Moreover, the list of algorithms and platforms of BoringCrypto is tailored to the needs of BoringSSL and not to the needs of the Go community, and their development cycle doesn't match our development cycle: we don't decide when that module gets validated.
Speaking of memory safety, I lied a little. Trail of Bits did find one vulnerability. They found it in Go+BoringCrypto, which was yet another reason to try to push away from it.

{kind=link}
Instead, we've got now the FIPS 140-3 Go Cryptographic Module.
Not only is it native Go, it's actually just a different name for the internal Go packages that all the regular Go cryptography package use for the FIPS 140 algorithms. We just moved them into their own little bubble so that when they ask us “what is the module boundary” we can point at those packages.
Then there's a runtime mode which enables some of the self-tests and slow stuff that you need for compliance. It also tells crypto/tls not to negotiate stuff that's not FIPS, but aside from that, it doesn't change any observable behavior.
We managed to keep everything working exactly the same: you don't import a different package, you don't do anything different, your applications just keep working the same way. We're very happy about that.
Finally, you can at compile time select a GOFIPS140 frozen module, which is just a zip file of the source of the module as it was back when we submitted it for validation, which is a compliance requirement sometimes.
By the way, that means we have to be forward compatible with future versions of Go, even for internal packages, which was a little spicy.
You can read more in the upstream FIPS 140-3 docs.

{kind=link}
But that's not enough.
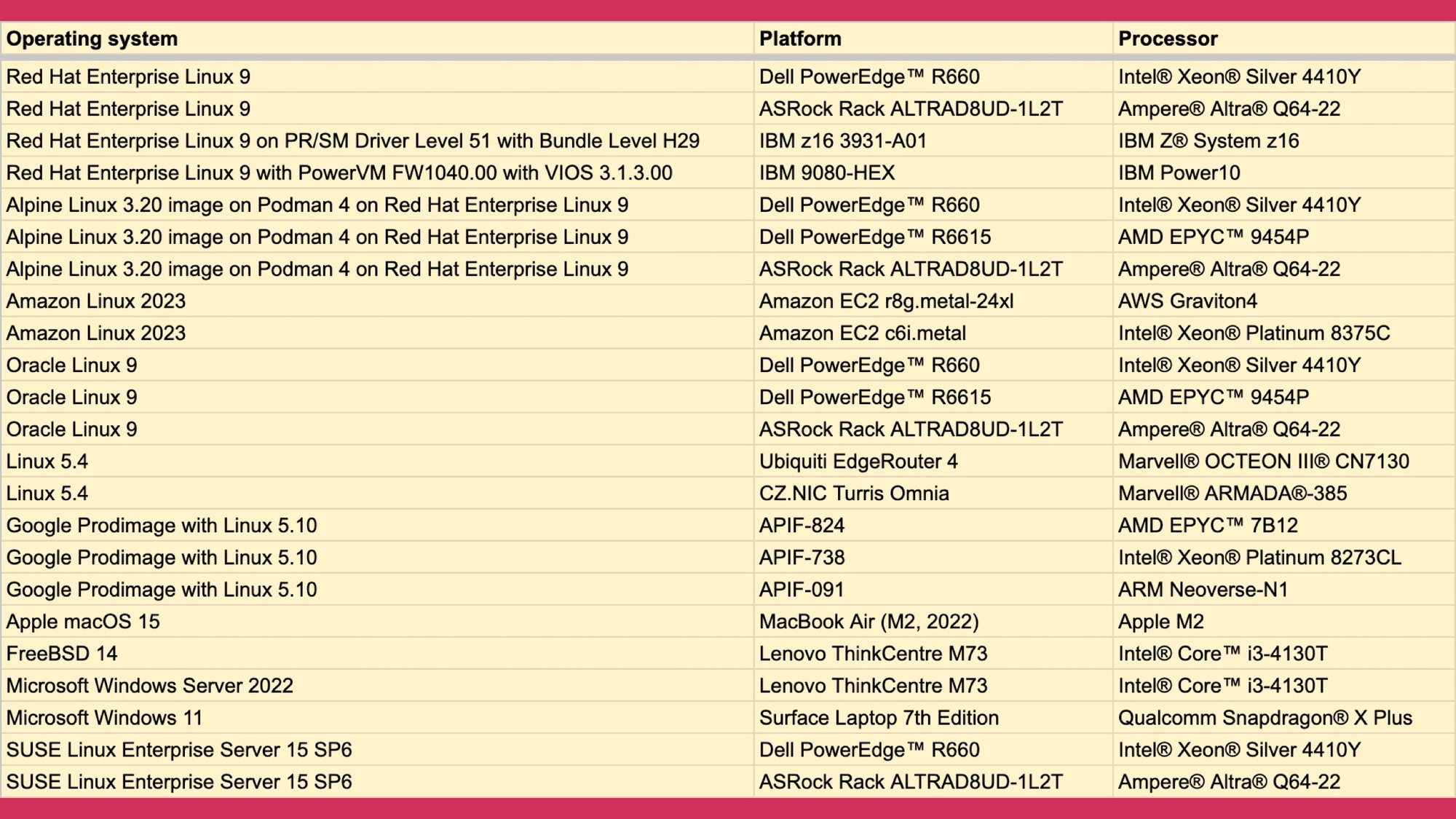
Even if you use a FIFS 140 algorithm from a FIPS 140 module that was tested for the algorithm it's still not enough because it has to run on a platform that was tested as part of the validation.
So we tested on a lot of platforms.
Some of them were paid for by various Fortune 100s that had an interest in them getting tested, but some of them had no sponsors.
We really wanted to solve this problem for everyone, once and for all, so Geomys just paid for all the FreeBSD, macOS, even Windows testing so that we could say “run it on whatever and it's probably going to be compliant.” (Don't quote me on that.)

