Growing up in the 90s I would go to the library and find books on computers. Most of these books were already out of date, containing printed Apple BASIC programs that you could try to copy in and get to work. My favorite one was an F-14 Tomcat simulator. I never got this to work. At the time my eight year old brain didn’t conceive that Applesoft BASIC was really just a different language from QBasic which I had on the 386 machine my father built and let me use. QBasic shipped with Gorillas, a Scorched Earth clone where the tanks are gorillas that throw bananas at each other. I have some plan to code by hand a Scorched Earth clone in Rust. If you haven’t heard back from me about this in a couple months feel free to send me a DM on Linkedin reminding me that you feel left out of the Scorched Earth Rust community that I have yet to build.

When reading all these old books and magazines from the public library you would hear about something called Zork. Zork was the original text adventure game created in the 1970s at MIT by Tim Anderson, Marc Blank, Bruce Daniels, and Dave Lebling for the PDP-10 mainframe computer. It is a game that is played almost entirely through text and imagination. It is a wonderful game where you traverse a labyrinthine underground in search of treasure. Many of the puzzles are not obvious, but this game has been part of computer culture since computers became a thing. There were many sequels, some with full motion video and graphics!, and the game itself created an entire genre of games called “text adventures” that influenced a lot of modern games and genres such as multi-user dungeons and rogue-like games.
I attended a Recurse Center batch recently. Recurse Center is a programming retreat where technically minded people congregate to build cool stuff. I think I better summed it up on LinkedIn where I said that it is basically Hackers, the movie, but in real life:
But at Recurse I met Mike Cugini who came in wanting to build a Rust implementation (see everyone likes Rust) for the Z-machine emulator. The Z-machine is the original game engine that was built by Infocom, the video game company formed out of the creation of Zork the game, to build more text adventure games. This created a big interest in Zork across the Recurse batch and immediately we had a cohort of people like Fiona Chow and Kevan Hollbach who were interested in playing Zork regularly, understanding what Zork was as a game, and also building tools around Zork. You can see below Fiona debugging an Apple //e that is part of the Recurse Center’s historical computer library (they also have a NeXt computer omg).

The first thing this led to was the creation of zulip-zork, a zulip bot (zulip is a group chat program like slack or discord) that allows anyone within a zulip channel to play zork. Actually, I built this on the airplane traveling back from New York City to The Netherlands where I currently live. Missing my Zork friends at Recurse, I thought to myself, what is a Zork project I could do? Initially, I thought, well lets get LLMs to play Zork. But I decided that was too difficult at the moment, so then I decided what would be better than to continue playing Zork online? So, thank god the plane had free WiFi, I was able to hack together a zulip-zork bot built on top of Bot-Builder and docker-zork.