{kind=link}
How did we test on that many machines? Well, you know, we have this sophisticated data center…
Um, no. No, no.
I got a bunch of stuff shipped to my place.
That's my NAS now. It's an Ampere Altra Q64-22, sixty-four arm64 cores, and yep, it's my NAS.

{kind=link}
Then I tested it on, you know, this sophisticated arm64 macOS testing platform.

{kind=link}
And then on the Windows one, which is my girlfriend's laptop.

{kind=link}
And then the arm one, which was my router.
Apparently I own an EdgeRouter now? It's sitting in the data center which is totally not my kitchen.

{kind=link}
It was all a very serious and regimented thing, and all of it is actually recorded, in recorded sessions with the accredited laboratories, so all this is now on file with the US government.

{kind=link}
You might or might not be surprised to hear that the easiest way to meet the FIPS 140 requirements is not to exceed them.
That's annoying and a problem of FIPS 140 in general: if you do what everybody else does, which is just clearing the bar, nobody will ask questions, so there’s a strong temptation to lower security in FIPS 140 mode.
We just refused to accept that. Instead, we figured out complex stratagems.
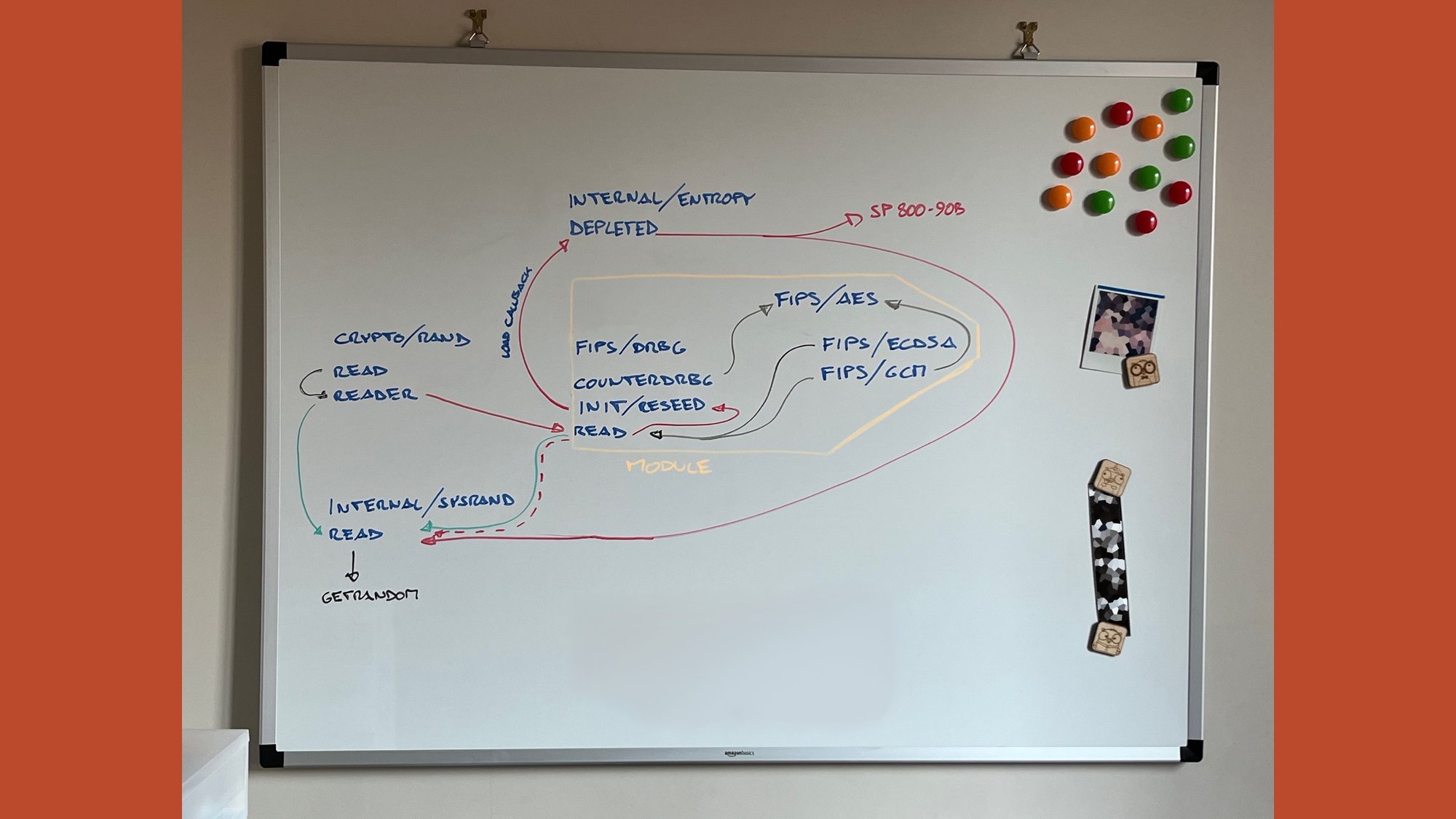
{kind=link}
For example, for randomness, the safest thing to do is to just take randomness from the kernel every time you need it. The kernel knows if a virtual machine was just cloned and we don't, so we risk generating the same random bytes twice.
But NIST will not allow that. You need to follow a bunch of standards for how the randomness is generated, and the kernel doesn’t.
So what we do is we do everything that NIST asks and then every time you ask for randomness, we squirrel off, go to the kernel, get a little piece of extra entropy, stir it into the pot before giving back the result, and give back the result.
It's still NIST compliant because it's as strong as both the NIST and the kernel solution, but it took some significant effort to show it is compliant.

{kind=link}
We did the same for ECDSA.