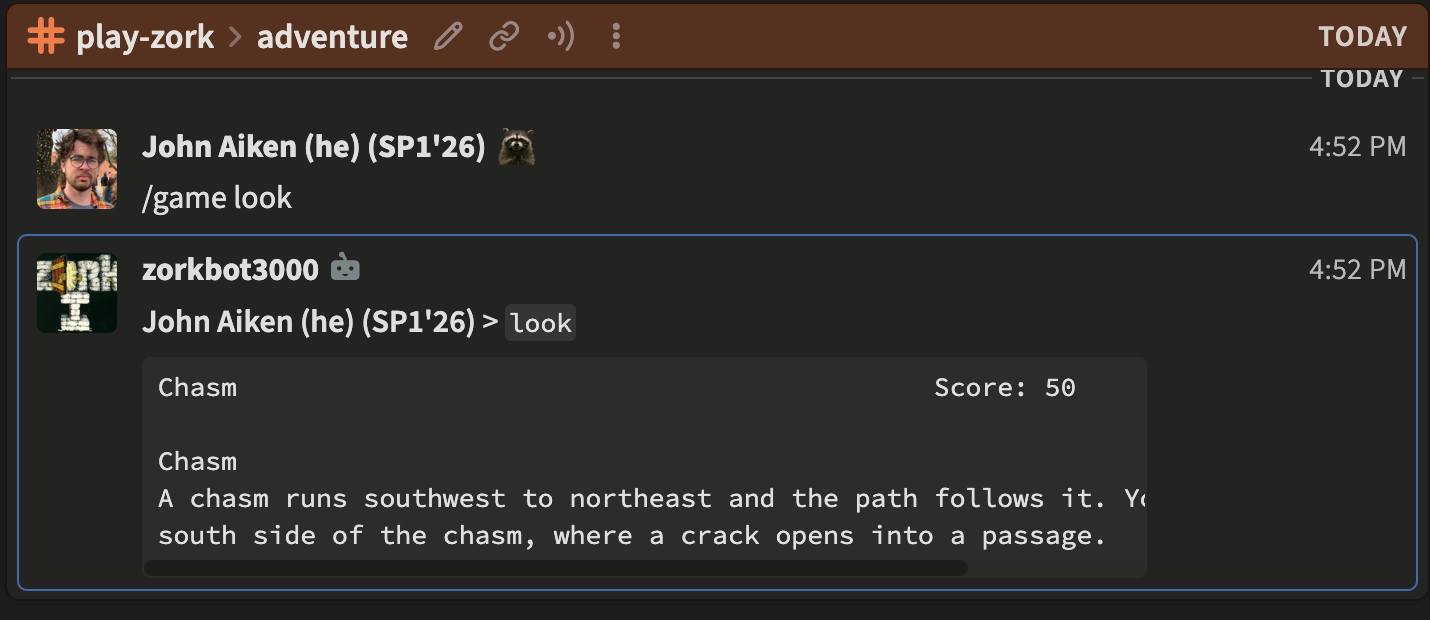
Essentially, dfrotz, a Z-machine emulator, runs in the docker container serving up Zork (it also supports other Infocom games), this in turn is connected to the bot which allows it to connect to a zulip channel, and you play by typing /game <commands> as you can see me doing above. This all runs on a VPS that I pay like 8$/month for that hosts random projects like this for me. This all worked quite well and so me and C Stravidis spent many many hours playing on Zulip together. There is a plan to replace the dfrotz emulator with Mike’s Rust implementation in the docker container.
But this question of LLMs playing Zork sat in the back of my mind still irritating me. Then one night, late at the Recurse Hub deep in conversation with Walter Min, Walter looked at me and just said, “zork-bench.” And I was inspired. That night I got home at maybe 3am and then woke up early, and got to work. By that evening I had a preliminary MVP for zork-bench to show at the weekly Recurse Center technical talks. In the talk I presented the LLM (anthropic opus 4.6, that was a quick way to spend 20$ in front of a bunch of people!) traversing the map of Zork and interacting with the game. And from that zork-bench has developed into a larger project attempting to assess the reasoning and problem solving abilities of LLMs.
The goal of Zork is to go into the dungeon and solve puzzles to find treasures. Treasures can then be deposited in the treasure case. And you get points both for finding treasures and putting them in the case. You also get points for going to hard to reach locations and solving puzzles. You need to be able to manage your inventory to do this (you can’t carry everything at once because it would be too heavy), there are puzzles to solve like figuring out the loud room or how to turn yourself back into a human if you become a ghost, an underground maze, and other things that present real problem solving challenges for a person or an LLM trying to play this game. And it seems like LLMs actually suck at this. Below you can see a plot from the paper, Playing With AI: How Do State-Of-The-Art Large Language Models Perform in the 1977 Text-Based Adventure Game Zork?, which shows that modern LLMs barely get any points at all, with an average across all of them sitting around 50 points out of 350. And they take quite a lot of moves to do nothing at all.

What is wild about all this is that LLMs should be able to one shot this game. Zork has been around for decades. It has been posted in full on the internet in every iteration imaginable. Walkthroughs, speed run guides, hint books, and literally every single way to play the game has been discussed at length on the internet. And yet, LLMs, allegedly trained on the whole of the internet, fail completely to play a game which should be in it’s training data. That is a very interesting observation. And so that fateful night of Walter and me talking together at the Recurse Hub led to zork-bench, a Zork-based reasoning evaluation tool for Large Language Models.