ECDSA is a digital signature mechanism. We've talked about it a few other times. It's just a way to take a message and a private key and generate a signature, here (s, r).
To make a signature, you also need a random number, and that number must be used only once with the same private key. You cannot reuse it. That number is k here.
Why can you not reuse it? Because if you reuse it, then you can do this fun algebra thing and then pop the private key falls out by just smashing two signatures together. Bad, really, really bad.

{kind=link}
How do we generate this number that must never be the same?
Well, one option is we make it random.
But what if your random number generator breaks and generates twice the same random number? That would leak the private key, and that would be bad.
So the community came up with deterministic ECDSA. Instead of generating the nonce at random, we are going to hash the message and the private key.
This is still actually a little risky though, because if there's a fault in the CPU, for example, or a bug, because for example you're taking the wrong inputs, you might still end up generating the same value but signing a slightly different message.
How do we mitigate both of those? We do both.
We take some randomness and the private key and the message, we hash them all together, and now it's really, really hard for the number to come out the same. That's called hedged ECDSA.
The Go crypto library has been doing hedged ECDSA from way before it was called hedged and way before I was on the team.
Except… random ECDSA has always been FIPS. Deterministic ECDSA has been FIPS since a couple years ago. Hedged ECDSA is technically not FIPS.


{kind=link}
We basically just figured out a way to claim it was fine and the lab eventually said "okay, shut up." I'm very proud of that one.
If you want to read more about this, check out the announcement blog post.
If you know you need commercial services for FIPS 140, here’s Geomys FIPS 140 commercial services page. If you don't know if you need them, you actually probably don't. It's fine, the standard library will probably solve this for you now.

{kind=link}
Okay, but who cares about this FIPS 140 stuff?
"Dude, we've been talking about FIPS 140 for 10 minutes and I don't care about that."
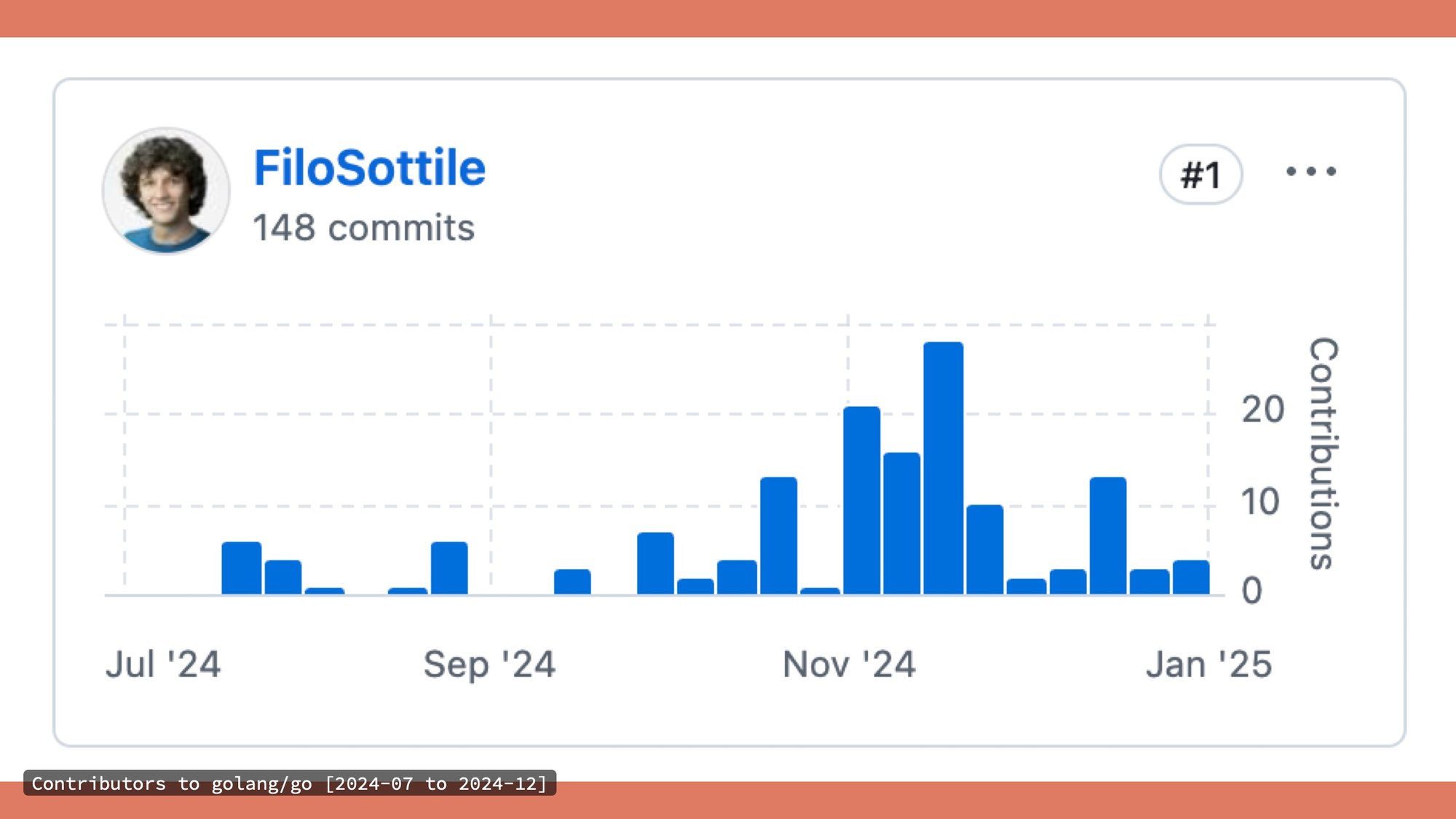
{kind=link}
Well, I care because I spent my last year on it and that apparently made me the top committer for the cycle to the Go repo and that's mostly FIPS 140 stuff.
I don't know how to feel about that.