zork-bench creates a harness for LLMs to play Zork. Zork is hosted using the same backend as zulip-zork. LLMs are given tools such as the ability to take notes or record a map. An important component of zork-bench is investigating planning. In order to make clever decisions that get points in the game, such as recovering the platinum brick, one needs to organize their inventory, figure out the loud room problem, and transport the platinum brick from the loud room, to the treasure case in the house. Thus choices and reasoning chains for the LLM across all these decisions can give insight into how these decisions are made. The reasoning/thinking text becomes less important for evaluation of the LLM itself, instead we can look at the actions it takes and decide if they are reasonable. If an LLM spends a lot of time walking back and forth between two rooms, that shows a lack of reasoning. But if the LLM puts the sword in the treasure case to lighten its load, goes to the loud room, solves the puzzle, grabs the platinum brick, and returns to the treasure case, this would represent a planned sequence of actions to solve a specific problem (recover the platinum brick).
Another component is what tools are helpful or harmful to LLM problem solving. In the below plot we can see what happens when LLMs are given no tools, the ability to make a map as they travel, and starting with a full map which was a common way for people to play the game when it came out. Below you can see that naavigating rooms, kimi-k2.5 is the only LLM that consistently performs the same no matter what tool they use. With no tools glm does rather well. It seems like when LLMs are able to create a map as they explore, they all do similiarly (middle plot) in exploring rooms. And when they are aware of the entire map there is a wide disparity. I think this is because of the token usage when you have to load in the entire map into the context window.

These above results from zork-bench already demonstrate that across 500 turns most LLMs never get past collecting a couple treasures and discovering less than half the rooms. Meanwhile they spend an enormous amount of tokens doing so. Below you can see that tokens linearly increase as previous turns are included, but what is surprising is how there are large spikes due to “thinking” and decision making. These are going to be explored in a future post.

zork-bench also is able to account for memorization. Sometimes LLMs do rely on their training data to solve puzzles in the game. Such as walking into the loud room and immediately issuing the command “echo”, which makes the loudness no longer effect the player, we can see that the LLM simply knew what to do and did not make any kind of reasoning plan. zork-bench solves this problem by including in the harness an ability to change all of the “facts” of the game. For example, the jewel encrusted egg that you find in the tree becomes a pot of gold found under a mushroom. A future post will explore LLM performance when they cannot rely on memorization.
A core component of evaluating zork-bench itself was doing a human eval. So I made the harness work for humans as well. I don’t recommend playing zork this way in particular, it requires a lot of setup, and that setup can be annoying if you are a windows user. But, if you are willing, I would love for you to play and send me a copy of your play through to add to the human eval data set. Already I had a bunch of Recursers like those mentioned before and others like Canna Wen and Jack Heard.
I organized an hour long event at Recurse Center, promised delicious donuts to everyone who came, and had them setup zork-bench on their laptops and play in human-eval model. The game logs all of their interactions using the same interface as LLMs but gives them a random label. The thing is Humans new to the game seem to do only so well. They spend a lot of turns, play the game, and figure some stuff out, but then after the hour of playing I gave them, they didn’t get further than any LLM. However, theyir memories of the game persist without continuously reducing the size of their context windows. Haha. Do humans have context windows? But the point is that LLMs, having humanity’s entire knowledge of Zork stored in their memory banks, are unable to outperform humans who had not played Zork before (except for Claude Sonnet, which Isha Bhand, creator of fomo.nyc and Zork aficionado, declared as evidence that AGI has been achieved).