{kind=link}
There have been actually a lot of positive side effects from the FIPS 140 effort. We took care to make sure that everything that we found we would leave in a better state.

{kind=link}
For example, there are new packages that moved from x/crypto into the standard library: crypto/hkdf, crypto/pbkdf, crypto/sha3.
SHA-3 is faster and doesn't allocate anymore.
HKDF has a new generic API which lets you pass in a function that returns either a concrete type that implements Hash or a function that returns a Hash interface, which otherwise was a little annoying. (You had to make a little closure.) I like it.

{kind=link}
We restructured crypto/aes and crypto/cipher and in the process merged a contribution from a community member that made AES-CTR, the counter mode, between 2 and 9 times faster. That was a pretty good result.
The assembly interfaces are much more consistent now.

{kind=link}
Finally, we finished cleaning up crypto/rsa.
If you remember from last year, we made the crypto/rsa sign and verify operations not use math/big and use constant time code. Now we also made key generation, validation, and pre-computation all not use math/big.
That loading keys that were serialized to JSON a lot faster, and made key generation much faster. But how much faster?
Benchmarking key generation is really hard because it's a random process: you take a number random number and you check, is it prime? No. Toss. Is it prime? Nope. Toss. Is it prime?
You keep doing this. If you're lucky, it’s very fast. If you are unlucky, very slow. It’s a geometric distribution and if you want to average it out, you have to run for hours. Instead, I figured out a new way by mathematically deriving the average number of pulls you are supposed to do and preparing a synthetic run that gives exactly the expected mean number of checks, so that we get a representative sample to benchmark deterministically. That was a lot of fun.
Moreover, we detect more broken keys, and we did a rare backwards compatibility break to stop supporting keys smaller than 1024 bits.
1024 is already pretty small, you should be using 2048 minimum, but if you're using less than 1024, it can be broken on the proverbial laptop. It's kind of silly that a production library lets you do something so insecure, and you can't tell them apart just by looking at the code. You have to know what the size of the key is.
So we just took that out.
I expected people to yell at me. Nobody yelled at me. Good job community.

{kind=link}
Aside from adding stuff, you know that we are very into testing and that testing is how we keep that security track record that we talked about.
I have one bug in particular that is my white whale.
(You might say, "Filippo, well-adjusted people don't have white whales." Well, we learned nothing new, have we?)
My white whale is this assembly bug that we found at Cloudflare before I joined the Go team. I spent an afternoon figuring out an exploit for it with Sean Devlin in Paris, while the yellow jackets set fire to cop cars outside. That's a different story.
It's an assembly bug where the carry—literally the carry like when you do a pen and paper multiplication—was just not accounted for correctly. You can watch my talk Squeezing a Key through a Carry Bit if you are curious to learn more about it.

{kind=link}
The problem with this stuff is that it's so hard to get code coverage for it because all the code always runs. It's just that you don't know if it always runs with that carry at zero, and if the carry was one, it’d do the wrong math.
I think we've cracked it, by using mutation testing.
We have a framework that tells the assembler, "hey, anywhere you see an add-with-carry, replace it with a simple add that discards the carry." Then we run the tests. If the tests still pass, the test did not cover that carry.
If that happens we fail a meta-test and tell whoever's sending the CL, “hey, no, no, no, you gotta test that.”
Same for checking the case in which the carry is always set. We replace the add-with-carry with a simple add and then insert a +1.
It's a little tricky. If you want to read more about it, it's in this blog post. I'm very hopeful that will help us with all this assembly stuff.

{kind=link}
Next, accumulated test vectors.
This is a little trick that I'm very very fond of.
Say you want to test a very large space. For example there are two inputs and they can both be 0 to 200 bytes long, and you want to test all the size combinations.
That would be a lot of test vectors, right?
If I checked in a megabyte of test vectors every time I wanted to do that, people eventually would yell at me.
Instead what we do is run the algorithm with each size combination, and take the result and we put it inside a rolling hash. Then at the end we take the hash result and we check that it comes out right.
We do this with two implementations. If it comes out to the same hash, great. If it comes out not to the same hash, it doesn't help you figure out what the bug is, but it tells you there's a bug. I'll take it.