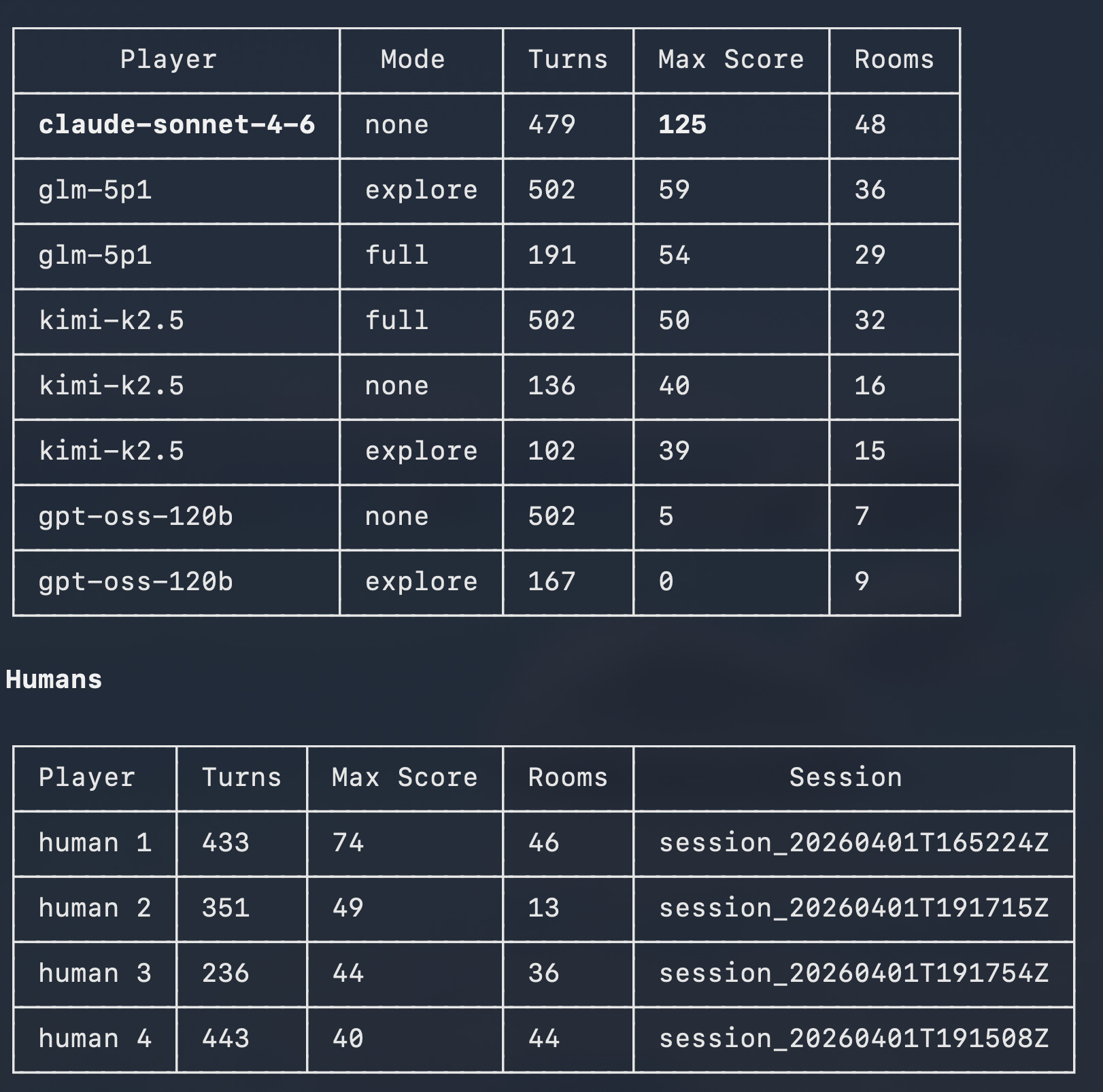
So what does this mean? I would say that it tells us that LLMs, at the very least, spend more energy reasoning about tasks that a game like Zork presents than humans do. And it is unclear that LLMs always understand what they are doing. For example, DeepSeek was never able to actually play the game, mostly hallucinating the game itself, and then making tool calls through the harness. The models all seem to start making similar decisions when they are given the ability to draw their own map. Sometimes models seem to get lost and lose the thread. More analysis is necessary!
If you find this work fun and want to support it, I would be happy to accept token contributions through my buy me a coffee link that you can find here:
Please sir can i have some more tokens
I think there is a lot here and we can expand the scope to include other text adventures. I am excited to see what other people think about this.
If you want to help out feel free to checkout the repo and make pull requests, issues, etc.! Together we will figure out what LLMs actually know through the power of Zork!
John Aiken has a PhD in physics, is editor-in-chief of low impact fruit, mayor of rainy-city.com, a Recurser, and passionate about saving the whales. Zork-bench is a passion project! I would love for you to contribute!