{kind=link}
We really like reusing other people's tests. We're lazy.
The BoringSSL people have a fantastic suite of tests for TLS called BoGo and Daniel has been doing fantastic work integrating that and making crypto/tls stricter and stricter in the process.
It's now much more spec compliant on the little things where it goes like, “no, no, no, you're not allowed to put a zero here” and so on.
Then, the Let's Encrypt people have a test tool for the ACME protocol called Pebble. (Because it's a small version of their production system called Boulder! It took me a long time to figure it out and eventually I was like ooooohhh.)
Finally, NIST has this X.509 interoperability test suite, which just doesn't have a good name. It's good though.

{kind=link}
More assembly cleanups.
There used to be places in assembly where—as if assembly was not complicated enough—instructions were just written down as raw machine code.
Sometimes even the comment was wrong! Can you tell the comment changed in that patch? This is a thing Roland and Joel found.
Now there's a test that will just yell at you if you try to commit a WORD or BYTE instruction.
We also removed all the assembly that was specifically there for speeding up stuff on CPUs that don't have AVX2. AVX2 came out in 2015 and if you want to go fast, you're probably not using the CPU generation from back then. We still run on it, just not as fast.

{kind=link}
More landings! I’m going to speed through these ones.
This is all stuff that we talked about last year and that we actually landed.
Stuff like data independent timing to tell the CPU, "no, no, I actually did mean for you to do that in constant time, goddammit."
And server-side TLS Encrypted Client Hello, which is a privacy improvement. We had client side, now we have server side.
crypto/rand.Read never fails. We promised that, we did that.
Now, do you know how hard it is to test the failure case of something that never fails? I had to re-implement the seccomp library to tell the kernel to break the getrandom syscall to check what happens when it doesn’t work. There are tests all pointing guns at each other to make sure the fallback both works and is never hit unexpectedly.
It's also much faster now because Jason Donenfeld added the Linux getrandom VDSO.
Sean Liao added rand.Text like we promised.

{kind=link}
Then more stuff like hash.Cloner, which I think makes a lot of things a little easier, and more and more and more and more. The Go 1.24 and Go 1.25 release notes are there for you.

{kind=link}
x/crypto/ssh is also under our maintenance and some excellent stuff happened there, too.
Better tests, better error messages, better compatibility, and we're working on some v2 APIs. If you have opinions, it’s time to come to those issues to talk about them!

{kind=link}
It’s been an exciting year, and I'm going to give you just two samples of things we're planning to do for the next year.

{kind=link}
One is TLS profiles.
Approximately no one wants to specifically configure the fifteen different knobs of a TLS library.
Approximately no one—because I know there are some people who do and they yell at me regularly.
But instead most people just want "hey, make it broadly compatible." "Hey, make it FIPS compliant." "Hey, make it modern."
We're looking for a way to make it easy to just say what your goal is, and then we do all the configuration for you in a way that makes sense and that evolves with time.
I'm excited about this one.

{kind=link}
And maybe something with passkeys? If you run websites that authenticate users a bunch with password hashes and maybe also with WebAuthN, find me, email us, we want feedback.
We want to figure out what to build here, into the standard library.


{kind=link}
The best FIPS 140 side effect has been that we have a new maintainer.
Daniel McCarney joined us to help with the FIPS effort and then we were working very well together so Geomys decided to just take him on as a permanent maintainer on the Go crypto maintenance team. I’m very excited about that.


My work is made possible by Geomys, an organization of professional Go maintainers, which is funded by Smallstep, Ava Labs, Teleport, Tailscale, and Sentry. Through our retainer contracts they ensure the sustainability and reliability of our open source maintenance work and get a direct line to my expertise and that of the other Geomys maintainers. (Learn more in the Geomys announcement.) Here are a few words from some of them!
Teleport — For the past five years, attacks and compromises have been shifting from traditional malware and security breaches to identifying and compromising valid user accounts and credentials with social engineering, credential theft, or phishing. Teleport Identity is designed to eliminate weak access patterns through access monitoring, minimize attack surface with access requests, and purge unused permissions via mandatory access reviews.
Ava Labs — We at Ava Labs, maintainer of AvalancheGo (the most widely used client for interacting with the Avalanche Network), believe the sustainable maintenance and development of open source cryptographic protocols is critical to the broad adoption of blockchain technology. We are proud to support this necessary and impactful work through our ongoing sponsorship of Filippo and his team.